Verdant_Search
1.0.0
Um die Last des Backends zu berücksichtigen, wurde das Backend der Suchmaschine in Flask geändert
Die temporäre Speicherstruktur CUbeQL verwendet jedoch Fastapi
Offizielle Website: http://115.29.198.35 Autor E -Mail: [email protected]
Eine temporäre Speicherstruktur für die Suche nach Erröten, die Implementierung von Redis-ähnlichen Funktionen und kann auch Crawler-URLs über das Bloom-Filtermodul filtern und als Deduplizierung verwenden
Die Geschwindigkeitsoptimierung wird mit VLANG erwartet
Optimieren Sie das Problem von 404 noch Einbeziehung in den Statuscode -Crawling durch verteilte Crawler, wodurch die Sortierung und Gewichtszunahme der Suchergebnisse erhöht wird (Umleitung)
Mozilla/5.0 (kompatibel; Verdantspider/1.0)
Fügen Sie einige notwendige Suchmaschinengewichtsfunktionen Dynamic Update hinzu (erledigt).
Implementieren Sie die Fuzzy-Suche nach Chinesen-> Pinyin (müssen eine neue Mapping-Tabelle erstellen)
Implementieren Sie Split -Datenbankspeicher
In postgresql (fertig) konvertieren
Statistiken Die Details jeder Suche nach einfacher Zusammenfassung (erledigt)
Fügen Sie verteilte Sperren hinzu, die von Cubeql implementiert sind
Implementieren Sie Suchwörter, die in der Cloud speichern können, und der Server benötigt nicht mehrere Crawlings
Implementieren Sie das Audio nach dem Klicken auf das Volumensymbol
Implementieren Sie Vlang anstelle der meisten Python -Funktionen und optimieren Sie die Leistung
Tägliche Such -Hotspots realisieren
Implementieren Sie intelligente Zusammenfassung verschiedener Suchmaschinen
Verwenden Sie Container, um die Umgebung zu verwalten, um eine Einsatz- und One-Click-Operation mit einem Klick zu realisieren
Lebenszyklen für jeden einzelnen Index der Suche und das Gewicht werden nach einer Weile reduziert (neue Programme sind erforderlich) (erledigt)
Implementieren Sie Simhash und implementieren Sie die Deduplizierung von Blog -Websites wie CSDN
Unterstützt eine diversifizierte Suche und benutzerfreundlichere Filter
PostgreSQL Reference -Version ist 11.10
Python> = 3,6
Flasche
fastapi == 0,54,1
psycopg2
Starlette
requests_html
Jieba
Demjson
BloomFilter_Live
Gevent
├─.VSCODE
├─docs
├─ Resources
│ ├─config
│ ├─Cubeql
│ └─__Pycache__
│ ├─lib
│ ├├spider
│ └─__Pycache __ │ ├ ├ ├ºStatic
│ │ ├─css
│ │ ├─img
│ └ºMusic
│ ├─ Templates
│ └─__Pycache __
└─sql
Dokumente: Speichern regelmäßig Dokumente
Ressourcen: Quellcode -Speicherverzeichnis
Konfiguration: Das alternative Verzeichnis für die Konfigurationsdatei JSON (im Stammverzeichnis wirklich aufgerufen und die Optimierung der Verzeichnisstruktur wurde noch nicht abgeschlossen
CHOBEQL: Ein Verzeichnis, in dem der CHOBEQL-bezogene Quellcode gespeichert ist
Spinnen: Verzeichnis für die Aufbewahrung von Crawlers
Lib: Speicheranforderungen
Statisch: Statische Dateien speichern
Vorlagen: Vorlagendateien speichern
SQL: Store Alternative Table Creation SQL -Dateien
Backend.py - Suchmaschinen -Backend -Datei
config.json - Konfigurationsdatei, nur die JSON -Datei im Stammverzeichnis, in dem der Code ausgeführt wird
Vielleicht gibt es einige Bibliotheken in der Umgebung, die nicht erwähnt werden, aber was auch immer zu installieren sind
Ändern Sie das Datenbankkennwort und das IP von config.json
Stellen Sie sicher, dass Postgresql offen ist
Im Cubeql -Verzeichnis laufen
Uvicorn CHOMEQL: APP -PORT 1278
Im Ressourcenverzeichnis ausführen
Python Backend.py
Führen Sie es im Spider -Verzeichnis aus (Sie können die grüne Suche öffnen, wenn Sie sie nicht ausführen).
Python CDS-verteilt.py
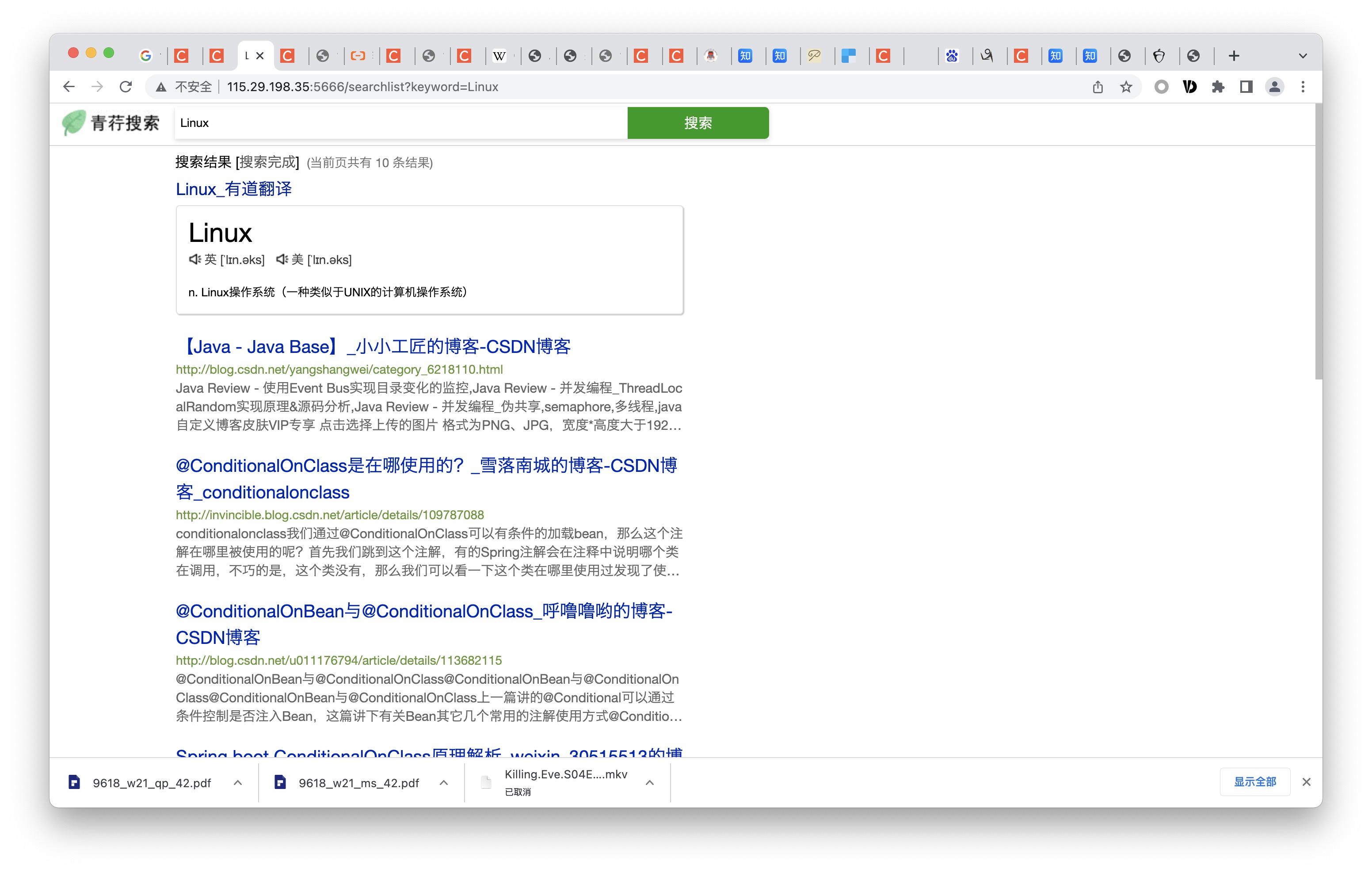
Durch den Zugriff /Trend können Sie die Suchfrequenz aller Schlüsselwörter zählen
Das Schreiben eines Plug-in-Systems ist recht einfach.
Erstellen Sie dann einen neuen Index.html und Paket.json im Erweiterungsordner.
package.json


