Verdant_Search
1.0.0
Currently, in order to consider the load of the backend, the backend of the search engine has been changed to flask
However, its temporary storage structure CubeQL uses fastapi
Official website: http://115.29.198.35 Author's email: [email protected]
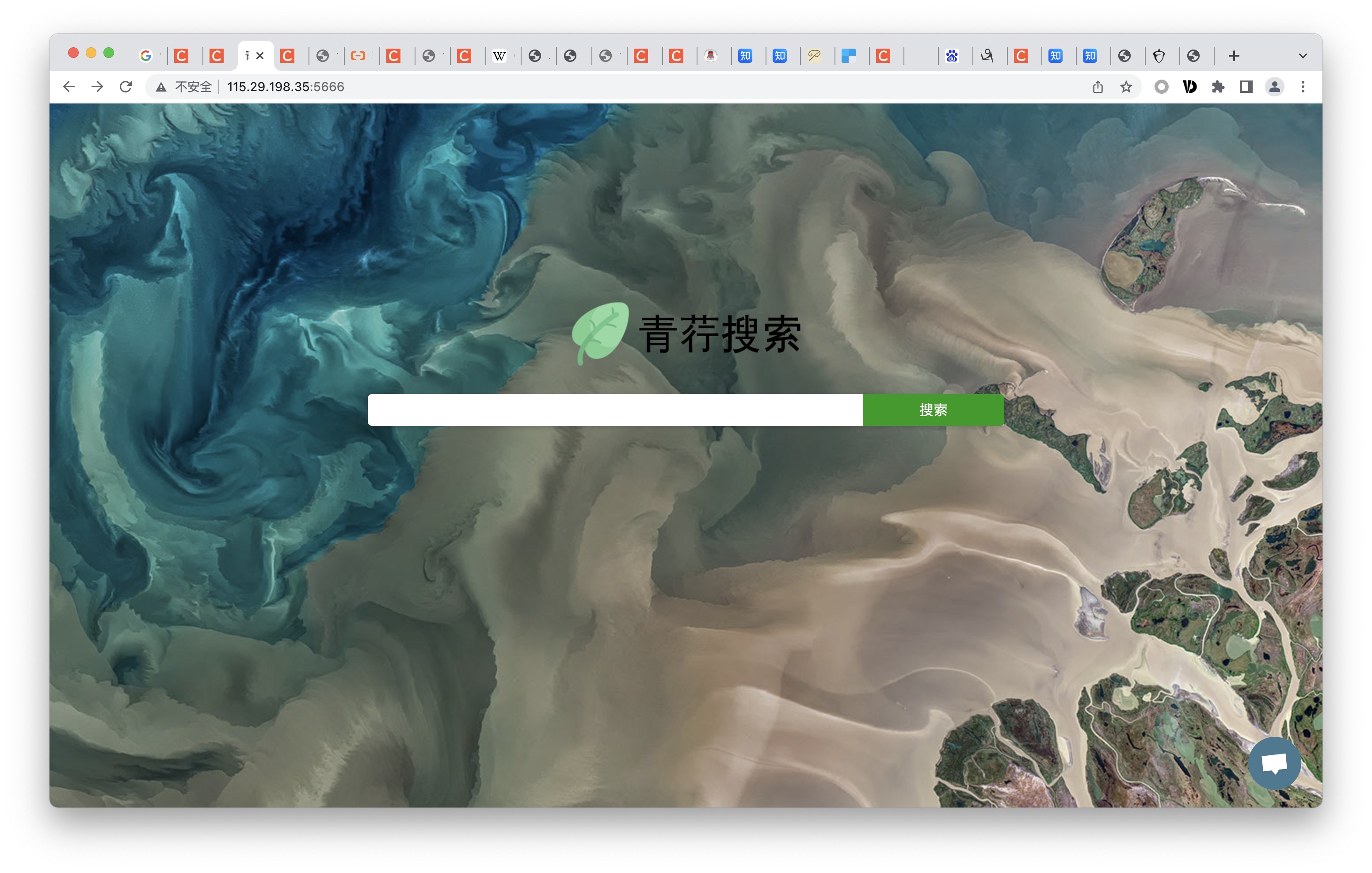
A temporary storage structure for blush search, implementing redis-like functions, and can also filter crawler URLs through the Bloom filter module, and use it as deduplication
Speed optimization is expected using vlang
Optimize the problem of 404 still inclusion in statuscode crawling by distributed crawlers, which increases search results web page sorting and weight increase (redirection)
Mozilla/5.0 (compatible; VerdantSpider/1.0)
Add some necessary search engine weight dynamic update function (done)
Implement fuzzy search of Chinese->Pinyin (need to create a new mapping table)
Implement split database storage
Convert to postgresql(done)
Statistics the details of each search for easy summary (done)
Add distributed locks implemented by cubeql
Implement search words to save in the cloud, and the server does not require multiple crawlings
Implement the audio after clicking the volume icon
Implement vlang instead of most python functions and optimize performance
Realize daily search hot spots
Implement intelligent summary of various search engines
Use containers to manage the environment to realize one-click deployment and one-click operation
Life cycles for each single index of the search, and the weight will be reduced after a while (new programs are required to maintain) (done)
Implement simhash and implement deduplication of blog websites such as csdn
Supports diversified search and more user-friendly filters
Postgresql reference version is 11.10
python >= 3.6
flask
fastapi==0.54.1
psycopg2
starlette
requests_html
jieba
demjson
bloomfilter_live
gevent
├─.vscode
├─docs
├─resources
│ ├─config
│ ├─CubeQL
│ └─__pycache__
│ ├─lib
│ ├─Spider
│ └─__pycache __ │ ├─static
│ │ ├─css
│ │ ├─img
│ └─music
│ ├─templates
│ └─__pycache __
└─sql
docs: Regularly store documents
resources: source code storage directory
config: The alternate directory for configuration file json (really called in the root directory, and the optimization of the directory structure has not been completed yet
CubeQL: a directory that stores CubeQL-related source code
Spider: directory for storing crawlers
lib: store requirements
static: store static files
templates: store template files
sql: store alternate table creation sql files
backend.py - Search engine backend file
config.json - configuration file, only the json file in the root directory where the code is running takes effect
Maybe there are some libraries in the environment that are not mentioned, but anyway, what are there to install
Modify the database account password and ip of config.json
Make sure postgresql is open
Run in the CubeQL directory
uvicorn CubeQL:app --port 1278
Run in resources directory
python backend.py
Run it in the spider directory (you can open the green search if you don’t run it)
python CDS-Distributed.py
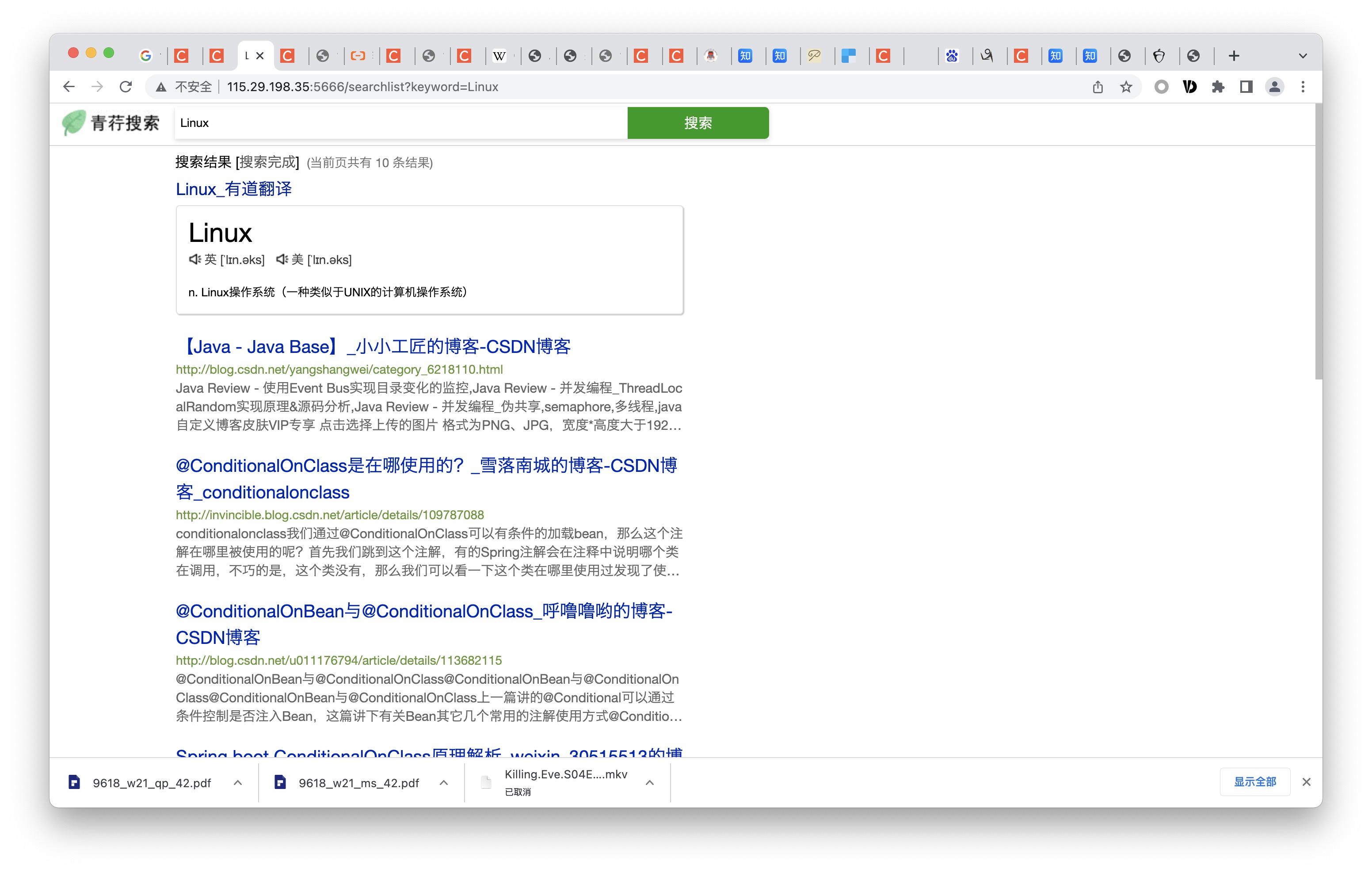
By accessing /trend, you can count the search frequency of all keywords
Writing a plug-in system is quite simple. The plug-in system essentially has a front-end framework below the search results. You can register the plug-in through the extensions.json in the root directory (which will be placed in the config folder later).
Then create a new index.html and package.json in the extensions folder. For json, you can refer to huyaoiBlog
package.json


