ulmfit for german
0.1.0
Model bahasa Jerman pra-terlatih untuk Ulmfit.
Karena Jerman lebih inflektif daripada bahasa Inggris, ia menggunakan tokenzasi sub-kata untuk membagi teks menjadi potongan-potongan. Ini menggunakan bpemb model pra-terlatih oleh Benjamin Heinzerling dan Michael Strube dengan ukuran kosa kata tetap 25K.
Misalnya, kalimat Jerman ini:
'Zeitungskommentare sind eine hervorragende möglichkeit zum meinungsaustausch'
rusak di token berikut:
['_zeitungs', 'komment', 'adalah', '_sind', '_eine', '_Hervor', 'ragende', '_möglichkeit', '_zum', '_meinungs', 'austausch', '.'
Unduh model (~ 350MB) secara langsung atau gunakan wget:
wget https://github.com/jfilter/ulmfit-for-german/releases/download/0.1.0/ulmfit_for_german_jfilter.pth from bpemb import BPEmb
from cleantext import clean
from fastai . text import *
# this will download the required model for sub-word tokenization
bpemb_de = BPEmb ( lang = "de" , vs = 25000 , dim = 300 )
# contruct the vocabulary
itos = dict ( enumerate ( bpemb_de . words + [ 'xxpad' ]))
voc = Vocab ( itos )
# encode all tokens as IDs
df_train [ 'text' ]. apply ( lambda x : bpemb_de . encode_ids_with_bos_eos ( clean ( x , lang = 'de' )))
# setup language model data
data_lm = TextLMDataBunch . from_ids ( 'exp' , vocab = voc , train_ids = df_train [ 'text' ], valid_ids = df_valid [ 'text' ])
# setup learner, download the model beforehand
# because of some breaking changes with fastai, change the number of hidden layers. https://github.com/jfilter/ulmfit-for-german/issues/1
config = awd_lstm_lm_config . copy ()
config [ 'n_hid' ] = 1150
learn_lm = language_model_learner ( data_lm , AWD_LSTM , drop_mult = 0.5 , pretrained = False , config = config )
learn_lm . load ( 'ulmfit_for_german_jfilter' ) # the model should be placed here `exp/models/ulmfit_for_german_jfilter.pth`
# ... training language model etc. ...
# setup test classifier data
# NB: set the padding index to 25000 (id of 'xxpad', see above)
classes = df_train [ 'label' ]. unique (). tolist ()
data_clas = TextClasDataBunch . from_ids ( 'exp' , pad_idx = 25000 , vocab = voc , classes = classes ,
train_lbls = df_train [ 'label' ], train_ids = df_train [ 'text' ],
valid_lbls = df_valid [ 'label' ], valid_ids = df_valid [ 'text' ])Lihat notebook untuk walkthrough lengkap. NB: Notebook tidak berjalan dengan versi terbaru Perpustakaan Fastai. Cara memperbaikinya.
Model ini dilatih di Wikipedia Jerman dan juga artikel berita Jerman nasional dan regional. Hanya dokumen dengan panjang setidaknya 500 yang disimpan. Ini menghasilkan 3,278.657 dokumen dengan token sama sekali 1.197.060.244. 5% dari data adalah set validasi (dipilih secara acak) dan sisanya adalah set pelatihan. Untuk melatihnya, kami mengambil konfigurasi default bahasa Inggris tetapi sepenuhnya menonaktifkan putus sekolah. Jumlah data yang cukup besar sehingga merupakan regularisasi yang kuat tidak diperlukan. Kami dilatih untuk lima zaman yang memakan waktu tiga hari pada satu GTX1800TI, dengan ukuran batch 128. Tingkat pembelajaran dipilih secara otomatis oleh pencari tingkat pembelajaran (0,007 ..). Kurva pelatihan ditunjukkan di bawah ini dan model akhir mencapai kebingungan 32,52 .. pada set validasi.
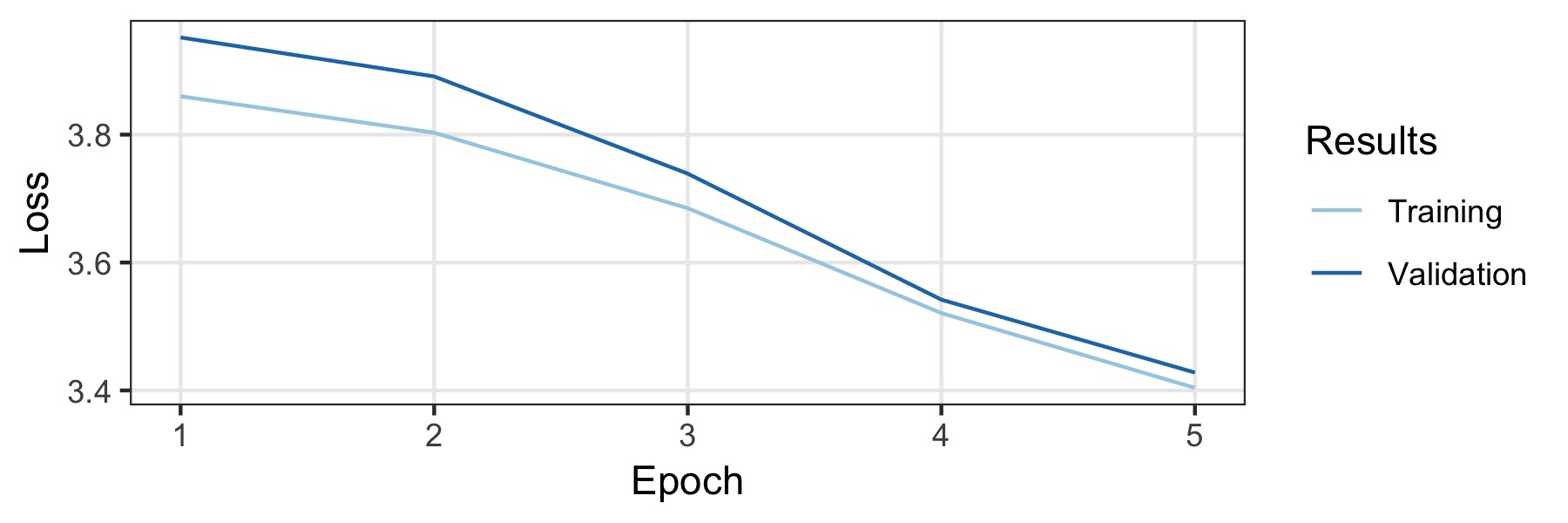
Untuk menguji kinerja model, percobaan pada dataset percobaan 10kGND dilakukan. Dataset terdiri dari sekitar 10k artikel berita Jerman di 9 kelas berbeda. Model terbaik mencapai akuray pada set validasi dan tes masing -masing 91% dan 88,3%. Detailnya ada di buku catatan yang menyertainya.
Jika Anda menemukan model Langauge berguna untuk publikasi akademik, maka silakan gunakan Bibtex berikut untuk mengutipnya:
@misc{ulmfit_german_filter_2019
title={A Pre-trained German Language Model with Sub-word Tokenization for ULMFIT},
author={Johannes Filter},
year={2019},
publisher={GitHub},
howpublished={ url {https://github.com/jfilter/ulmfit-for-german},
}Mit.


