Verdant_Search
1.0.0
現在、バックエンドの負荷を検討するために、検索エンジンのバックエンドがフラスコに変更されました
ただし、一時的な保管構造CubeQLはFastapiを使用しています
公式ウェブサイト:http://115.29.198.35著者のメール:[email protected]
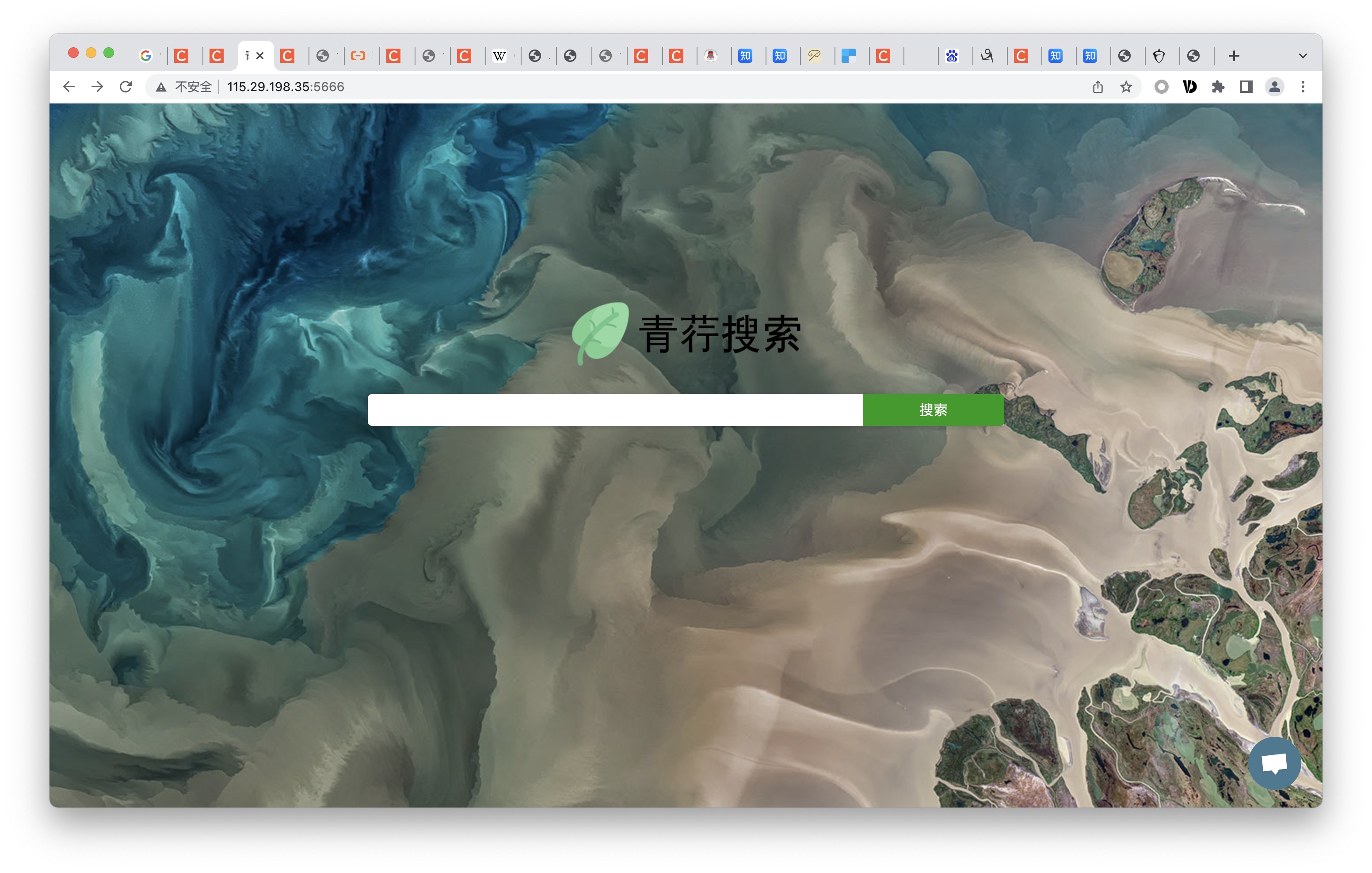
赤面検索のための一時的なストレージ構造、Redisのような機能を実装し、Bloom Filterモジュールを介してCrawler URLをフィルタリングし、重複排除として使用することもできます
Vlangを使用して速度最適化が予想されます
分散クローラーによるステータスコードクロールにまだ404の包含の問題を最適化します。
Mozilla/5.0(互換; verdantspider/1.0)
必要な検索エンジンの重量動的更新機能(完了)を追加する
中国語のファジー検索を実装 - > pinyin(新しいマッピングテーブルを作成する必要があります)
分割データベースストレージを実装します
postgresqlに変換する(完了)
統計各検索の詳細は簡単な要約(完了)
CubeQLによって実装された分散ロックを追加します
クラウドに保存するために検索ワードを実装すると、サーバーは複数のクロールを必要としません
ボリュームアイコンをクリックした後、オーディオを実装します
ほとんどのPython関数の代わりにVlangを実装し、パフォーマンスを最適化する
毎日の検索ホットスポットを実現します
さまざまな検索エンジンのインテリジェントな概要を実装します
コンテナを使用して環境を管理して、ワンクリックの展開とワンクリック操作を実現します
検索の単一インデックスごとにライフサイクルが行われ、重量はしばらくすると減少します(新しいプログラムは維持する必要があります)(完了)
simhashを実装し、CSDNなどのブログWebサイトの重複排除を実装します
多様化された検索とよりユーザーフレンドリーなフィルターをサポートします
PostgreSQL参照バージョンは11.10です
Python> = 3.6
フラスコ
Fastapi == 0.54.1
psycopg2
スターレット
requests_html
ジーバ
デミソン
bloomfilter_live
Gevent
├。vscode
├docs
├rusources
│├├config
│cubeql
│└└。__pycache__
│││。lib
│├├スパイダー
│└│。__ピカチェ__
││├├。CSS
││├├イミー
husic
│├。Templates
│└└。__パイカッチ__
└cl
ドキュメント:定期的にドキュメントを保存します
リソース:ソースコードストレージディレクトリ
構成:構成ファイルJSONの代替ディレクトリ(ルートディレクトリで実際に呼び出され、ディレクトリ構造の最適化はまだ完了していません
CUBEQL:CubeQL関連のソースコードを保存するディレクトリ
スパイダー:クローラーを保存するためのディレクトリ
LIB:要件を保存します
静的:静的ファイルを保存します
テンプレート:テンプレートファイルを保存します
SQL:代替テーブル作成SQLファイルを保存します
backend.py-エンジンバックエンドファイルを検索します
config.json-構成ファイル、コードが実行されているルートディレクトリ内のjsonファイルのみが有効になります
環境には言及されていないライブラリがいくつかあるかもしれませんが、とにかく、インストールするために何がありますか
config.jsonのデータベースアカウントパスワードとIPを変更します
PostgreSQLが開いていることを確認してください
CubeQLディレクトリで実行します
uvicorn cubeql:app-ポート1278
リソースディレクトリで実行します
python backend.py
Spiderディレクトリで実行します(実行しない場合は緑の検索を開くことができます)
python cds-distributed.py
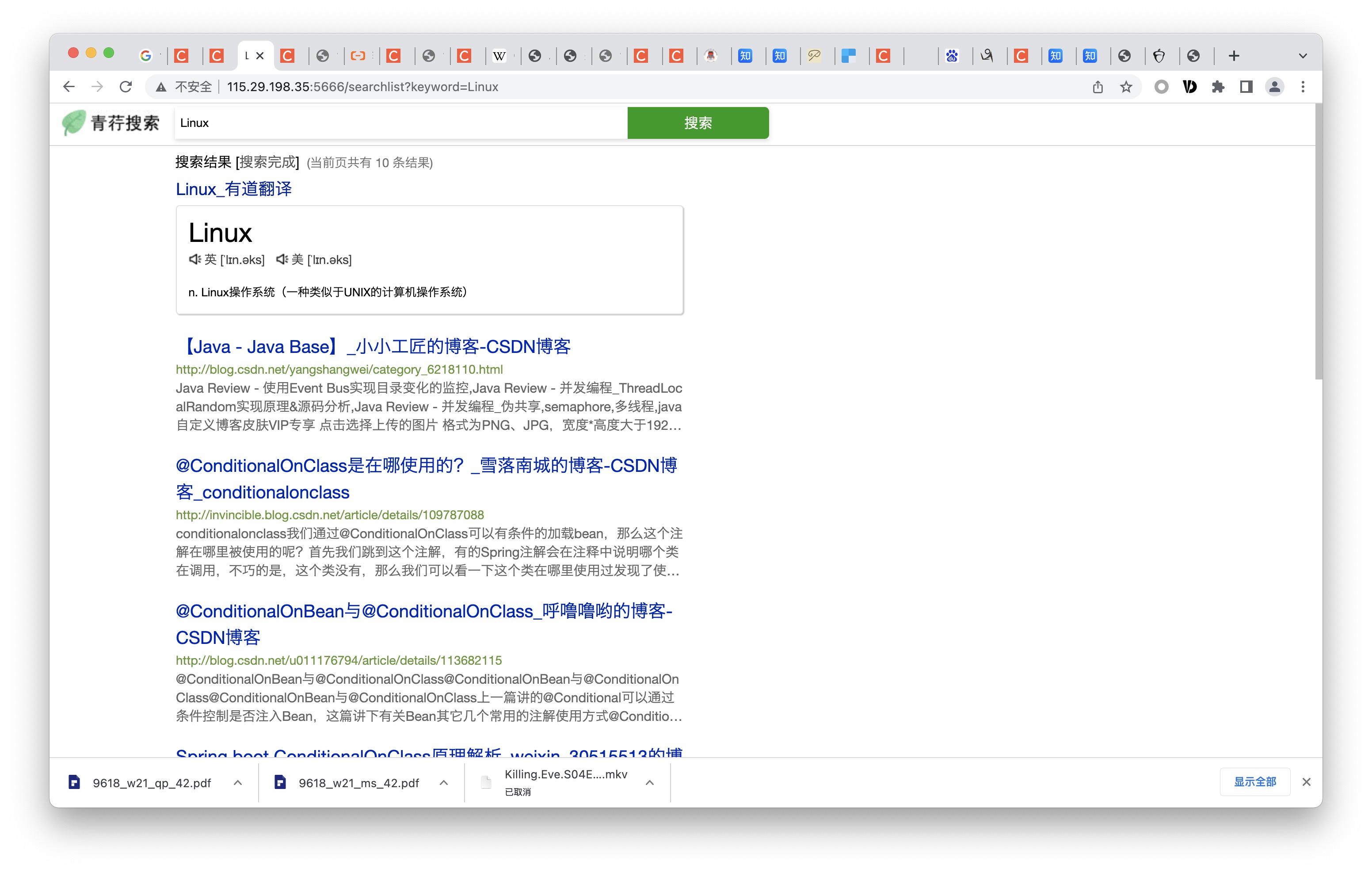
アクセス /トレンドでは、すべてのキーワードの検索頻度をカウントできます
プラグインシステムの作成は、基本的に、拡張機能の下にプラグインを登録できます。
次に、extensionsフォルダーに新しいindex.htmlとpackage.jsonを作成します
package.json


