xxHash
v0.8.2
XXHASH é um algoritmo de hash extremamente rápido, processando nos limites de velocidade da RAM. O código é altamente portátil e produz hashes idênticos em todas as plataformas (Little / Big Endian). A biblioteca inclui os seguintes algoritmos:
v0.8.0 ): gera hashes de 64 ou 128 bits, usando aritmética vetorizada. A variante de 128 bits é chamada XXH128.Todas as variantes concluem com sucesso o suíte de teste SMHASHER que avalia a qualidade das funções de hash (colisão, dispersão e aleatoriedade). Também são fornecidos testes adicionais, que avaliam mais profundamente as propriedades de velocidade e colisão de hashes de 64 bits.
| Filial | Status |
|---|---|
| liberar |  |
| Dev |  |
O sistema de referência comparado usa uma CPU Intel i7-9700K e executa o Ubuntu X64 20.04. O programa de benchmark de código aberto é compilado com clang V10.0 usando o sinalizador -O3 .
| Nome de hash | Largura | Largura de banda (GB/s) | Velocidade de pequenos dados | Qualidade | Comentário |
|---|---|---|---|---|---|
| Xxh3 (SSE2) | 64 | 31,5 GB/S. | 133.1 | 10 | |
| XXH128 (SSE2) | 128 | 29,6 GB/S. | 118.1 | 10 | |
| Leitura seqüencial da RAM | N / D | 28,0 GB/S. | N / D | N / D | para referência |
| City64 | 64 | 22,0 GB/S. | 76.6 | 10 | |
| T1HA2 | 64 | 22,0 GB/S. | 99.0 | 9 | Colisões um pouco piores |
| City128 | 128 | 21,7 GB/S. | 57.7 | 10 | |
| Xxh64 | 64 | 19.4 GB/S. | 71.0 | 10 | |
| Spookyhash | 64 | 19.3 GB/S. | 53.2 | 10 | |
| Mamãe | 64 | 18,0 GB/S. | 67.0 | 9 | Colisões um pouco piores |
| Xxh32 | 32 | 9,7 GB/S. | 71.9 | 10 | |
| City32 | 32 | 9,1 GB/S. | 66.0 | 10 | |
| Murmur3 | 32 | 3,9 GB/S. | 56.1 | 10 | |
| Sifash | 64 | 3,0 GB/S. | 43.2 | 10 | |
| FNV64 | 64 | 1,2 GB/S. | 62.7 | 5 | Propriedades de Avalanche ruins |
| Blake2 | 256 | 1,1 GB/S. | 5.1 | 10 | Criptográfico |
| SHA1 | 160 | 0,8 GB/s | 5.6 | 10 | Criptográfico, mas quebrado |
| MD5 | 128 | 0,6 GB/s | 7.8 | 10 | Criptográfico, mas quebrado |
NOTA 1: A velocidade de dados pequenos é uma avaliação aproximada da eficiência do algoritmo em pequenos dados. Para uma análise mais detalhada, consulte o próximo parágrafo.
Nota 2: Alguns algoritmos aparecem mais rápido que a velocidade da RAM . Nesse caso, eles só podem atingir seu potencial de velocidade máxima quando a entrada já está em cache da CPU (L3 ou melhor). Caso contrário, eles maximizam o limite de velocidade da RAM.
O desempenho em dados grandes é apenas uma parte da imagem. O hashing também é muito útil em construções como mesas de hash e filtros de flor. Nesses casos de uso, é frequente hash muitos dados pequenos (começando em alguns bytes). O desempenho do algoritmo pode ser muito diferente para esses cenários, uma vez que partes do algoritmo, como inicialização ou finalização, se tornam custos fixo. O impacto da ramo incorretamente também se torna muito mais presente.
XXH3 foi projetado para excelente desempenho em entradas longas e pequenas, que podem ser observadas no gráfico a seguir:
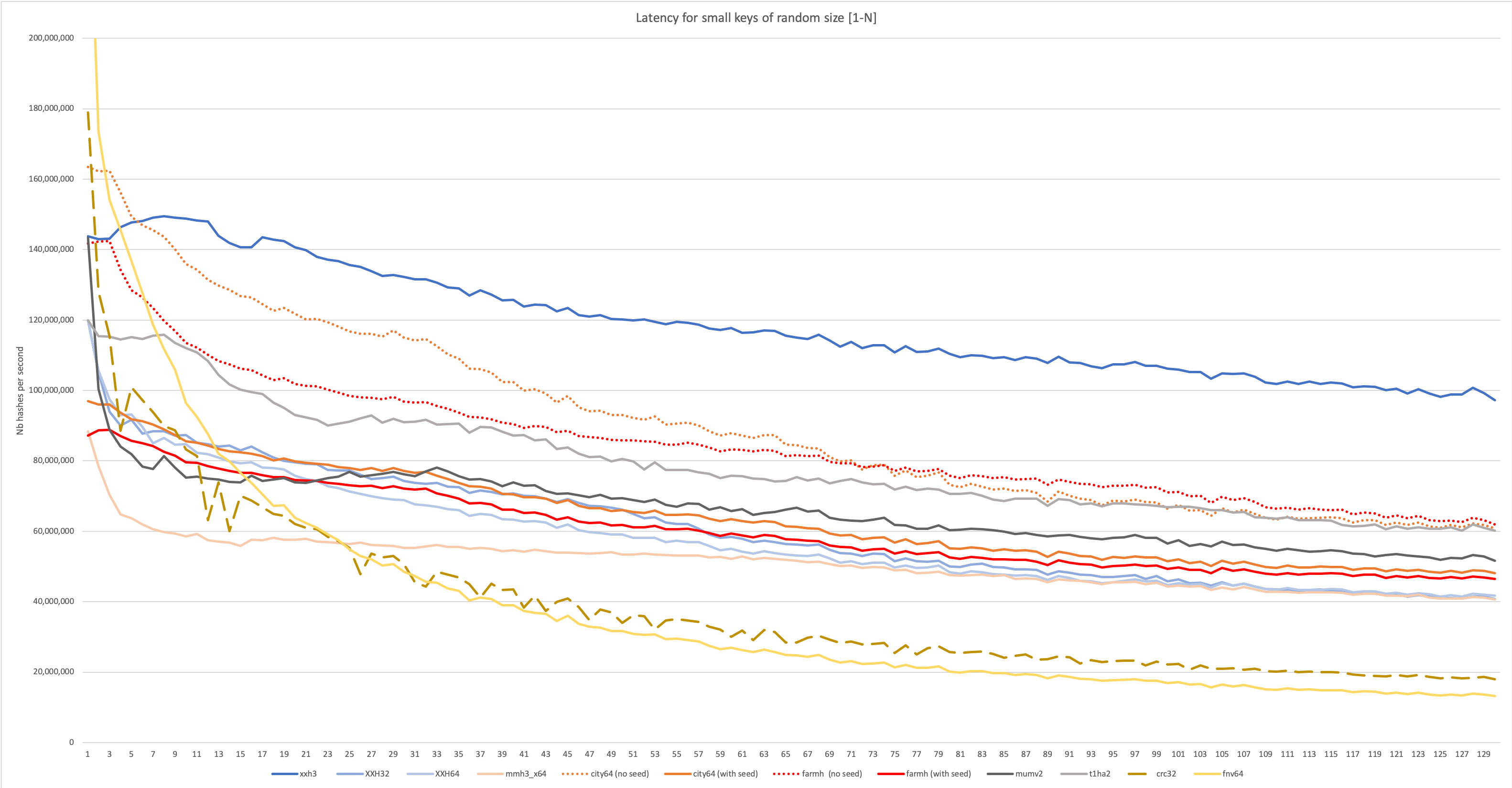
Para uma análise mais detalhada, visite o Wiki: https://github.com/cyan4973/xxhash/wiki/performance-comparison#benchmarks-concentrating-on-small-data-
A velocidade não é a única propriedade que importa. Os valores de hash produzidos devem respeitar excelentes propriedades de dispersão e aleatoriedade, para que qualquer subseção possa ser usada para espalhar ao máximo uma tabela ou índice, além de reduzir a quantidade de colisões para o nível teórico mínimo, após o paradoxo do aniversário.
xxHash foi testado com a excelente suíte de teste SMHasher da Austin Appleby e passa todos os testes, garantindo níveis razoáveis de qualidade. Ele também passa testes estendidos de garfos mais recentes do SMHASHER, com cenários e condições adicionais.
Finalmente, o XXHASH fornece seu próprio testador de colisão maciça, capaz de gerar e comparar bilhões de hashes para testar os limites dos algoritmos de hash de 64 bits. Nesta frente também, o XXHASH apresenta bons resultados, de acordo com o paradoxo do aniversário. Uma análise mais detalhada está documentada no wiki.
As macros a seguir podem ser definidas no momento da compilação para modificar o comportamento de libxxhash . Eles geralmente são desativados por padrão.
XXH_INLINE_ALL : faça todas as funções inline , a implementação é diretamente incluída no xxhash.h . As funções inline são benéficas para a velocidade, principalmente para pequenas chaves. É extremamente eficaz quando o comprimento de Key é expresso como uma constante de tempo de compilação , com melhorias de desempenho observadas na faixa de +200%. Veja este artigo para obter detalhes.XXH_PRIVATE_API : o mesmo resultado que XXH_INLINE_ALL . Ainda disponível para suporte herdado. O nome sublinha que XXH_* nomes de símbolos não serão exportados.XXH_STATIC_LINKING_ONLY : dá acesso à declaração interna do estado, necessária para a alocação estática. Incompatível com a ligação dinâmica, devido aos riscos de alterações de ABI.XXH_NAMESPACE : prefixos todos os símbolos com o valor de XXH_NAMESPACE . Essa macro pode usar apenas o conjunto de caracteres compiláveis. Útil para evitar colisões de nomeação de símbolos, no caso de múltiplas inclusões do código -fonte do XXHASH. Os aplicativos do cliente ainda usam os nomes de funções regulares, pois os símbolos são traduzidos automaticamente através do xxhash.h .XXH_FORCE_ALIGN_CHECK : use um caminho de leitura direta mais rápido quando a entrada estiver alinhada. Esta opção pode resultar em melhoria dramática de desempenho nas arquiteturas não conseguirem carregar memória de endereços inalignados quando a entrada no hash está alinhada nos limites de 32 ou 64 bits. É (ligeiramente) prejudicial na plataforma com bom desempenho de acesso à memória desalinhado (a mesma instrução para acessos alinhados e inalignados). Esta opção é desativada automaticamente em x86 , x64 e aarch64 e ativada em todas as outras plataformas.XXH_FORCE_MEMORY_ACCESS : o método padrão 0 usa uma notação portátil memcpy() . O Método 1 usa um atributo packed específico do GCC, que pode fornecer melhor desempenho para alguns alvos. O método 2 força as leituras desalinhadas, o que não é compatível com padrão, mas às vezes pode ser a única maneira de extrair melhor desempenho de leitura. O Método 3 usa uma operação de by-shift, que é melhor para compiladores antigos que não são sistemas em linha memcpy() ou big-endian sem uma instrução byteswap.XXH_CPU_LITTLE_ENDIAN : Por padrão, o Endianness é determinado por um teste de tempo de execução resolvido no tempo de compilação. Se, por algum motivo, o compilador não puder simplificar o teste de tempo de execução, poderá custar desempenho. É possível pular a detecção automática e simplesmente afirmar que a arquitetura é pouco endiana, definindo essa macro como 1. Definindo-a para 0 estados big-endianos.XXH_ENABLE_AUTOVECTORIZE : a vetorização automática pode ser acionada para XXH32 e XXH64, dependendo dos recursos do vetor da CPU e da versão do compilador. NOTA: A vetorização automática tende a ser desencadeada mais facilmente com versões recentes do clang . Para XXH32, SSE4.1 ou equivalente (neon) é suficiente, enquanto XXH64 requer Avx512. Infelizmente, a auto-vetorização geralmente é prejudicial ao desempenho XXH. Por esse motivo, o código-fonte xxhash tenta evitar a vetorização automática por padrão. Dito isto, os sistemas evoluem, e essa conclusão não está chegando. Por exemplo, foi relatado que as CPUs Zen4 recentes têm maior probabilidade de melhorar o desempenho com a vetorização. Portanto, se você preferir ou desejar testar o código vetorizado, pode ativar esse sinalizador: ele removerá o código de proteção sem vetorização, tornando-o mais provável para que XXH32 e XXH64 sejam auto-vetorizados.XXH32_ENDJMP : Switch Finalization Finalization de XXH32 por um único salto. Isso geralmente é indesejável para o desempenho, especialmente quando hash de tamanhos aleatórios. Mas, dependendo da arquitetura e do compilador exatos, um salto pode fornecer um desempenho um pouco melhor em pequenas entradas. Desativado por padrão.XXH_IMPORT : MSVC específico: deve ser definido apenas para vinculação dinâmica, pois evita erros de ligação.XXH_NO_STDLIB : Desative a invocação de funções <stdlib.h> , principalmente malloc() e free() . O XXH*_createState() do libxxhash sempre falhará e retornará NULL . Mas hash de um tiro (como XXH32() ) ou streaming usando estados alocados estaticamente ainda funcionam conforme o esperado. Esse sinalizador de construção é útil para ambientes incorporados sem alocação dinâmica.XXH_DEBUGLEVEL : Quando definido como qualquer valor> = 1, Ativa as instruções assert() . Isso (ligeiramente) diminui a execução, mas pode ajudar a encontrar bugs durante as sessões de depuração. XXH_NO_XXH3 : remove os símbolos relacionados a XXH3 (64 e 128 bits) do binário gerado. XXH3 é de longe o maior colaborador do tamanho libxxhash , por isso é útil reduzir o tamanho binário para aplicações que não empregam XXH3 .XXH_NO_LONG_LONG : Remove a compilação de algoritmos que dependem de tipos long long 64 bits que incluem XXH3 e XXH64 . Somente XXH32 será compilado. Útil para metas (arquiteturas e compiladores) sem suporte de 64 bits.XXH_NO_STREAM : desativa a API de streaming, limitando a biblioteca a apenas variantes de tiro único.XXH_NO_INLINE_HINTS : por padrão, xxhash usa __attribute__((always_inline)) e __forceinline para melhorar o desempenho ao custo do tamanho do código. Definir essa macro a 1 marcará todas as funções internas como static , permitindo que o compilador decida se deve embrulhar uma função ou não. Isso é muito útil ao otimizar o menor tamanho binário e é definido automaticamente ao compilar com -O0 , -Os , -Oz ou -fno-inline no GCC e CLANG. Isso também pode aumentar o desempenho, dependendo do compilador e da arquitetura.XXH_SIZE_OPT : 0 : Padrão, otimize para a velocidade 1 : Padrão para -Os e -Oz : desativa alguns hacks de velocidade para otimização de tamanho 2 : torna o código o menor possível, o desempenho pode chorar XXH_VECTOR : Selecione manualmente um conjunto de instruções vetoriais (padrão: selecionado automaticamente no horário de compilação). Os conjuntos de instruções disponíveis são XXH_SCALAR , XXH_SSE2 , XXH_AVX2 , XXH_AVX512 , XXH_NEON e XXH_VSX . O compilador pode exigir sinalizadores adicionais para garantir o suporte adequado (por exemplo, gcc no X86_64 requer -mavx2 para AVX2 ou -mavx512f para AVX512 ).XXH_PREFETCH_DIST : selecione a distância de pré -busca. Para adaptação quase em metal a plataformas de hardware específicas. XXH3 SOMENTE.XXH_NO_PREFETCH : Desative a pré -busca. Algumas plataformas ou situações podem ter um desempenho melhor sem a pré -busca. XXH3 SOMENTE. Ao compilar a interface da linha de comando xxhsum usando make , as seguintes variáveis de ambiente também podem ser definidas:
DISPATCH=1 : Use xxh_x86dispatch.c , para selecionar automaticamente entre as instruções scalar , sse2 , avx2 ou avx512 definidas no tempo de execução , dependendo do host local. Esta opção é válida apenas para sistemas x86 / x64 .XXH_1ST_SPEED_TARGET : Selecione um alvo de velocidade inicial, expresso em MB/S, para o primeiro teste de velocidade no modo de referência. O benchmark ajustará o alvo nas iterações subsequentes, mas o primeiro teste é feito "cegamente", visando essa velocidade. Atualmente, definido de forma conservadora como 10 MB/s, para suportar plataformas muito lentas (emuladas).NODE_JS=1 : Ao compilar xxhsum para node.js com o emscriptten, isso vincula a biblioteca NODERAWFS para acesso irrestrito ao sistema de arquivos e patches isatty para fazer o utilitário de linha de comando detectar corretamente o terminal. Isso torna o binário específico para Node.JS.Você pode baixar e instalar xxhash usando o gerenciador de dependência vcpkg:
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install xxhash
A porta xxhash no VCPKG é mantida atualizada pelos membros da equipe da Microsoft e pelos colaboradores da comunidade. Se a versão estiver desatualizada, crie uma solicitação de problema ou puxe no repositório VCPKG.
O exemplo mais simples chama a variante xxhash de 64 bits como uma função de um tiro que gera um valor de hash de um único buffer e chamado de um programa C/C ++:
#include "xxhash.h"
(...)
XXH64_hash_t hash = XXH64 ( buffer , size , seed );
}A variante de streaming está mais envolvida, mas torna possível fornecer dados de forma incremental:
#include "stdlib.h" /* abort() */
#include "xxhash.h"
XXH64_hash_t calcul_hash_streaming ( FileHandler fh )
{
/* create a hash state */
XXH64_state_t * const state = XXH64_createState ();
if ( state == NULL ) abort ();
size_t const bufferSize = SOME_SIZE ;
void * const buffer = malloc ( bufferSize );
if ( buffer == NULL ) abort ();
/* Initialize state with selected seed */
XXH64_hash_t const seed = 0 ; /* or any other value */
if ( XXH64_reset ( state , seed ) == XXH_ERROR ) abort ();
/* Feed the state with input data, any size, any number of times */
(...)
while ( /* some data left */ ) {
size_t const length = get_more_data ( buffer , bufferSize , fh );
if ( XXH64_update ( state , buffer , length ) == XXH_ERROR ) abort ();
(...)
}
(...)
/* Produce the final hash value */
XXH64_hash_t const hash = XXH64_digest ( state );
/* State could be re-used; but in this example, it is simply freed */
free ( buffer );
XXH64_freeState ( state );
return hash ;
} Os arquivos da biblioteca xxhash.c e xxhash.h são licenciados em BSD. O utilitário xxhsum é licenciado GPL.
Além da versão de referência C, o XXHASH também está disponível em várias linguagens de programação diferentes, graças a ótimos colaboradores. Eles estão listados aqui.
Muitas distribuições agrupam um gerenciador de pacotes que permite uma instalação fácil de xxhash como uma biblioteca libxxhash e interface da linha de comando xxhsum .
xxhsum -cXXH64XXH128 Hussey, também XXH3

