Verdant_Search
1.0.0
目前为了考虑后端的负载量,将搜索引擎的后端改成了flask
但是其临时存储结构CubeQL用了fastapi
官网: http://115.29.198.35
作者邮箱:[email protected]
用于青荇搜索的临时存储结构,实现类似redis的功能,同时还能通过布隆过滤器模块来过滤已经爬虫过的网址,用作去重
预计使用vlang进行速度优化
对分布式爬虫爬取的statuscode出现404仍然收录的问题进行优化
增加了搜索结果网页排序和权值增加(重定向)
Mozilla/5.0 (compatible;VerdantSpider/1.0)
增加一些必要的搜索引擎权值动态更新的功能(done)
实现中文->拼音的模糊搜索(需要建立新的映射表)
实现分割数据库存储
转换为postgresql(done)
统计每次搜索的细节,方便总结(done)
添加cubeql实现的分布式锁
实现搜单词保存在云端,服务器不需要多次爬虫
实现点击音量图标后再爬虫音频
实现vlang代替大部分python功能,优化性能
实现每日搜索热点
实现各种搜索引擎的智能汇总
用容器管理环境,实现一键部署和一键运行
对搜索的每个单条索引进行寿命周期,过一段阵子就会降低权值(需要新的程序来维护)(done)
实现simhash,实现csdn等博客类网站的去重
支持多样化搜索,更人性化的筛选器
postgresql 参考版本为11.10
python >= 3.6
flask
fastapi==0.54.1
psycopg2
starlette
requests_html
jieba
demjson
bloomfilter_live
gevent
├─.vscode
├─docs
├─resources
│ ├─config
│ ├─CubeQL
│ │ └─__pycache__
│ ├─lib
│ ├─Spider
│ │ └─__pycache __
│ ├─static
│ │ ├─css
│ │ ├─img
│ │ └─music
│ ├─templates
│ └─__pycache __
└─sql
docs : 定期存放文档
resources :源码存放目录
config:配置文件json的备用存放目录(真正调用在根目录,目前尚未完成对目录结构的优化
CubeQL:存放CubeQL相关源码的目录
Spider:存放爬虫的目录
lib:存放requirements
static:存放静态文件
templates:存放模板文件
sql:存放备用的建表sql文件
backend.py - 搜素引擎后端文件
config.json - 配置文件,只有在运行代码的根目录的json文件才生效
可能environment里面有一些库没有提到,反正有什么装什么
修改config.json的数据库账号密码和ip
确保postgresql是开着的
在CubeQL目录下运行
uvicorn CubeQL:app --port 1278
在resources目录下运行
python backend.py
在spider目录下运行(不运行也可以打开青荇搜索)
python CDS-Distributed.py
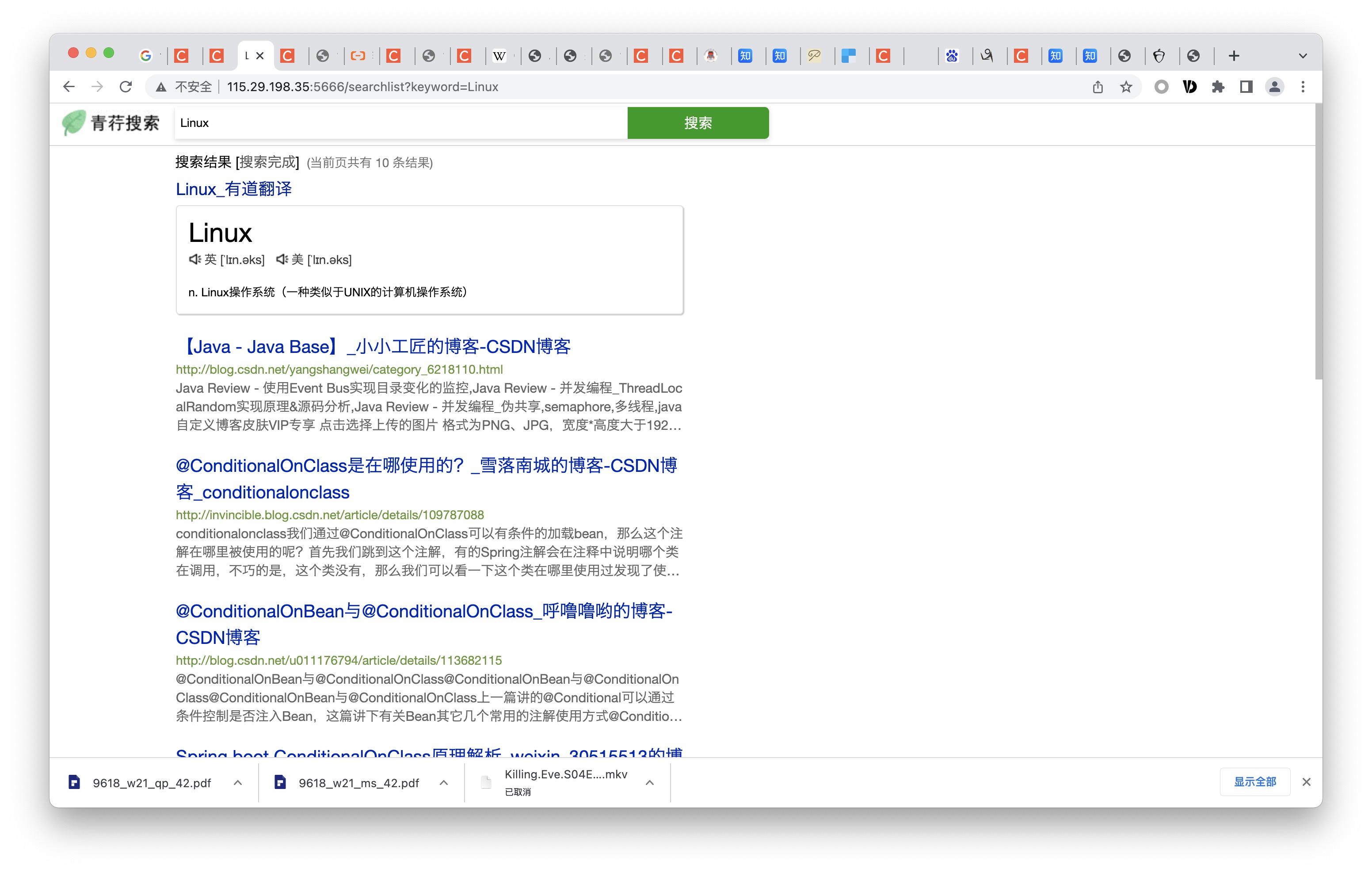
通过访问/trend即可,可以统计出所有关键词的搜索频率
编写插件系统相当简单,插件系统本质上就是有一个前端框架在搜索结果下方,可以通过根目录的extensions.json(后面会放到config文件夹)进行对插件的注册
然后在extensions的文件夹里面新建一个index.html和package.json, json可参考huyaoiBlog的
package.json


