wechsel
1.0.0
รหัสสำหรับ Wechsel: การเริ่มต้นที่มีประสิทธิภาพของการฝังคำใต้คำสำหรับการถ่ายโอนข้ามภาษาของแบบจำลองภาษาภาษาเดียวที่เผยแพร่ที่ NAACL2022
กระดาษ: https://aclanthology.org/2022.naacl-main.293/
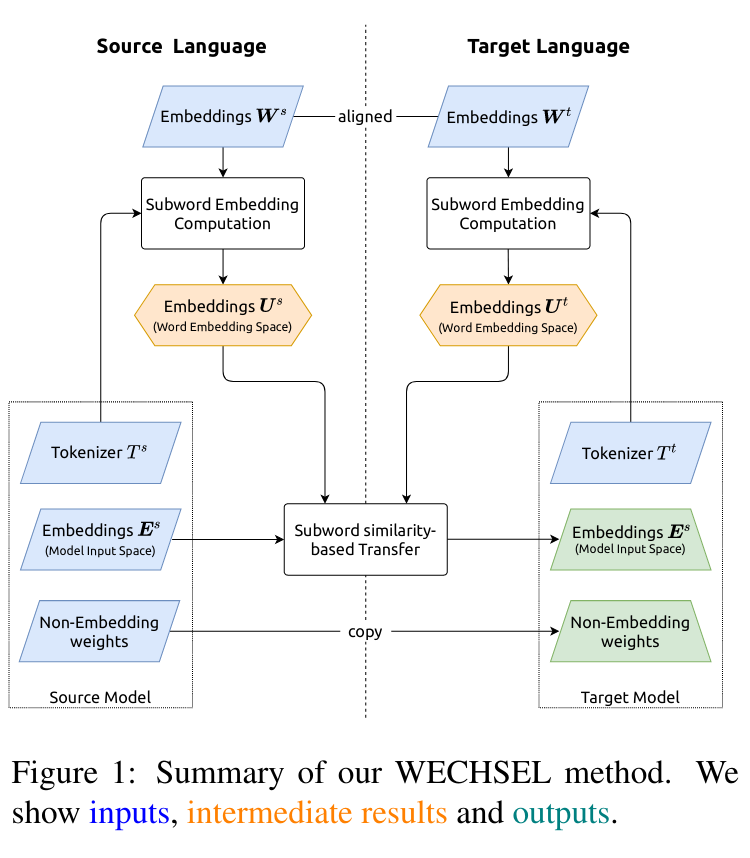
รุ่นจากกระดาษมีอยู่บนฮับ HuggingFace:
roberta-base-wechsel-frenchroberta-base-wechsel-germanroberta-base-wechsel-chineseroberta-base-wechsel-swahiligpt2-wechsel-frenchgpt2-wechsel-germangpt2-wechsel-chinesegpt2-wechsel-swahili เราแจกจ่ายแพ็คเกจ Python ผ่าน PYPI:
pip install wechsel
อีกทางเลือกหนึ่งโคลนที่เก็บ, ติดตั้ง requirements.txt และเรียกใช้รหัสใน wechsel/
การถ่ายโอนภาษาอังกฤษ roberta-base ไปยังภาษาสวาฮิลี:
import torch
from transformers import AutoModel , AutoTokenizer
from datasets import load_dataset
from wechsel import WECHSEL , load_embeddings
source_tokenizer = AutoTokenizer . from_pretrained ( "roberta-base" )
model = AutoModel . from_pretrained ( "roberta-base" )
target_tokenizer = source_tokenizer . train_new_from_iterator (
load_dataset ( "oscar" , "unshuffled_deduplicated_sw" , split = "train" )[ "text" ],
vocab_size = len ( source_tokenizer )
)
wechsel = WECHSEL (
load_embeddings ( "en" ),
load_embeddings ( "sw" ),
bilingual_dictionary = "swahili"
)
target_embeddings , info = wechsel . apply (
source_tokenizer ,
target_tokenizer ,
model . get_input_embeddings (). weight . detach (). numpy (),
)
model . get_input_embeddings (). weight . data = torch . from_numpy ( target_embeddings )
model . config . vocab_size = len ( target_embeddings )
# if the model has separate output embeddings, also copy those
if not model . config . tie_word_embeddings :
target_out_embeddings , info = wechsel . apply (
source_tokenizer ,
target_tokenizer ,
model . get_output_embeddings (). weight . detach (). numpy (),
)
model . get_output_embeddings (). weight . data = torch . from_numpy ( target_out_embeddings )
# use `model` and `target_tokenizer` to continue training in Swahili! เราแจกจ่ายพจนานุกรมสองภาษา 3276 จากภาษาอังกฤษไปยังภาษาอื่น ๆ เพื่อใช้กับ Wechsel ใน dicts/
กรุณาอ้างอิง Wechsel เป็น
@inproceedings{minixhofer-etal-2022-wechsel,
title = "{WECHSEL}: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models",
author = "Minixhofer, Benjamin and
Paischer, Fabian and
Rekabsaz, Navid",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.293",
pages = "3992--4006",
abstract = "Large pretrained language models (LMs) have become the central building block of many NLP applications. Training these models requires ever more computational resources and most of the existing models are trained on English text only. It is exceedingly expensive to train these models in other languages. To alleviate this problem, we introduce a novel method {--} called WECHSEL {--} to efficiently and effectively transfer pretrained LMs to new languages. WECHSEL can be applied to any model which uses subword-based tokenization and learns an embedding for each subword. The tokenizer of the source model (in English) is replaced with a tokenizer in the target language and token embeddings are initialized such that they are semantically similar to the English tokens by utilizing multilingual static word embeddings covering English and the target language. We use WECHSEL to transfer the English RoBERTa and GPT-2 models to four languages (French, German, Chinese and Swahili). We also study the benefits of our method on very low-resource languages. WECHSEL improves over proposed methods for cross-lingual parameter transfer and outperforms models of comparable size trained from scratch with up to 64x less training effort. Our method makes training large language models for new languages more accessible and less damaging to the environment. We make our code and models publicly available.",
}
การวิจัยสนับสนุนด้วยคลาวด์ TPU จาก TPU Research Cloud (TRC) ของ Google เราขอขอบคุณ Andy Koh และ Artus Krohn-Grimberghe สำหรับการจัดหาทรัพยากรการคำนวณเพิ่มเติม Ellis Unit Linz, Lit AI Lab, สถาบันเพื่อการเรียนรู้ของเครื่องจักรได้รับการสนับสนุนโดยรัฐกลางออสเตรียตอนบน เราขอขอบคุณโครงการ Incontrol-RL (FFG-881064)


