wechsel
1.0.0
WeChel 코드 : NAACL2022에 발표 된 단일 언어 모델의 교차 전송을위한 서브 워드 임베딩의 효과적인 초기화.
종이 : https://aclanthology.org/2022.naacl-main.293/
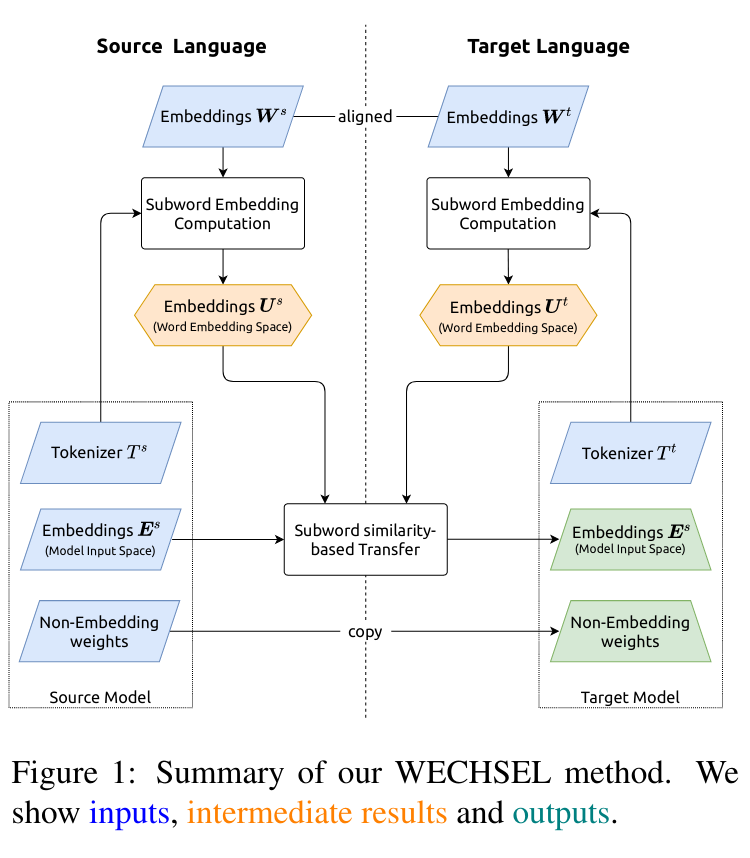
논문의 모델은 Huggingface Hub에서 제공됩니다.
roberta-base-wechsel-frenchroberta-base-wechsel-germanroberta-base-wechsel-chineseroberta-base-wechsel-swahiligpt2-wechsel-frenchgpt2-wechsel-germangpt2-wechsel-chinesegpt2-wechsel-swahili PYPI를 통해 파이썬 패키지를 배포합니다.
pip install wechsel
또는 저장소를 복제하고 requirements.txt 설치하고 wechsel/ 에서 코드를 실행하십시오.
영어 roberta-base Swahili로 옮기기 :
import torch
from transformers import AutoModel , AutoTokenizer
from datasets import load_dataset
from wechsel import WECHSEL , load_embeddings
source_tokenizer = AutoTokenizer . from_pretrained ( "roberta-base" )
model = AutoModel . from_pretrained ( "roberta-base" )
target_tokenizer = source_tokenizer . train_new_from_iterator (
load_dataset ( "oscar" , "unshuffled_deduplicated_sw" , split = "train" )[ "text" ],
vocab_size = len ( source_tokenizer )
)
wechsel = WECHSEL (
load_embeddings ( "en" ),
load_embeddings ( "sw" ),
bilingual_dictionary = "swahili"
)
target_embeddings , info = wechsel . apply (
source_tokenizer ,
target_tokenizer ,
model . get_input_embeddings (). weight . detach (). numpy (),
)
model . get_input_embeddings (). weight . data = torch . from_numpy ( target_embeddings )
model . config . vocab_size = len ( target_embeddings )
# if the model has separate output embeddings, also copy those
if not model . config . tie_word_embeddings :
target_out_embeddings , info = wechsel . apply (
source_tokenizer ,
target_tokenizer ,
model . get_output_embeddings (). weight . detach (). numpy (),
)
model . get_output_embeddings (). weight . data = torch . from_numpy ( target_out_embeddings )
# use `model` and `target_tokenizer` to continue training in Swahili! 우리는 3276 개의 이중 언어 사전을 영어에서 다른 언어로 배포하여 wechsel in dicts/ 를 사용합니다.
Wechsel을 인용하십시오
@inproceedings{minixhofer-etal-2022-wechsel,
title = "{WECHSEL}: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models",
author = "Minixhofer, Benjamin and
Paischer, Fabian and
Rekabsaz, Navid",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.293",
pages = "3992--4006",
abstract = "Large pretrained language models (LMs) have become the central building block of many NLP applications. Training these models requires ever more computational resources and most of the existing models are trained on English text only. It is exceedingly expensive to train these models in other languages. To alleviate this problem, we introduce a novel method {--} called WECHSEL {--} to efficiently and effectively transfer pretrained LMs to new languages. WECHSEL can be applied to any model which uses subword-based tokenization and learns an embedding for each subword. The tokenizer of the source model (in English) is replaced with a tokenizer in the target language and token embeddings are initialized such that they are semantically similar to the English tokens by utilizing multilingual static word embeddings covering English and the target language. We use WECHSEL to transfer the English RoBERTa and GPT-2 models to four languages (French, German, Chinese and Swahili). We also study the benefits of our method on very low-resource languages. WECHSEL improves over proposed methods for cross-lingual parameter transfer and outperforms models of comparable size trained from scratch with up to 64x less training effort. Our method makes training large language models for new languages more accessible and less damaging to the environment. We make our code and models publicly available.",
}
Google의 TPU Research Cloud (TRC)의 Cloud TPU를 지원하는 연구. 추가 계산 자원을 제공해 주신 Andy Koh와 Artus Krohn-Grimberghe에게 감사드립니다. 기계 학습 연구소 인 Lit AI Lab 인 Ellis Unit Linz는 Federal State Upper Austria의 지원을받습니다. 프로젝트 Incontrol-RL (FFG-881064)에 감사드립니다.


