nboost
1.0.0
?仮想アシスタントウィジェットのベータテスターを探しています。あなたのウェブサイトでそれを使用することに興味がある場合は、お問い合わせください。
ハイライト•概要•ベンチマーク•インストール•開始•kubernetes•ドキュメント•チュートリアル•貢献•リリースノート•ブログ
boost nboostは、検索結果の関連性を改善するために最先端のモデルを開発および展開するためのスケーラブルな検索エンジンブーストプラットフォームです。

NBoostは、触手モデルを活用して、ドメイン固有のニューラル検索エンジンを生成します。プラットフォームは、質問応答など、ランク付けされた入力を必要とする他の下流タスクを改善することもできます。
ドメイン固有のモデルをリクエストするか、フィードバックを残してください
NBoostのワークフローは比較的簡単です。上記のグラフィックを取り、この場合のサーバーはElasticSearchであると想像してください。

従来の検索リクエストでは、ユーザーはElasticSearchにクエリを送信し、結果を取り戻します。

NBOOST検索リクエストでは、ユーザーはモデルにクエリを送信します。次に、モデルはElasticSearchの結果を要求し、ユーザーに戻るのに最適なものを選択します。
?訓練されたものとは異なる構築されたセットでモデルを評価していることに注意してください(MS Marco vs Trec-Car)。これらのモデルの他の多くの現実世界の検索問題に対する一般化可能性を示唆しています。
| 微調整されたモデル | 依存 | 評価セット | 検索ブースト[1] | GPUの速度 |
|---|---|---|---|---|
nboost/pt-tinybert-msmarco (デフォルト) | ビングクエリ | +45% (0.26対0.18) | 〜50ms/Query | |
nboost/pt-bert-base-uncased-msmarco | ビングクエリ | +62% (0.29対0.18) | 〜300ミリ秒/クエリ | |
nboost/pt-bert-large-msmarco | ビングクエリ | +77% (0.32対0.18) | - | |
nboost/pt-biobert-base-msmarco | バイオメッド | +66% (0.17対0.10) | 〜300ミリ秒/クエリ |
ここで再現するための指示。
[1] ElasticSearchのデフォルトであるBM25と比較したMRR。トップ50の再ランキング。
[2] https://github.com/nyu-dl/dl4marco-bert
これらの微調整されたモデルのいずれかをnboostで使用するには、たとえばnboost --model_dir bert-base-uncased-msmarcoを実行すると、自動的にダウンロードしてキャッシュします。
事前に訓練された言語理解モデルを使用すると、テキスト検索だけで、追加の構成がほとんどない場合は、検索関連メトリックをほぼ2倍に増やすことができます。パフォーマンスを評価している間、多くの場合、モデルの精度と速度の間にトレードオフがあるため、上記のこれらの両方の要因の両方をベンチマークします。このリーダーボードは進行中の作業であり、より多くの最先端のモデルをリリースするつもりです!
Dockerイメージとして、またはPypiパッケージとして、NBOOSTを取得するには2つの方法があります。クラウドユーザーの場合、Dockerを介してNboostを使用することを強くお勧めします。
?モデルに応じて、それぞれのTensorflowまたはPytorchの依存関係をインストールする必要があります。以下にパッケージ化します。
NBOOSTをインストールするには、以下の表をフォローしてください。
| 依存 | ? Docker | ?ピピ | ? Kubernetes |
|---|---|---|---|
| Pytorch (推奨) | koursaros/nboost:latest-pt | pip install nboost[pt] | helm install nboost/nboost --set image.tag=latest-pt |
| Tensorflow | koursaros/nboost:latest-tf | pip install nboost[tf] | helm install nboost/nboost --set image.tag=latest-tf |
| 全て | koursaros/nboost:latest-all | pip install nboost[all] | helm install nboost/nboost --set image.tag=latest-all |
| - (テスト用) | koursaros/nboost:latest-alpine | pip install nboost | helm install nboost/nboost --set image.tag=latest-alpine |
どのような方法で、 $ nboost --helpまたは$ docker run koursaros/nboost --helpの後に次のメッセージを読むことになった場合、あなたは行く準備ができています!

 | プロキシはnboostの中核です。プロキシは、本質的にモデルを提供できるラッパーです。特定の検索API(つまりElasticSearch)からの受信メッセージを理解することができます。プロキシがメッセージを受信すると、モデルがより大きなセットを再表示し、(できれば)より良い結果を返すことができるように、クライアントが求めている結果の量を増やします。 たとえば、クライアントがElasticSearchのクエリ「Brown Dogs」を使用するように10の結果を要求した場合、プロキシは結果要求を100に増やし、クライアントにとって最高の10の結果をフィルタリングする場合があります。 |
この例では、クライアントとElasticSearchの間に座って結果を高めるためにプロキシを設定します!
GPUで例を実行する場合は、モデリング機能をサポートするために、CUDAを使用してTensorflow 1.14-1.15、Pytorch、またはOnNXランタイムがあることを確認してください。ただし、CPUで実行したい場合は、心配しないでください。どちらの場合も、実行するだけです。
pip install nboost[pt]?既にElasticSearchサーバーを持っている場合は、この手順をスキップできます!
ElasticSearchを持っていない場合は、心配しないでください! Dockerを使用してローカルElasticsearchクラスターをセットアップすることをお勧めします(Dockerがインストールされていることを提供します)。まず、実行してESイメージを取得します。
docker pull elasticsearch:7.4.2画像を取得したら、以下を介してElasticSearchサーバーを実行できます。
docker run -d -p 9200:9200 -p 9300:9300 -e " discovery.type=single-node " elasticsearch:7.4.2これで、ニューラルプロキシを展開する準備ができました!これを行うのは非常に簡単です、実行してください:
nboost
--uhost localhost
--uport 9200
--search_route " /<index>/_search "
--query_path url.query.q
--topk_path url.query.size
--default_topk 10
--choices_path body.hits.hits
--cvalues_path _source.passage?
--uhostと--uport、上記のElasticsearchサーバーと同じでなければなりません! UHOSTとUPORTは、上流のホストとアップストリームポートの略です(上流サーバーを参照)。
このメッセージを受け取ったら: Listening: <host>:<port> 、私たちは行ってもいいです!
nboostには、( nboost-index )に組み込まれた便利なインデックスングツールがあります。デモンストレーションのために、NBOOSTを介して旅行やホテルに関する一連のパッセージをインデックス化することになります。実行して、ElasticSearchサーバーにインデックスを追加できます。
travel.csvにはnboostが付属しています
nboost-index --file travel.csv --index_name travel --delim , --id_colそれでは、テストしましょう! elasticsearchをヒットしてください:
curl " http://localhost:8000/travel/_search?pretty&q=passage:vegas&size=2 " ElasticSearchの結果にnboostタグが含まれている場合、おめでとうございます。

NBOOSTフロントエンドをチェックしてみましょう。ブラウザに移動して、localhost:8000/nboostにアクセスしてください。
ブラウザにアクセスできない場合は、同じ情報に対して
curl http://localhost:8000/nboost/statusできます。
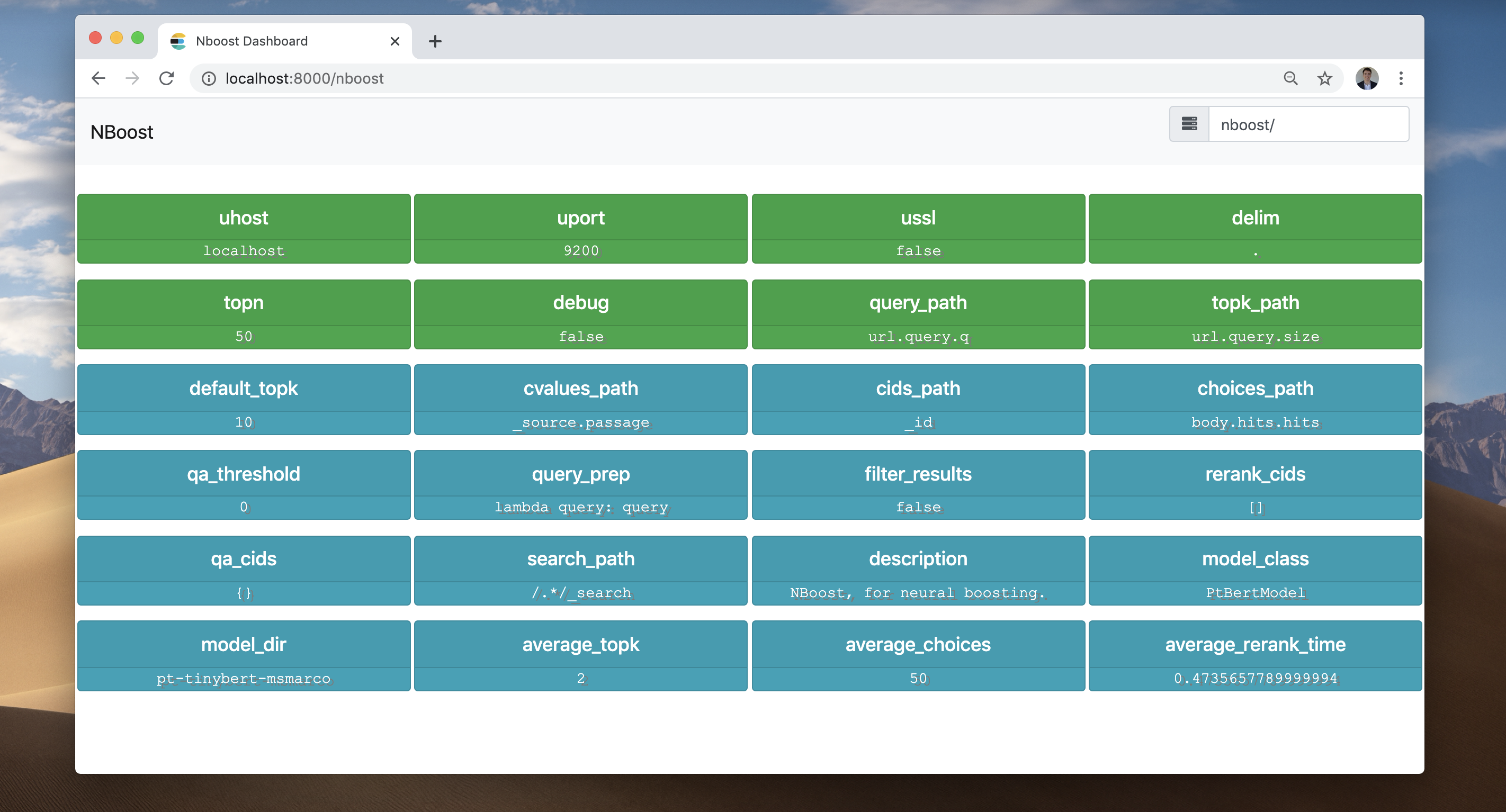
フロントエンドは、起こったことすべてを記録しました:
localhost:9200のサーバーに接続されています。並列プロキシの数を増やすには、単に--workersを増やします。より堅牢な展開アプローチのために、Kubernetesを介してプロキシを配布できます(以下を参照)。

詳細なクエリDSLおよびその他の検索APIソリューション(Bing APIなど)については、ドキュメントを参照してください。
ヘルムを使用してKubernetesクラスターにnboostを簡単に展開できます。
まず、Kubernetesクラスターにレポを登録する必要があります。
helm repo add nboost https://raw.githubusercontent.com/koursaros-ai/nboost/master/charts/
helm repo update4つのレプリカを展開してみましょう。
helm install --name nboost --set replicaCount=4 nboost/nboostすべての可能な--set (values.yaml)オプションを以下に示します。
| パラメーター | 説明 | デフォルト |
|---|---|---|
replicaCount | 展開するレプリカの数 | 3 |
image.repository | nboost画像名 | koursaros/nboost |
image.tag | nboost画像タグ | latest-pt |
args.model | モデルクラスの名前 | nil |
args.model_dir | Finetunedモデルの名前またはディレクトリ | pt-bert-base-uncased-msmarco |
args.qa | QAプラグインを使用するかどうか | False |
args.qa_model_dir | QAモデルの名前またはディレクトリ | distilbert-base-uncased-distilled-squad |
args.model | モデルクラスの名前 | nil |
args.host | プロキシのホスト名 | 0.0.0.0 |
args.port | プロキシを聴くためのポート | 8000 |
args.uhost | アップストリーム検索APIサーバーのホスト名 | elasticsearch-master |
args.uport | 上流サーバーのポート | 9200 |
args.data_dir | モデルバイナリをキャッシュするディレクトリ | nil |
args.max_seq_len | マックスの組み合わせトークン長 | 64 |
args.bufsize | バイト単位のHTTPバッファーのサイズ | 2048 |
args.batch_size | Rerankモデルを実行するためのバッチサイズ | 4 |
args.multiplier | 結果を増やす要因 | 5 |
args.workers | プロキシにサービスを提供するスレッドの数 | 10 |
args.query_path | クエリを見つけるためのリクエストのjsonpath | nil |
args.topk_path | 要求された結果の数を見つけるためのjsonpath | nil |
args.choices_path | jsonpath並べ替える選択肢の配列を見つける | nil |
args.cvalues_path | JsonPath選択のSTR値を見つける | nil |
args.cids_path | JsonPath選択のIDを見つける | nil |
args.search_path | NBOOSTを介して再ランキングするためのタグのURLパス | nil |
service.type | Kubernetesサービスタイプ | LoadBalancer |
resources | ポッドに適用するためのリソースのニーズと制限 | {} |
nodeSelector | ポッド割り当てのノードラベル | {} |
affinity | ポッド割り当てのアフィニティ設定 | {} |
tolerations | ポッド割り当てのための寛容ラベル | [] |
image.pullPolicy | 画像プルポリシー | IfNotPresent |
imagePullSecrets | ArrayとしてのDockerレジストリの秘密名 | [] (展開されたポッドに画像プルシークレットを追加しません) |
nameOverride | Chart.Nameをオーバーライドする文字列 | nil |
fullnameOverride | Chart.fullnameをオーバーライドする文字列 | nil |
serviceAccount.create | サービスアカウントが作成されるかどうかを指定します | nil |
serviceAccount.name | 使用するサービスアカウントの名前。設定されていない場合はTrueがある場合、FullNameテンプレートを使用して名前が生成されます | nil |
serviceAccount.create | サービスアカウントが作成されるかどうかを指定します | nil |
podSecurityContext.fsGroup | コンテナのグループID | nil |
securityContext.runAsUser | コンテナのユーザーID | 1001 |
ingress.enabled | イングレスリソースを有効にします | false |
ingress.hostName | インストールのホスト名 | nil |
ingress.path | URL構造内のパス | [] |
ingress.tls | TLSでイングレスを有効にします | [] |
ingress.tls.secretName | TLSタイプの秘密を使用する | chart-example-tls |
公式のnboostドキュメントは、nboost.readthedocs.ioでホストされています。新しいリリースごとに自動的に構築、更新、アーカイブされます。
貢献は大歓迎です!修正または更新を行い、nboostにコミットできます。ここにステップがあります:
fix-nboost-typo-1Fix/model-bert: improve the readability and move sectionsFix/model-bert: improve the readability and move sections詳細については、貢献者ガイドラインをご覧ください。
アカデミックペーパーでNBOOSTを使用する場合は、引用したいと思います。 NBOOSTを引用する2つの方法は次のとおりです。
footnote{https://github.com/koursaros-ai/nboost}
@misc{koursaros2019NBoost,
title={NBoost: Neural Boosting Search Results},
author={Thienes, Cole and Pertschuk, Jack},
howpublished={ url {https://github.com/koursaros-ai/nboost}},
year={2019}
}NBOOSTバイナリまたはソースコードのコピーをダウンロードした場合、NBOOSTバイナリとソースコードの両方がApacheライセンスバージョン2.0に基づいてライセンスされていることに注意してください。
Koursaros AIは、このオープンソースソフトウェアをコミュニティに持ち込むことに興奮しています。

