ulmfit for german
0.1.0
รูปแบบภาษาเยอรมันที่ผ่านการฝึกอบรมมาล่วงหน้าสำหรับ ULMFIT
เนื่องจากภาษาเยอรมันมีความผันผวนมากกว่าภาษาอังกฤษจึงใช้ tokenzation คำย่อยเพื่อแยกข้อความเป็นชิ้น มันใช้ BPEMB รุ่นที่ผ่านการฝึกอบรมมาก่อนโดย Benjamin Heinzerling และ Michael Strube ด้วยขนาดคำศัพท์คงที่ 25K
ตัวอย่างเช่นประโยคภาษาเยอรมันนี้:
'Zeitungskommentare Sind Eine Hervorragende Möglichkeit Zum Meinungsaustausch'
แตกในโทเค็นต่อไปนี้:
['_zeitungs', 'komment', 'are', '_sind', '_eine', '_hervor', 'ragende', '_möglichkeit', '_zum', '_meinungs', 'Austausch'
ดาวน์โหลดรุ่น (~ 350MB) โดยตรงหรือใช้ wget:
wget https://github.com/jfilter/ulmfit-for-german/releases/download/0.1.0/ulmfit_for_german_jfilter.pth from bpemb import BPEmb
from cleantext import clean
from fastai . text import *
# this will download the required model for sub-word tokenization
bpemb_de = BPEmb ( lang = "de" , vs = 25000 , dim = 300 )
# contruct the vocabulary
itos = dict ( enumerate ( bpemb_de . words + [ 'xxpad' ]))
voc = Vocab ( itos )
# encode all tokens as IDs
df_train [ 'text' ]. apply ( lambda x : bpemb_de . encode_ids_with_bos_eos ( clean ( x , lang = 'de' )))
# setup language model data
data_lm = TextLMDataBunch . from_ids ( 'exp' , vocab = voc , train_ids = df_train [ 'text' ], valid_ids = df_valid [ 'text' ])
# setup learner, download the model beforehand
# because of some breaking changes with fastai, change the number of hidden layers. https://github.com/jfilter/ulmfit-for-german/issues/1
config = awd_lstm_lm_config . copy ()
config [ 'n_hid' ] = 1150
learn_lm = language_model_learner ( data_lm , AWD_LSTM , drop_mult = 0.5 , pretrained = False , config = config )
learn_lm . load ( 'ulmfit_for_german_jfilter' ) # the model should be placed here `exp/models/ulmfit_for_german_jfilter.pth`
# ... training language model etc. ...
# setup test classifier data
# NB: set the padding index to 25000 (id of 'xxpad', see above)
classes = df_train [ 'label' ]. unique (). tolist ()
data_clas = TextClasDataBunch . from_ids ( 'exp' , pad_idx = 25000 , vocab = voc , classes = classes ,
train_lbls = df_train [ 'label' ], train_ids = df_train [ 'text' ],
valid_lbls = df_valid [ 'label' ], valid_ids = df_valid [ 'text' ])ดูสมุดบันทึกสำหรับคำแนะนำที่สมบูรณ์ NB: สมุดบันทึกไม่ทำงานด้วยเวอร์ชันล่าสุด The Fastai Library วิธีแก้ไขปัญหานี้
แบบจำลองได้รับการฝึกฝนเกี่ยวกับวิกิพีเดียเยอรมันและเป็นบทความข่าวระดับชาติและระดับภูมิภาคของเยอรมัน มีการเก็บเอกสารที่มีความยาวอย่างน้อย 500 เอกสารเท่านั้น สิ่งนี้ส่งผลให้เป็น 3.278.657 เอกสารที่มีโทเค็น 1.197.060.244 ทั้งหมด 5% ของข้อมูลคือชุดการตรวจสอบความถูกต้อง (สุ่มเลือก) และส่วนที่เหลือคือชุดการฝึกอบรม ในการฝึกอบรมเราจะใช้การกำหนดค่าเริ่มต้นของภาษาอังกฤษ แต่ปิดการใช้งานออกกลางคันอย่างสมบูรณ์ จำนวนข้อมูลมีขนาดใหญ่พอที่ไม่จำเป็นต้องใช้การทำให้เป็นมาตรฐานที่แข็งแกร่ง เราได้รับการฝึกฝนสำหรับห้ายุคที่ใช้เวลาสามวันใน GTX1800TI เดียวโดยมีขนาดแบทช์ 128 อัตราการเรียนรู้จะถูกเลือกโดยตัวค้นหาอัตราการเรียนรู้โดยอัตโนมัติ (0.007 .. ) เส้นโค้งการฝึกอบรมแสดงอยู่ด้านล่างและโมเดลสุดท้ายจะทำให้เกิดความงุนงงของ 32.52 .. ในชุดการตรวจสอบความถูกต้อง
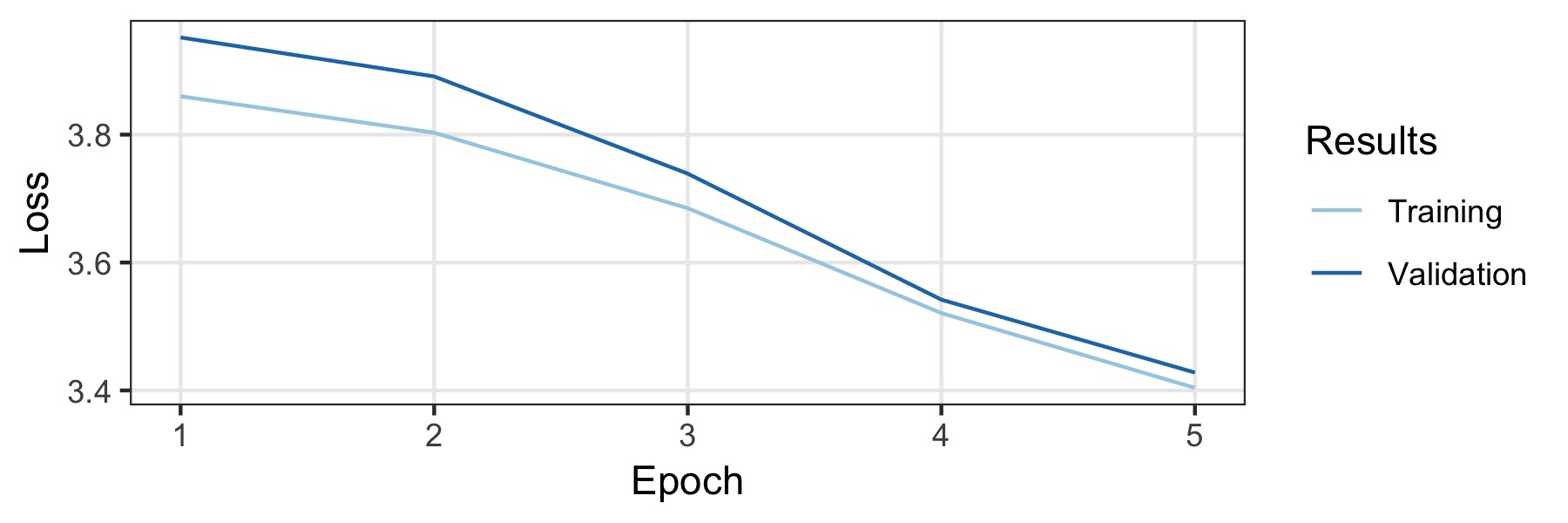
เพื่อทดสอบประสิทธิภาพของแบบจำลองได้ทำการทดลองชุดข้อมูลการทดสอบ 10KGND ชุดข้อมูลประกอบด้วยบทความข่าวเยอรมันประมาณ 10k ใน 9 คลาสที่แตกต่างกัน โมเดลที่ดีที่สุดได้รับการตรวจสอบความถูกต้องและชุดทดสอบ 91% และ 88.3% ตามลำดับ รายละเอียดอยู่ในสมุดบันทึกประกอบ
หากคุณพบว่าแบบจำลอง Langauge มีประโยชน์สำหรับการตีพิมพ์ทางวิชาการโปรดใช้ bibtex ต่อไปนี้เพื่ออ้างอิง:
@misc{ulmfit_german_filter_2019
title={A Pre-trained German Language Model with Sub-word Tokenization for ULMFIT},
author={Johannes Filter},
year={2019},
publisher={GitHub},
howpublished={ url {https://github.com/jfilter/ulmfit-for-german},
}MIT


