ulmfit for german
0.1.0
ULMFITの事前に訓練されたドイツ語モデル。
ドイツ語は英語よりも流行しているため、サブワードトークンゼーションを使用してテキストをチャンクに分割します。 25kの固定語彙サイズのベンジャミンハインツェルリングとマイケルストルブによる事前に訓練されたモデルBPEMBを使用しています。
たとえば、このドイツの文章:
'Zeitungskommentare Sind einehervorragendemöglichkeitZum meinungsaustausch' '
次のトークンで壊れています:
['_ zeitungs'、 'komment'、 'are'、 '_sind'、 '_ eine'、 '_hervor'、 'ragende'、 '_möglichkeit'、 '_zum'、 '_meinungs'、 'austausch'、 '' ']
モデル(〜350MB)を直接ダウンロードするか、wgetを使用します。
wget https://github.com/jfilter/ulmfit-for-german/releases/download/0.1.0/ulmfit_for_german_jfilter.pth from bpemb import BPEmb
from cleantext import clean
from fastai . text import *
# this will download the required model for sub-word tokenization
bpemb_de = BPEmb ( lang = "de" , vs = 25000 , dim = 300 )
# contruct the vocabulary
itos = dict ( enumerate ( bpemb_de . words + [ 'xxpad' ]))
voc = Vocab ( itos )
# encode all tokens as IDs
df_train [ 'text' ]. apply ( lambda x : bpemb_de . encode_ids_with_bos_eos ( clean ( x , lang = 'de' )))
# setup language model data
data_lm = TextLMDataBunch . from_ids ( 'exp' , vocab = voc , train_ids = df_train [ 'text' ], valid_ids = df_valid [ 'text' ])
# setup learner, download the model beforehand
# because of some breaking changes with fastai, change the number of hidden layers. https://github.com/jfilter/ulmfit-for-german/issues/1
config = awd_lstm_lm_config . copy ()
config [ 'n_hid' ] = 1150
learn_lm = language_model_learner ( data_lm , AWD_LSTM , drop_mult = 0.5 , pretrained = False , config = config )
learn_lm . load ( 'ulmfit_for_german_jfilter' ) # the model should be placed here `exp/models/ulmfit_for_german_jfilter.pth`
# ... training language model etc. ...
# setup test classifier data
# NB: set the padding index to 25000 (id of 'xxpad', see above)
classes = df_train [ 'label' ]. unique (). tolist ()
data_clas = TextClasDataBunch . from_ids ( 'exp' , pad_idx = 25000 , vocab = voc , classes = classes ,
train_lbls = df_train [ 'label' ], train_ids = df_train [ 'text' ],
valid_lbls = df_valid [ 'label' ], valid_ids = df_valid [ 'text' ])完全なウォークスルーについては、ノートブックを参照してください。 NB:ノートブックは最新バージョンのFastaiライブラリで実行されません。これを修正する方法。
このモデルは、ドイツのウィキペディアと、国内および地域のドイツのニュース記事で訓練されました。少なくとも500の長さのドキュメントのみが保持されました。これにより、完全に1.197.060.244トークンを含む3.278.657ドキュメントになります。データの5%は検証セット(ランダムに選択)で、残りはトレーニングセットです。それをトレーニングするために、英語のデフォルトの構成を取りますが、ドロップアウトは完全に無効になります。データの量は十分に大きいので、強力な正則化は必要ありません。 1つのGTX1800TIで3日間かかった5つのエポックのトレーニングを128のバッチサイズで訓練しました。学習率は、学習レートファインダー(0.007 ..)によって自動的に選択されます。トレーニング曲線は以下に示されており、最終モデルは検証セットで32.52 ..の困惑を達成します。
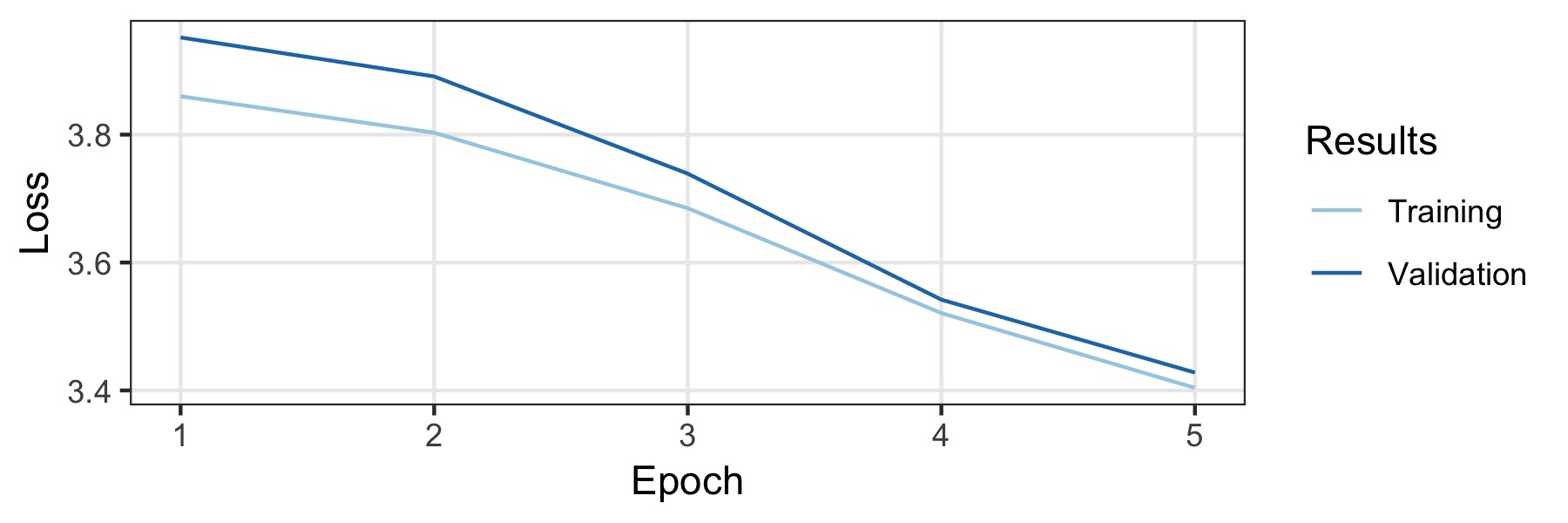
モデルのパフォーマンスをテストするために、実験データセット10KGNDでの実験が実施されました。データセットは、9つの異なるクラスの約10kドイツのニュース記事で構成されています。最良のモデルは、それぞれ91%と88.3%の検証とテストセットの精度を達成しました。詳細は付随するノートブックにあります。
Langaugeモデルがアカデミック出版物に役立つと思う場合は、次のBibtexを使用して引用してください。
@misc{ulmfit_german_filter_2019
title={A Pre-trained German Language Model with Sub-word Tokenization for ULMFIT},
author={Johannes Filter},
year={2019},
publisher={GitHub},
howpublished={ url {https://github.com/jfilter/ulmfit-for-german},
}mit。


