nboost
1.0.0
?我们正在为虚拟助手小部件寻找Beta测试人员。如果您有兴趣在网站上使用它,请与我们联系。
亮点•概述•基准•安装•入门•Kubernetes•文档•教程•贡献•发行说明•博客
⚡nboost是一个可扩展的,搜索引人入胜的平台,用于开发和部署最先进的模型,以提高搜索结果的相关性。

NBOST利用固定模型生产特定领域的神经搜索引擎。该平台还可以改善需要排名输入的其他下游任务,例如问答。
与我们联系以请求特定域的模型或留下反馈
NBoost的工作流相对简单。以上面的图形为单位,并想象在这种情况下的服务器是Elasticsearch。

在常规的搜索请求中,用户向Elasticsearch发送查询并恢复结果。

在NBOOST搜索请求中,用户向模型发送查询。然后,该模型索取了Elasticsearch的结果,并选择了最佳的返回用户的结果。
?请注意,我们正在评估与对训练的构建的模型相比(MS MARCO vs TREC-CAR),这表明这些模型对许多其他现实世界搜索问题的推广性。
| 微调模型 | 依赖性 | 评估集 | 搜索提升[1] | GPU上的速度 |
|---|---|---|---|---|
nboost/pt-tinybert-msmarco (默认) | Bing查询 | +45% (0.26 vs 0.18) | 〜50ms/查询 | |
nboost/pt-bert-base-uncased-msmarco | Bing查询 | +62% (0.29 vs 0.18) | 〜300毫秒/查询 | |
nboost/pt-bert-large-msmarco | Bing查询 | +77% (0.32 vs 0.18) | - | |
nboost/pt-biobert-base-msmarco | 生物 | +66% (0.17 vs 0.10) | 〜300毫秒/查询 |
在这里复制的说明。
[1] MRR与BM25相比,BM25是Elasticsearch的默认值。重读前50名。
[2] https://github.com/nyu-dl/dl4marco-bert
例如,将这些微调模型之一与NBOOST一起运行,以运行nboost --model_dir bert-base-uncased-msmarco ,它将自动下载和缓存。
使用预训练的语言理解模型,与仅文本搜索相比,您可以将搜索相关指标提高近2倍,而几乎没有额外的配置。在评估性能的同时,通常在模型的准确性和速度之间经常取决于权衡,因此我们在上面基准了这两个因素。该排行榜正在进行中,我们打算发布更多最先进的模型!
有两种方法可以作为Docker图像或PYPI软件包获得NBOOST。对于云用户,我们强烈建议通过Docker使用NBoost 。
?根据模型,您应该安装相应的张量或pytorch依赖性。我们在下面打包它们。
要安装NBoost,请按照下表。
| 依赖性 | ? Docker | ? PYPI | ? Kubernetes |
|---|---|---|---|
| Pytorch (推荐) | koursaros/nboost:latest-pt | pip install nboost[pt] | helm install nboost/nboost --set image.tag=latest-pt |
| 张量 | koursaros/nboost:latest-tf | pip install nboost[tf] | helm install nboost/nboost --set image.tag=latest-tf |
| 全部 | koursaros/nboost:latest-all | pip install nboost[all] | helm install nboost/nboost --set image.tag=latest-all |
| - (用于测试) | koursaros/nboost:latest-alpine | pip install nboost | helm install nboost/nboost --set image.tag=latest-alpine |
以任何方式安装它,如果您最终在$ nboost --help或$ docker run koursaros/nboost --help ,那么您就可以开始了!

 | 代理是NBoost的核心。代理本质上是启用该模型的包装纸。它能够从特定的搜索API(即elasticsearch)中理解传入的消息。当代理收到一条消息时,它会增加客户端要求的结果量,以便模型可以重新列出更大的集合并返回(希望)更好的结果。 例如,如果客户要求使用Elasticsearch的查询“ Brown Dogs”有10个结果,那么代理可能会将结果请求增加到100,并为客户提供最佳的10个结果。 |
在此示例中,我们将设置一个代理,以坐在客户端和Elasticsearch之间,并提高结果!
如果您想在GPU上运行示例,请确保使用Tensorflow 1.14-1.15,Pytorch或onnx运行时使用CUDA来支持建模功能。但是,如果您只想在CPU上运行它,请不要担心。对于这两种情况,只需运行:
pip install nboost[pt]?如果您已经拥有Elasticsearch服务器,则可以跳过此步骤!
如果您没有Elasticsearch,请不要担心!我们建议使用Docker设置本地Elasticsearch集群(前提是已安装了Docker)。首先,通过运行获取ES图像:
docker pull elasticsearch:7.4.2拥有图像后,您可以通过:
docker run -d -p 9200:9200 -p 9300:9300 -e " discovery.type=single-node " elasticsearch:7.4.2现在,我们准备部署我们的神经代理!这样做很简单,运行:
nboost
--uhost localhost
--uport 9200
--search_route " /<index>/_search "
--query_path url.query.q
--topk_path url.query.size
--default_topk 10
--choices_path body.hits.hits
--cvalues_path _source.passage?
--uhost和--uport应该与上面的Elasticsearch服务器相同! UHOST和UPORT对于上游主持人和上游端口(指上游服务器)而言是简短的。
如果您收到此消息: Listening: <host>:<port> ,那么我们很高兴!
NBoost具有内置的方便索引工具( nboost-index )。出于演示目的,将索引一组有关旅行和酒店通过NBoost的段落。您可以通过运行:
travel.csv随附nboost
nboost-index --file travel.csv --index_name travel --delim , --id_col现在让我们测试一下!使用:
curl " http://localhost:8000/travel/_search?pretty&q=passage:vegas&size=2 "如果Elasticsearch结果中有nboost标签,则恭喜它可以正常工作!

让我们检查一下NBoost前端。转到您的浏览器并访问Localhost:8000/nboost。
如果您无法访问浏览器,则可以
curl http://localhost:8000/nboost/statusfor相同信息。
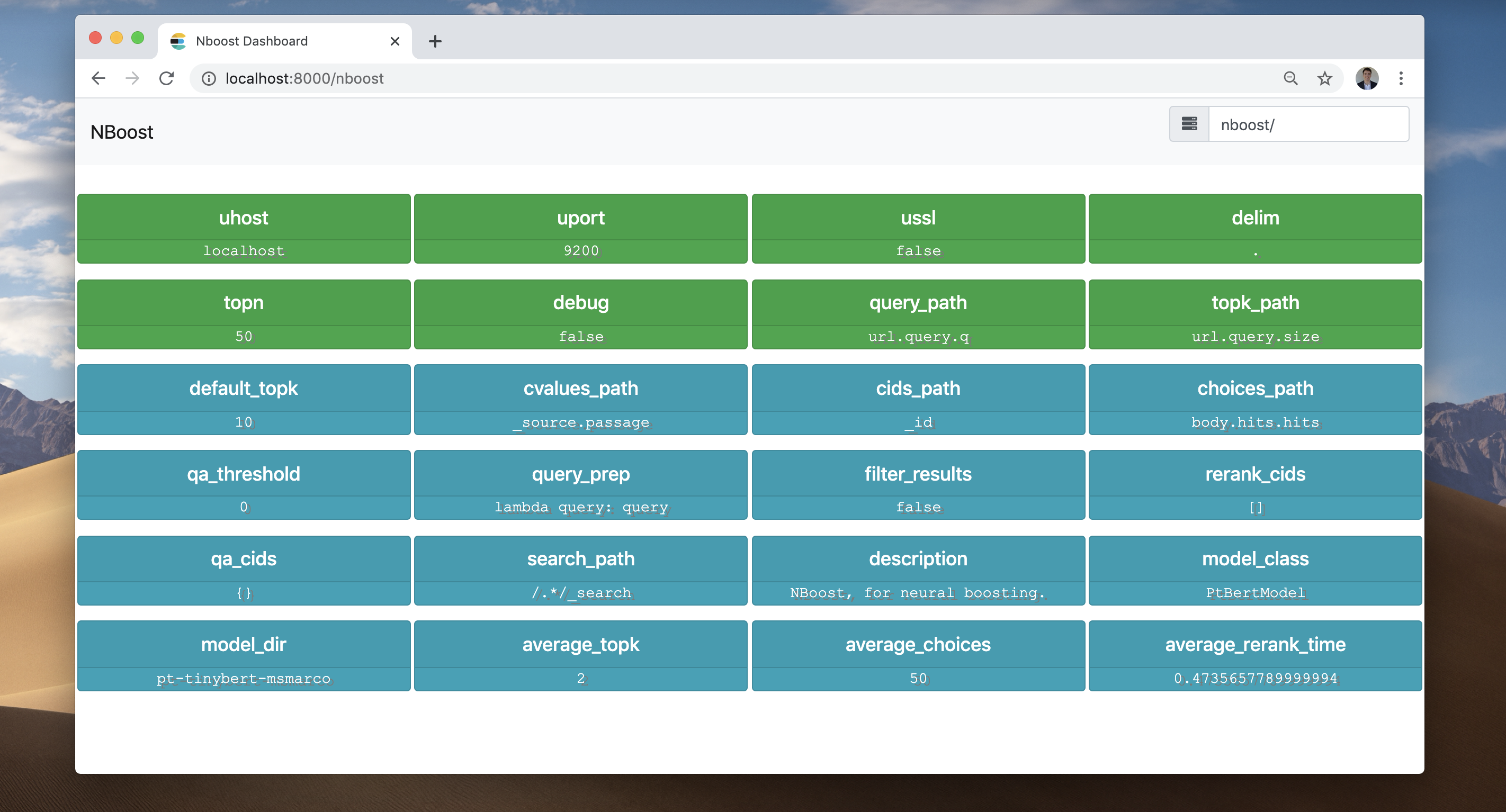
前端记录了发生的一切:
localhost:9200 。为了增加并行代理的数量,只需增加--workers 。对于更强大的部署方法,您可以通过Kubernetes分发代理(请参见下文)。

有关深入查询DSL和其他搜索API解决方案(例如Bing API),请参见文档。
我们可以使用头盔轻松地将NBOOST部署在Kubernetes群集中。
首先,我们需要在您的kubernetes群集中注册回购。
helm repo add nboost https://raw.githubusercontent.com/koursaros-ai/nboost/master/charts/
helm repo update让我们尝试部署四个复制品:
helm install --name nboost --set replicaCount=4 nboost/nboost所有可能的--set (values.yaml)选项如下:
| 范围 | 描述 | 默认 |
|---|---|---|
replicaCount | 部署的副本数量 | 3 |
image.repository | nboost图像名称 | koursaros/nboost |
image.tag | nboost图像标签 | latest-pt |
args.model | 模型类的名称 | nil |
args.model_dir | 固定模型的名称或目录 | pt-bert-base-uncased-msmarco |
args.qa | 是否使用QA插件 | False |
args.qa_model_dir | QA模型的名称或目录 | distilbert-base-uncased-distilled-squad |
args.model | 模型类的名称 | nil |
args.host | 代理的主机名 | 0.0.0.0 |
args.port | 代理人聆听的端口 | 8000 |
args.uhost | 上游搜索API服务器的主机名 | elasticsearch-master |
args.uport | 上游服务器的端口 | 9200 |
args.data_dir | 高速缓存型号二进制目录 | nil |
args.max_seq_len | 最大令牌长度 | 64 |
args.bufsize | 字节中的HTTP缓冲区大小 | 2048 |
args.batch_size | 通过RERANK模型运行的批次大小 | 4 |
args.multiplier | 增加结果的因素 | 5 |
args.workers | 服务代理的线程数量 | 10 |
args.query_path | 在要求查询的请求中的jsonpath | nil |
args.topk_path | jsonpath以找到要求的结果的数量 | nil |
args.choices_path | jsonpath可以找到一系列重新排序的选择 | nil |
args.cvalues_path | jsonpath找到选择的str值 | nil |
args.cids_path | jsonpath找到选择的ID | nil |
args.search_path | 通过NBOOST重新计的标签的URL路径 | nil |
service.type | Kubernetes服务类型 | LoadBalancer |
resources | 资源需求和限制适用于POD | {} |
nodeSelector | POD分配的节点标签 | {} |
affinity | POD分配的亲和力设置 | {} |
tolerations | POD分配的耐受标签 | [] |
image.pullPolicy | 图像拉策略 | IfNotPresent |
imagePullSecrets | Docker注册表秘密名称为数组 | [] (不在部署的吊舱中添加图像拉秘密) |
nameOverride | 字符串到覆盖图表。名称 | nil |
fullnameOverride | 字符串到覆盖图表。 | nil |
serviceAccount.create | 指定是否创建了服务帐户 | nil |
serviceAccount.name | 服务帐户的名称要使用。如果未设置并创建为真,则使用全名模板生成名称 | nil |
serviceAccount.create | 指定是否创建了服务帐户 | nil |
podSecurityContext.fsGroup | 容器的组ID | nil |
securityContext.runAsUser | 容器的用户ID | 1001 |
ingress.enabled | 启用入口资源 | false |
ingress.hostName | 安装的主机名 | nil |
ingress.path | URL结构内的路径 | [] |
ingress.tls | 使用TLS启用入口 | [] |
ingress.tls.secretName | 使用TLS类型的秘密 | chart-example-tls |
官方的NBoost文档托管在nboost.readthedocs.io上。它是在每个新版本中自动构建,更新和存档的。
贡献非常感谢!您可以进行更正或更新,并将其提交为NBOOST。这是步骤:
fix-nboost-typo-1Fix/model-bert: improve the readability and move sectionsFix/model-bert: improve the readability and move sections可以在撰稿人指南中找到更多细节。
如果您在学术论文中使用NBoost,我们很乐意被引用。这是引用NBoost的两种方法:
footnote{https://github.com/koursaros-ai/nboost}
@misc{koursaros2019NBoost,
title={NBoost: Neural Boosting Search Results},
author={Thienes, Cole and Pertschuk, Jack},
howpublished={ url {https://github.com/koursaros-ai/nboost}},
year={2019}
}如果您已经下载了NBoost二进制或源代码的副本,请注意,NBOOST二进制代码和源代码均在Apache许可证版本2.0下获得许可。
Koursaros AI很高兴将此开源软件带到社区。

