ulmfit for german
0.1.0
ULMFIT를위한 미리 훈련 된 독일어 모델.
독일어는 영어보다 더 자극적이기 때문에 하위 단어 토큰 화를 사용하여 텍스트를 덩어리로 나눕니다. Benjamin Heinzerling과 Michael Strube의 미리 훈련 된 모델 BPEMB를 25K의 고정 어휘 크기로 사용합니다.
예를 들어,이 독일 문장 :
'Zeitungskommentare Sind Eine Hervorragende Möglichkeit Zum Meinungsaustausch'
다음 토큰에서 깨졌습니다.
[ '_zeitungs', 'komment', 'are', '_sind', '_eine', '_hervor', 'ragende', '_möglichkeit', '_zum', '_meinungs', 'Austausch', '.'.]
모델 (~ 350MB)을 직접 다운로드하거나 wget을 사용하십시오.
wget https://github.com/jfilter/ulmfit-for-german/releases/download/0.1.0/ulmfit_for_german_jfilter.pth from bpemb import BPEmb
from cleantext import clean
from fastai . text import *
# this will download the required model for sub-word tokenization
bpemb_de = BPEmb ( lang = "de" , vs = 25000 , dim = 300 )
# contruct the vocabulary
itos = dict ( enumerate ( bpemb_de . words + [ 'xxpad' ]))
voc = Vocab ( itos )
# encode all tokens as IDs
df_train [ 'text' ]. apply ( lambda x : bpemb_de . encode_ids_with_bos_eos ( clean ( x , lang = 'de' )))
# setup language model data
data_lm = TextLMDataBunch . from_ids ( 'exp' , vocab = voc , train_ids = df_train [ 'text' ], valid_ids = df_valid [ 'text' ])
# setup learner, download the model beforehand
# because of some breaking changes with fastai, change the number of hidden layers. https://github.com/jfilter/ulmfit-for-german/issues/1
config = awd_lstm_lm_config . copy ()
config [ 'n_hid' ] = 1150
learn_lm = language_model_learner ( data_lm , AWD_LSTM , drop_mult = 0.5 , pretrained = False , config = config )
learn_lm . load ( 'ulmfit_for_german_jfilter' ) # the model should be placed here `exp/models/ulmfit_for_german_jfilter.pth`
# ... training language model etc. ...
# setup test classifier data
# NB: set the padding index to 25000 (id of 'xxpad', see above)
classes = df_train [ 'label' ]. unique (). tolist ()
data_clas = TextClasDataBunch . from_ids ( 'exp' , pad_idx = 25000 , vocab = voc , classes = classes ,
train_lbls = df_train [ 'label' ], train_ids = df_train [ 'text' ],
valid_lbls = df_valid [ 'label' ], valid_ids = df_valid [ 'text' ])완전한 연습은 노트북을 참조하십시오. NB : 노트북은 최신 버전 인 Fastai Library로 실행되지 않습니다. 이것을 고치는 방법.
이 모델은 독일 Wikipedia와 국가 및 지역 독일 뉴스 기사에 대한 교육을 받았습니다. 길이가 500 이상인 문서 만 보관했습니다. 이로 인해 1.197.060.244 토큰이 모두있는 3.278.657 문서가 발생합니다. 데이터의 5%는 검증 세트 (무작위로 선택)이고 나머지는 교육 세트입니다. 이를 훈련시키기 위해 영어의 기본 구성을 사용하지만 드롭 아웃을 완전히 비활성화합니다. 데이터의 양은 충분히 크기 때문에 강력한 정규화가 필요하지 않습니다. 우리는 단일 GTX1800TI에서 3 일이 걸렸으며 배치 크기가 128 인 5 개의 에포크를 훈련 시켰습니다. 학습 속도는 학습 속도 파인더 (0.007 ..)에 의해 자동으로 선택됩니다. 훈련 곡선은 아래에 나와 있으며 최종 모델은 검증 세트에서 32.52의 혼란을 달성합니다.
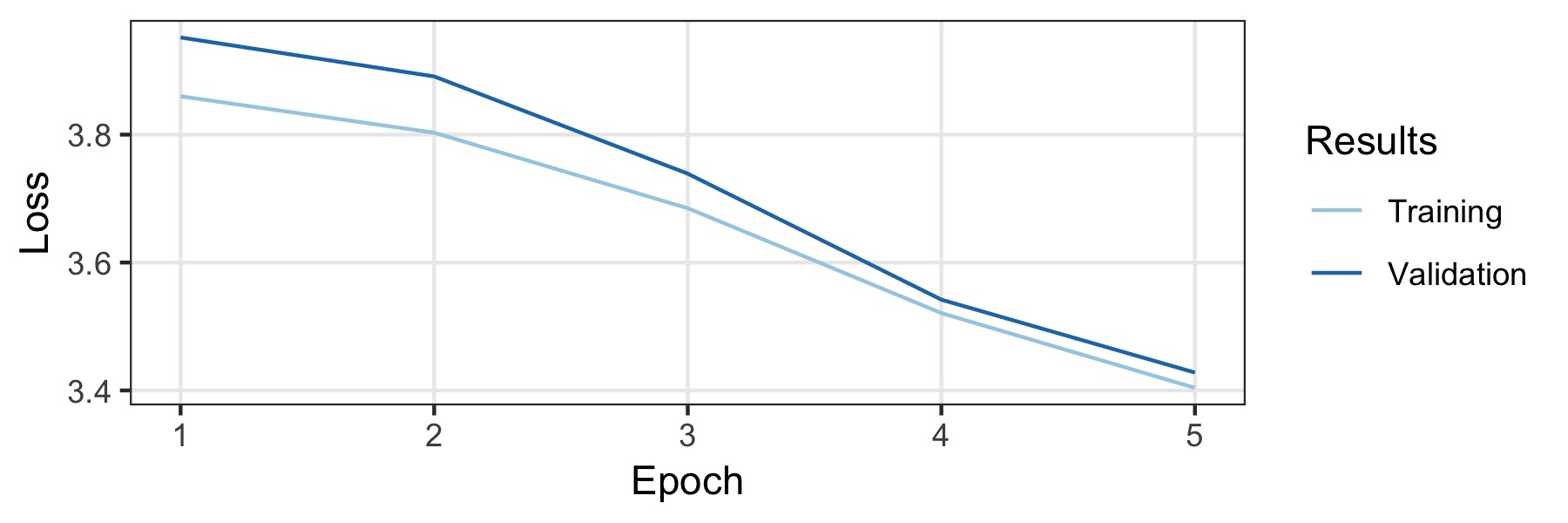
모델의 성능을 테스트하기 위해 실험 데이터 세트 10KGND에 대한 실험이 수행되었습니다. 데이터 세트는 9 개의 다른 클래스의 약 10K 독일 뉴스 기사로 구성됩니다. 최상의 모델은 각각 91% 및 88.3%의 검증 및 테스트 세트에 대한 정확도를 달성했습니다. 세부 사항은 함께 제공되는 노트에 있습니다.
학술 간행물에 유용한 Langauge 모델을 찾으면 다음 Bibtex를 사용하여 인용하십시오.
@misc{ulmfit_german_filter_2019
title={A Pre-trained German Language Model with Sub-word Tokenization for ULMFIT},
author={Johannes Filter},
year={2019},
publisher={GitHub},
howpublished={ url {https://github.com/jfilter/ulmfit-for-german},
}MIT.


