nboost
1.0.0
? 우리는 가상 어시스턴트 위젯에 대한 베타 테스터를 찾고 있습니다. 웹 사이트에서 사용하는 데 관심이 있으시면 저희에게 연락하십시오.
하이라이트 • 개요 • 벤치 마크 • 설치 • 설치 • Kubernetes • 문서 • 자습서 • 기여 • 릴리스 메모 • 블로그
nboost는 검색 결과의 관련성을 향상시키기 위해 최첨단 모델을 개발하고 배포하기위한 확장 가능한 검색 엔진 부스팅 플랫폼입니다.

NBOOST는 미세한 모델을 활용하여 도메인 별 신경 검색 엔진을 생성합니다. 이 플랫폼은 또한 질문 답변과 같은 순위 입력이 필요한 다른 다운 스트림 작업을 개선 할 수 있습니다.
도메인 별 모델을 요청하거나 피드백을 남기려면 당사에 문의하십시오
nboost의 워크 플로우는 비교적 간단합니다. 위의 그래픽을 사용 하여이 경우 서버가 엘라스틱 검색이라고 상상해보십시오.

기존의 검색 요청 에서 사용자는 쿼리를 Elasticsearch 로 보내서 결과를 되 찾습니다.

nboost 검색 요청 에서 사용자는 쿼리를 모델 로 보냅니다. 그런 다음이 모델은 Elasticsearch 의 결과를 요청하고 사용자에게 반환하기 위해 가장 좋은 것을 선택합니다.
? 우리는 훈련을받은 것과 다르게 구성된 세트 (MS Marco vs Trec-Car)에 대한 모델을 평가하고 있으며,이 모델의 일반화 가능성을 다른 많은 실제 검색 문제에 대해 제안합니다.
| 미세 조정 모델 | 의존 | 평가 세트 | 검색 부스트 [1] | GPU 속도 |
|---|---|---|---|---|
nboost/pt-tinybert-msmarco ( 기본값 ) | 빙 쿼리 | +45% (0.26 vs 0.18) | ~ 50ms/쿼리 | |
nboost/pt-bert-base-uncased-msmarco | 빙 쿼리 | +62% (0.29 대 0.18) | ~ 300ms/쿼리 | |
nboost/pt-bert-large-msmarco | 빙 쿼리 | +77% (0.32 vs 0.18) | - | |
nboost/pt-biobert-base-msmarco | 생물체 | +66% (0.17 대 0.10) | ~ 300ms/쿼리 |
재생하는 지침.
[1] MRR Elasticsearch의 기본값 인 BM25에 비해. 상위 50 대를 재고합니다.
[2] https://github.com/nyu-dl/dl4marco-bert
nboost와 함께이 미세 조정 된 모델 중 하나를 사용하려면 nboost --model_dir bert-base-uncased-msmarco 실행하면 자동으로 다운로드 및 캐시가됩니다.
미리 훈련 된 언어 이해 모델을 사용하면 추가 구성이 거의 없거나 전혀없는 텍스트 검색에 비해 검색 관련 메트릭을 거의 2 배 씩 향상시킬 수 있습니다. 성능을 평가하는 동안 모델 정확도와 속도 사이에는 종종 트레이드 오프가 있으므로 위의 두 가지 요소를 모두 벤치마킹합니다. 이 리더 보드는 진행중인 작업이며, 우리는 더 많은 최첨단 모델을 출시하려고합니다!
Docker 이미지 또는 PYPI 패키지로 NBOOST를 얻는 방법에는 두 가지가 있습니다. 클라우드 사용자의 경우 Docker를 통해 Nboost를 사용하는 것이 좋습니다 .
? 모델에 따라 각 Tensorflow 또는 Pytorch 종속성을 설치해야합니다. 우리는 아래에 포장합니다.
NBOOST를 설치하려면 아래 표를 따르십시오.
| 의존 | ? 도커 | ? pypi | ? Kubernetes |
|---|---|---|---|
| Pytorch ( 권장 ) | koursaros/nboost:latest-pt | pip install nboost[pt] | helm install nboost/nboost --set image.tag=latest-pt |
| 텐서 플로 | koursaros/nboost:latest-tf | pip install nboost[tf] | helm install nboost/nboost --set image.tag=latest-tf |
| 모두 | koursaros/nboost:latest-all | pip install nboost[all] | helm install nboost/nboost --set image.tag=latest-all |
| - ( 테스트 용 ) | koursaros/nboost:latest-alpine | pip install nboost | helm install nboost/nboost --set image.tag=latest-alpine |
어떤 방식 으로든 설치하십시오. $ nboost --help 또는 $ docker run koursaros/nboost --help 이후 다음 메시지를 읽으면 갈 준비가되었습니다!

 | 프록시는 Nboost의 핵심입니다. 프록시는 본질적으로 모델을 제공하는 래퍼입니다. 특정 검색 API (예 : Elasticsearch)의 들어오는 메시지를 이해할 수 있습니다. 프록시가 메시지를 받으면 클라이언트가 요구하는 결과의 양이 증가하여 모델이 더 큰 세트를 재고하고 (희망적으로) 더 나은 결과를 반환 할 수 있도록합니다. 예를 들어, 클라이언트가 Elasticsearch의 쿼리 "Brown Dogs"와 관련하여 10 개의 결과를 요청하면 프록시는 결과 요청을 100으로 증가시키고 클라이언트에 대한 최고의 10 가지 결과를 필터링 할 수 있습니다. |
이 예에서는 클라이언트와 Elasticsearch 사이에 앉을 프록시를 설정하고 결과를 향상시킵니다!
GPU에서 예제를 실행하려면 모델링 기능을 지원하기 위해 Tensorflow 1.14-1.15, Pytorch 또는 Onnx 런타임이 있는지 확인하십시오. 그러나 CPU에서 실행하려면 걱정하지 마십시오. 두 경우 모두 실행하십시오.
pip install nboost[pt]? 이미 Elasticsearch 서버가있는 경우이 단계를 건너 뛸 수 있습니다!
elasticsearch가 없다면 걱정하지 마십시오! Docker를 사용하여 로컬 Elasticsearch 클러스터를 설정하는 것이 좋습니다 (Docker가 설치된 제공). 먼저 실행하여 ES 이미지를 얻습니다.
docker pull elasticsearch:7.4.2이미지가 있으면 다음을 통해 Elasticsearch 서버를 실행할 수 있습니다.
docker run -d -p 9200:9200 -p 9300:9300 -e " discovery.type=single-node " elasticsearch:7.4.2이제 우리는 신경 프록시를 배치 할 준비가되었습니다! 이렇게하는 것은 매우 간단합니다.
nboost
--uhost localhost
--uport 9200
--search_route " /<index>/_search "
--query_path url.query.q
--topk_path url.query.size
--default_topk 10
--choices_path body.hits.hits
--cvalues_path _source.passage?
--uhost및--uport위의 Elasticsearch 서버와 동일해야합니다! Uhost 및 Uport는 업스트림 호스트 및 업스트림 포트 (업스트림 서버 참조)의 경우 짧습니다.
이 메시지를받는다면 : Listening: <host>:<port> , 우리는 갈 수 있습니다!
NBOOST에는 ( nboost-index ) 내장 된 편리한 인덱싱 도구가 있습니다. 시연 목적으로, Nboost를 통해 여행과 호텔에 관한 일련의 구절을 색인화 할 것입니다. 실행하여 Elasticsearch 서버에 인덱스를 추가 할 수 있습니다.
travel.csvNboost와 함께 제공됩니다
nboost-index --file travel.csv --index_name travel --delim , --id_col이제 테스트합시다! Elasticsearch를 누르십시오.
curl " http://localhost:8000/travel/_search?pretty&q=passage:vegas&size=2 " Elasticsearch 결과에 nboost 태그가있는 경우 축하합니다!

Nboost 프론트 엔드를 확인해 봅시다. 브라우저로 이동하여 LocalHost : 8000/nboost를 방문하십시오.
브라우저에 액세스 할 수없는 경우 동일한 정보에 대해
curl http://localhost:8000/nboost/status수 있습니다.
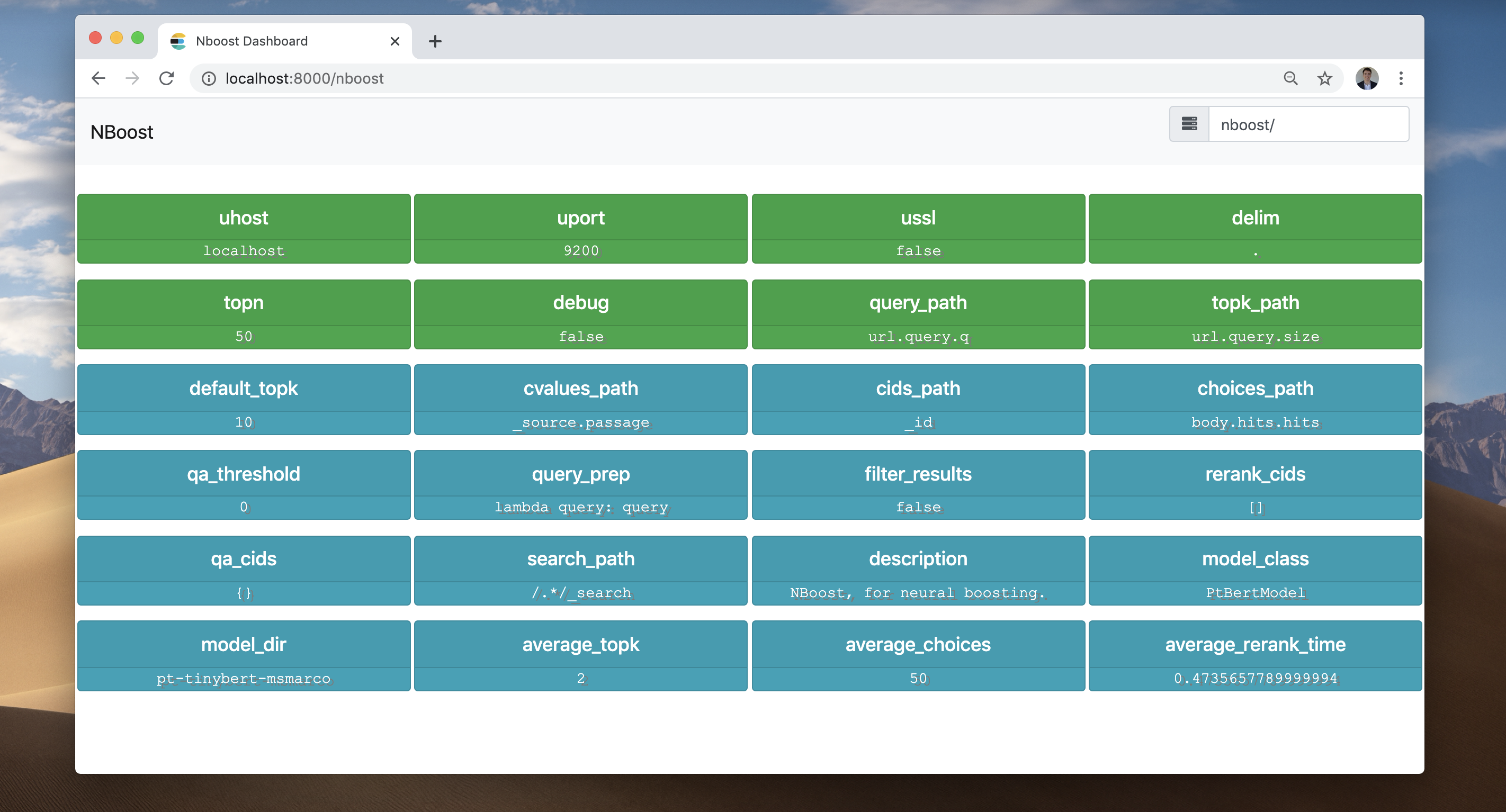
프론트 엔드는 일어난 모든 일을 기록했습니다.
localhost:9200 의 서버에 연결되었습니다. 병렬 프록시의 수를 늘리려면 단순히 --workers 증가시킵니다. 보다 강력한 배포 접근법을 위해서는 Kubernetes를 통해 프록시를 배포 할 수 있습니다 (아래 참조).

심층 쿼리 DSL 및 기타 검색 API 솔루션 (예 : Bing API)은 문서를 참조하십시오.
Helm을 사용하여 Kubernetes 클러스터에 nboost를 쉽게 배포 할 수 있습니다.
먼저 Kubernetes 클러스터에 Repo를 등록해야합니다.
helm repo add nboost https://raw.githubusercontent.com/koursaros-ai/nboost/master/charts/
helm repo update4 개의 복제품을 배포 해 보겠습니다.
helm install --name nboost --set replicaCount=4 nboost/nboost 가능한 모든 --set (values.yaml) 옵션은 다음과 같습니다.
| 매개 변수 | 설명 | 기본 |
|---|---|---|
replicaCount | 배포 할 복제본 수 | 3 |
image.repository | nboost 이미지 이름 | koursaros/nboost |
image.tag | nboost 이미지 태그 | latest-pt |
args.model | 모델 클래스의 이름 | nil |
args.model_dir | Finetuned 모델의 이름 또는 디렉토리 | pt-bert-base-uncased-msmarco |
args.qa | QA 플러그인 사용 여부 | False |
args.qa_model_dir | QA 모델의 이름 또는 디렉토리 | distilbert-base-uncased-distilled-squad |
args.model | 모델 클래스의 이름 | nil |
args.host | 프록시의 호스트 이름 | 0.0.0.0 |
args.port | 프록시가들을 수있는 포트 | 8000 |
args.uhost | 업스트림 검색 API 서버의 호스트 이름 | elasticsearch-master |
args.uport | 업스트림 서버의 포트 | 9200 |
args.data_dir | 캐시 모델 바이너리 디렉토리 | nil |
args.max_seq_len | 최대 결합 토큰 길이 | 64 |
args.bufsize | 바이트의 HTTP 버퍼의 크기 | 2048 |
args.batch_size | 재고 모델을 통해 실행하기위한 배치 크기 | 4 |
args.multiplier | 결과를 증가시키는 요소 | 5 |
args.workers | 프록시를 제공하는 스레드 수 | 10 |
args.query_path | JSONPATH 요청에서 쿼리를 찾으십시오 | nil |
args.topk_path | JSONPATH 요청 된 결과 수를 찾으십시오 | nil |
args.choices_path | JSONPATH를 선택할 수있는 선택의 배열을 찾으십시오 | nil |
args.cvalues_path | JSONPATH 선택의 str 값을 찾으십시오 | nil |
args.cids_path | JSONPATH 선택의 ID를 찾으십시오 | nil |
args.search_path | NBOOST를 통한 재고를위한 URL 경로 | nil |
service.type | Kubernetes 서비스 유형 | LoadBalancer |
resources | POD에 적용해야 할 자원 요구 및 제한 | {} |
nodeSelector | 포드 할당을위한 노드 레이블 | {} |
affinity | 포드 할당에 대한 친화력 설정 | {} |
tolerations | 포드 할당에 대한 허용 레이블 | [] |
image.pullPolicy | 이미지 풀 정책 | IfNotPresent |
imagePullSecrets | Docker Registry 비밀 이름은 배열로 이름입니다 | [] (배포 된 포드에 이미지 풀 비밀을 추가하지 않음) |
nameOverride | Chart.Name을 무시하는 문자열 | nil |
fullnameOverride | string to override Chart.fullName | nil |
serviceAccount.create | 서비스 계정이 작성되었는지 여부를 지정합니다 | nil |
serviceAccount.name | 사용할 서비스 계정의 이름. 설정하지 않고 작성하지 않으면 FullName 템플릿을 사용하여 이름이 생성됩니다. | nil |
serviceAccount.create | 서비스 계정이 작성되었는지 여부를 지정합니다 | nil |
podSecurityContext.fsGroup | 컨테이너의 그룹 ID | nil |
securityContext.runAsUser | 컨테이너의 사용자 ID | 1001 |
ingress.enabled | 수신 자원을 활성화합니다 | false |
ingress.hostName | 설치에 호스트 이름입니다 | nil |
ingress.path | URL 구조 내 경로 | [] |
ingress.tls | TLS로 유입을 활성화하십시오 | [] |
ingress.tls.secretName | TLS 유형 비밀을 사용할 비밀 | chart-example-tls |
공식 nboost 문서는 nboost.readthedocs.io에서 호스팅됩니다. 모든 새 릴리스마다 자동으로 구축, 업데이트 및 보관됩니다.
기부금은 대단히 감사합니다! 수정 또는 업데이트를 작성하여 Nboost에 커밋 할 수 있습니다. 다음은 다음과 같습니다.
fix-nboost-typo-1 만듭니다Fix/model-bert: improve the readability and move sectionsFix/model-bert: improve the readability and move sections 하기 만하면됩니다.자세한 내용은 기고자 가이드 라인에서 찾을 수 있습니다.
학술 논문에서 nboost를 사용한다면 인용되고 싶습니다. 다음은 nboost를 인용하는 두 가지 방법입니다.
footnote{https://github.com/koursaros-ai/nboost}
@misc{koursaros2019NBoost,
title={NBoost: Neural Boosting Search Results},
author={Thienes, Cole and Pertschuk, Jack},
howpublished={ url {https://github.com/koursaros-ai/nboost}},
year={2019}
}Nboost 바이너리 또는 소스 코드의 사본을 다운로드 한 경우 NBOOST BINARY 및 소스 코드는 모두 Apache 라이센스 버전 2.0에 따라 라이센스가 부여됩니다.
Koursaros AI는이 오픈 소스 소프트웨어를 커뮤니티에 가져 오게되어 기쁩니다.

