nboost
1.0.0
? Nous recherchons des testeurs bêta pour notre widget assistant virtuel. Contactez-nous si vous souhaitez l'utiliser sur votre site Web.
Faits saillants • Présentation • Benchmarks • Installer • Débutant • Kubernetes • Documentation • Tutoriels • Contribution • Notes de publication • Blog
⚡ NBOOST est une plate-forme évolutive et stimulant le moteur de recherche pour développer et déployer des modèles de pointe afin d'améliorer la pertinence des résultats de recherche.

NBOOST exploite des modèles Finetuned pour produire des moteurs de recherche neuronaux spécifiques au domaine. La plate-forme peut également améliorer d'autres tâches en aval nécessitant des entrées classées, telles que la réponse aux questions.
Contactez-nous pour demander des modèles spécifiques au domaine ou laisser des commentaires
Le flux de travail de NBOost est relativement simple. Prenez le graphique ci-dessus et imaginez que le serveur dans ce cas est Elasticsearch.

Dans une demande de recherche conventionnelle , l'utilisateur envoie une requête à Elasticsearch et récupére les résultats.

Dans une demande de recherche NBOost , l'utilisateur envoie une requête au modèle . Ensuite, le modèle demande des résultats d' Elasticsearch et choisit les meilleurs pour revenir à l'utilisateur.
? Notez que nous évaluons des modèles sur des ensembles construits différemment que sur lesquels ils ont été formés (MS Marco vs Trec-Car), ce qui suggère la généralisation de ces modèles à de nombreux autres problèmes de recherche du monde réel.
| Modèles affinés | Dépendance | Évaluation d'évaluation | Rechercher Boost [1] | Vitesse sur GPU |
|---|---|---|---|---|
nboost/pt-tinybert-msmarco ( par défaut ) | requêtes de bing | + 45% (0,26 vs 0,18) | ~ 50 ms / requête | |
nboost/pt-bert-base-uncased-msmarco | requêtes de bing | + 62% (0,29 vs 0,18) | ~ 300 ms / requête | |
nboost/pt-bert-large-msmarco | requêtes de bing | + 77% (0,32 vs 0,18) | - | |
nboost/pt-biobert-base-msmarco | biomélé | + 66% (0,17 vs 0,10) | ~ 300 ms / requête |
Instructions pour reproduire ici.
[1] MRR par rapport à BM25, par défaut pour Elasticsearch. Rerraner le top 50.
[2] https://github.com/nyu-dl/dl4marco-bert
Pour utiliser l'un de ces modèles affinés avec NBOost, exécutez nboost --model_dir bert-base-uncased-msmarco par exemple, et il téléchargera et se cache automatiquement.
En utilisant des modèles de compréhension du langage pré-formé, vous pouvez augmenter les mesures de pertinence de recherche de près de 2x par rapport à la recherche de texte, avec peu ou pas de configuration supplémentaire. Tout en évaluant les performances, il y a souvent un compromis entre la précision du modèle et la vitesse, nous avons donc comparé ces deux facteurs ci-dessus. Ce classement est un travail en cours, et nous avons l'intention de publier plus de modèles de pointe!
Il existe deux façons d'obtenir NBOost, soit en tant qu'image Docker, soit en tant que package PYPI. Pour les utilisateurs du cloud, nous vous recommandons fortement d'utiliser NBOost via Docker .
? Selon votre modèle, vous devez installer les dépendances respectives de TensorFlow ou Pytorch. Nous les emballons ci-dessous.
Pour installer NBOOST, suivez le tableau ci-dessous.
| Dépendance | ? Docker | ? PYPI | ? Kubernetes |
|---|---|---|---|
| Pytorch ( recommandé ) | koursaros/nboost:latest-pt | pip install nboost[pt] | helm install nboost/nboost --set image.tag=latest-pt |
| Tensorflow | koursaros/nboost:latest-tf | pip install nboost[tf] | helm install nboost/nboost --set image.tag=latest-tf |
| Tous | koursaros/nboost:latest-all | pip install nboost[all] | helm install nboost/nboost --set image.tag=latest-all |
| - ( pour les tests ) | koursaros/nboost:latest-alpine | pip install nboost | helm install nboost/nboost --set image.tag=latest-alpine |
De toute façon que vous l'installez, si vous finissez par lire le message suivant après $ nboost --help ou $ docker run koursaros/nboost --help , alors vous êtes prêt à partir!

 | Le proxy est le cœur de NBOost. Le proxy est essentiellement un emballage pour permettre de servir le modèle. Il est capable de comprendre les messages entrants à partir d'API de recherche spécifique (c'est-à-dire Elasticsearch). Lorsque le proxy reçoit un message, il augmente la quantité de résultats que le client demande afin que le modèle puisse re-réerser un ensemble plus grand et renvoyer les résultats (espérons-le). Par exemple, si un client demande 10 résultats à faire avec la requête "Brown Dogs" de Elasticsearch, le proxy peut augmenter la demande de résultats à 100 et filtrer les dix meilleurs résultats pour le client. |
Dans cet exemple, nous installerons un proxy pour s'asseoir entre le client et Elasticsearch et augmenterons les résultats!
Si vous souhaitez exécuter l'exemple sur un GPU, assurez-vous d'avoir TensorFlow 1.14-1.15, Pytorch ou ONNX Runtime avec CUDA pour prendre en charge la fonctionnalité de modélisation. Cependant, si vous voulez simplement l'exécuter sur un processeur, ne vous inquiétez pas. Pour les deux cas, il suffit de courir:
pip install nboost[pt]? Si vous avez déjà un serveur Elasticsearch, vous pouvez ignorer cette étape!
Si vous n'avez pas Elasticsearch, ne vous inquiétez pas! Nous vous recommandons de mettre en place un cluster Elasticsearch local à l'aide de Docker (à condition que Docker soit installé). Tout d'abord, obtenez l'image ES en fonctionnant:
docker pull elasticsearch:7.4.2Une fois que vous avez l'image, vous pouvez exécuter un serveur Elasticsearch via:
docker run -d -p 9200:9200 -p 9300:9300 -e " discovery.type=single-node " elasticsearch:7.4.2Maintenant, nous sommes prêts à déployer notre proxy neuronal! Il est très simple de le faire, courez:
nboost
--uhost localhost
--uport 9200
--search_route " /<index>/_search "
--query_path url.query.q
--topk_path url.query.size
--default_topk 10
--choices_path body.hits.hits
--cvalues_path _source.passage? Le
--uhostet--uportdoivent être les mêmes que le serveur Elasticsearch ci-dessus! Uhost et uport sont abrégés pour le hoste en amont et le port en amont (se référant au serveur en amont).
Si vous recevez ce message: Listening: <host>:<port> , alors nous sommes prêts à partir!
NBOost a un outil d'indexation pratique intégré ( nboost-index ). À des fins de démonstration, indexera un ensemble de passages sur les voyages et les hôtels via NBOost. Vous pouvez ajouter l'index à votre serveur Elasticsearch en exécutant:
travel.csvest livré avec NBOost
nboost-index --file travel.csv --index_name travel --delim , --id_colMaintenant, testons-le! Frappez la recherche Elastics avec:
curl " http://localhost:8000/travel/_search?pretty&q=passage:vegas&size=2 " Si le résultat Elasticsearch a la balise nboost , félicitations, cela fonctionne!

Voyons le frontend NBOost . Allez dans votre navigateur et visitez LocalHost: 8000 / nboost.
Si vous n'avez pas accès à un navigateur, vous pouvez
curl http://localhost:8000/nboost/statuspour les mêmes informations.
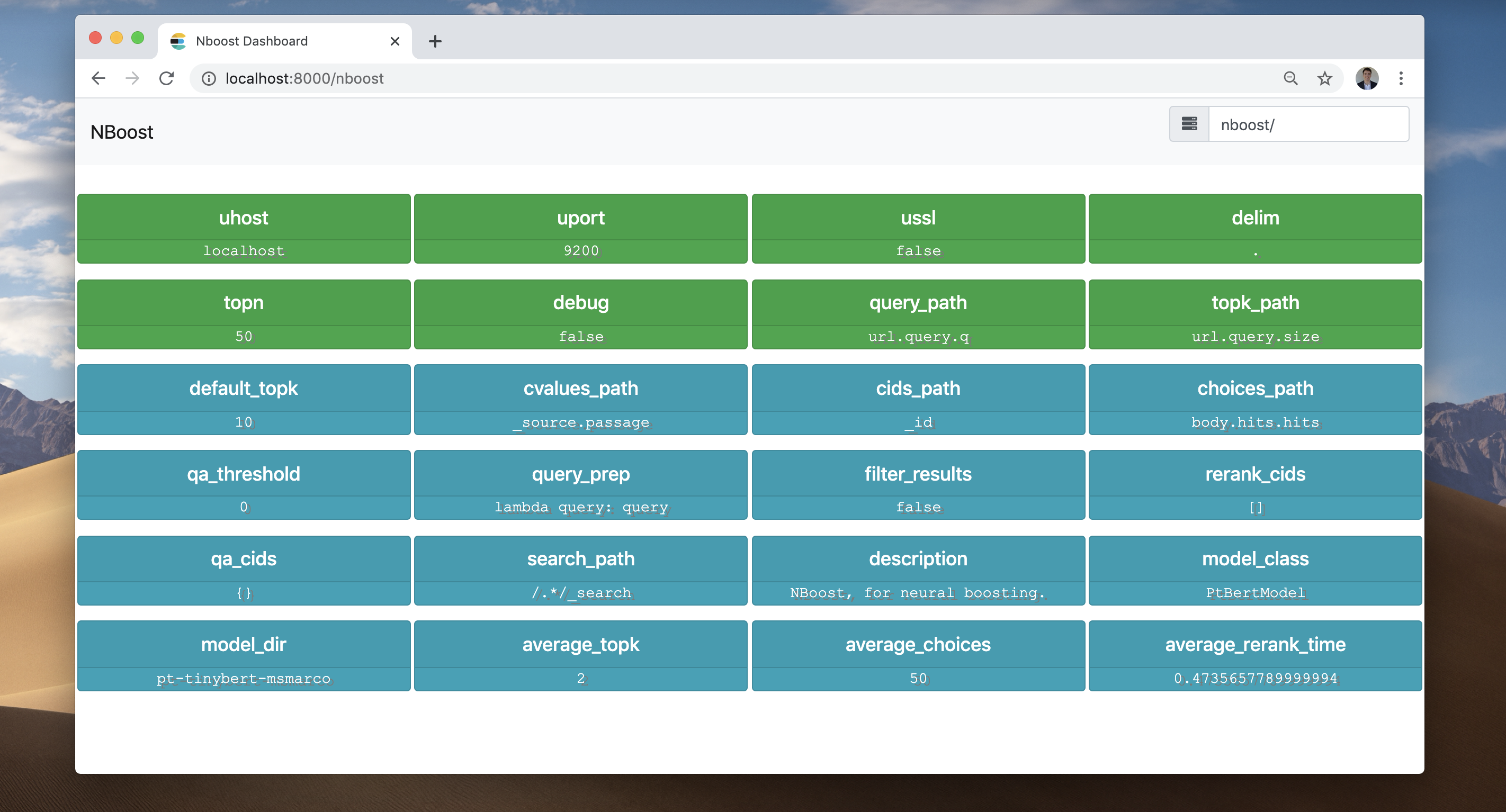
Le frontend a enregistré tout ce qui s'est passé:
localhost:9200 . Pour augmenter le nombre de proxies parallèles, augmentez simplement --workers . Pour une approche de déploiement plus robuste, vous pouvez distribuer le proxy via Kubernetes (voir ci-dessous).

Pour la requête approfondie DSL et d'autres solutions API de recherche (comme l'API Bing), consultez les documents.
Nous pouvons facilement déployer NBOost dans un cluster Kubernetes à l'aide de Helm.
Nous devons d'abord enregistrer le dépôt avec votre cluster Kubernetes.
helm repo add nboost https://raw.githubusercontent.com/koursaros-ai/nboost/master/charts/
helm repo updateEssayons de déployer quatre répliques:
helm install --name nboost --set replicaCount=4 nboost/nboost Toutes les options possibles --set (valeurs.yaml) sont répertoriées ci-dessous:
| Paramètre | Description | Défaut |
|---|---|---|
replicaCount | Nombre de répliques à déployer | 3 |
image.repository | Nom de l'image nboost | koursaros/nboost |
image.tag | Tag d'image nboost | latest-pt |
args.model | Nom de la classe de modèle | nil |
args.model_dir | Nom ou répertoire du modèle Finetuned | pt-bert-base-uncased-msmarco |
args.qa | S'il faut utiliser le plugin QA | False |
args.qa_model_dir | Nom ou répertoire du modèle QA | distilbert-base-uncased-distilled-squad |
args.model | Nom de la classe de modèle | nil |
args.host | Nom d'hôte du proxy | 0.0.0.0 |
args.port | Port pour que le proxy puisse écouter | 8000 |
args.uhost | Nom d'hôte du serveur API de recherche en amont | elasticsearch-master |
args.uport | Port du serveur en amont | 9200 |
args.data_dir | Répertoire pour cache modèle binaire | nil |
args.max_seq_len | Longueur de jeton combiné max | 64 |
args.bufsize | Taille du tampon HTTP en octets | 2048 |
args.batch_size | Taille du lot pour faire passer le modèle RERANK | 4 |
args.multiplier | Facteur pour augmenter les résultats de | 5 |
args.workers | Nombre de threads servant le proxy | 10 |
args.query_path | JSONPATH dans la demande de trouver la requête | nil |
args.topk_path | JSONPATH pour trouver le nombre de résultats demandés | nil |
args.choices_path | JSONPATH pour trouver la gamme de choix pour réorganiser | nil |
args.cvalues_path | JSONPATH pour trouver les valeurs STR des choix | nil |
args.cids_path | JSONPATH pour trouver les identifiants des choix | nil |
args.search_path | Le chemin d'URL pour étiqueter pour redirige via nboost | nil |
service.type | Type de service Kubernetes | LoadBalancer |
resources | Besoins et limites de ressources à appliquer au pod | {} |
nodeSelector | Étiquettes de nœud pour l'attribution de POD | {} |
affinity | Paramètres d'affinité pour l'attribution des pods | {} |
tolerations | Étiquettes de tolérance pour l'attribution des pods | [] |
image.pullPolicy | Politique d'image d'image | IfNotPresent |
imagePullSecrets | Docker Registry Noms Secret comme un tableau | [] (N'ajoute pas les secrets d'image à tirer sur les pods déployés) |
nameOverride | Chaîne pour remplacer le graphique.name | nil |
fullnameOverride | String to Override Chart.FullName | nil |
serviceAccount.create | Spécifie si un compte de service est créé | nil |
serviceAccount.name | Le nom du compte de service à utiliser. S'il n'est pas défini et créé est vrai, un nom est généré à l'aide du modèle de nom complet | nil |
serviceAccount.create | Spécifie si un compte de service est créé | nil |
podSecurityContext.fsGroup | ID de groupe pour le conteneur | nil |
securityContext.runAsUser | ID utilisateur pour le conteneur | 1001 |
ingress.enabled | Activer la ressource entrée | false |
ingress.hostName | Nom d'hôte à votre installation | nil |
ingress.path | Chemin dans la structure URL | [] |
ingress.tls | Activer la pénétration avec TLS | [] |
ingress.tls.secretName | Secret de type TLS à utiliser | chart-example-tls |
La documentation officielle de NBOost est hébergée sur nboost.readthedocs.io. Il est automatiquement construit, mis à jour et archivé à chaque nouvelle version.
Les contributions sont grandement appréciées! Vous pouvez effectuer des corrections ou des mises à jour et les engager dans NBOost. Voici les étapes:
fix-nboost-typo-1Fix/model-bert: improve the readability and move sectionsFix/model-bert: improve the readability and move sectionsPlus de détails peuvent être trouvés dans les directives des contributeurs.
Si vous utilisez NBOost dans un journal académique, nous serions ravis d'être cités. Voici les deux façons de citer Nboost:
footnote{https://github.com/koursaros-ai/nboost}
@misc{koursaros2019NBoost,
title={NBoost: Neural Boosting Search Results},
author={Thienes, Cole and Pertschuk, Jack},
howpublished={ url {https://github.com/koursaros-ai/nboost}},
year={2019}
}Si vous avez téléchargé une copie du code binaire ou source NBOost, veuillez noter que le code binaire et source NBOost est tous deux sous licence Apache, version 2.0.
Koursaros AI est ravie d'apporter ce logiciel open source à la communauté.

