persian tts
Initial Android release

เปอร์เซีย TTS เป็นเครื่องยนต์สังเคราะห์แบบข้อความและแอพพลิเคชั่นที่มีปฏิกิริยาต่อการพูดคุยอย่างง่ายซึ่งฉันได้พัฒนาเป็นโครงการสำเร็จการศึกษาระดับปริญญาตรีของฉันในขั้นต้น
อย่างไรก็ตามโครงการนี้มีไว้เพื่อให้ได้รับการปรับปรุงอย่างค่อยเป็นค่อยไปเมื่อเวลาผ่านไป
![]()
![]()
![]()
แอพ Persian-TTS ใช้พลังงานจาก React Native ดังนั้นคุณจะต้องใช้มันสำหรับการรวบรวมแอพอย่างถูกต้อง ในการรวบรวมเวอร์ชัน Android การมี Android SDK ที่เหมาะสมบนเครื่องของคุณเป็นสิ่งที่จำเป็นและการรวบรวม iOS Varient ต้องการให้คุณมีสำเนา Xcode ที่ใช้งานได้และเครื่องมือการจัดการการพึ่งพา Cocoapods ที่ใช้งานได้บนเครื่องจักรที่ใช้พลังงานจาก MacOS
คุณจะต้องมีเครื่องมือการจัดการการพึ่งพาสำหรับการเข้าถึง NPM และดาวน์โหลดการพึ่งพาของโครงการ เส้นด้ายถูกใช้ในโครงการนี้ แต่สามารถใช้ NPM หรือเครื่องมืออื่น ๆ ได้
ก่อนอื่นคุณสามารถรับซอร์สโค้ดได้โดยโคลน
git clone [email protected]:amfolio/persian-tts.git cd ios
pod install จากนั้นย้ายไปที่ไดเรกทอรีของแพ็คเกจและติดตั้งการพึ่งพาโดยใช้ yarn install หรือ npm install
ในการเปิดใช้แอพในระบบปฏิบัติการ Android และ/หรือ iOS คุณสามารถใช้คำสั่งต่อไปนี้:
react-native run-androidreact-native run-iosโครงสร้างของโครงการนี้เหมือนกับโครงสร้างโครงการอื่น ๆ อีกมากมาย ด้านล่างเป็นเพียงภาพใหญ่ของโครงสร้างหลัก:
ในไม่ช้าโครงการใช้ "การสังเคราะห์ concatnative" อนุมัติเพื่อให้บรรลุเป้าหมาย ในภาษาเปอร์เซียชุดคำไม่ จำกัด สามารถสร้างได้โดยคู่ "พยัญชนะ+เสียงสระ" concatnating สำหรับความกล้าหาญที่นี่เราเรียกคู่เหล่านี้เพียงแค่ "พยางค์"
เพื่อให้การสังเคราะห์ทำงานโครงการได้เริ่มต้นชุดเสียงพยางค์ 169 ชุดที่บันทึกจากเสียงของฉันเอง (ดังนั้นจึงไม่ใช่คำบรรยายระดับมืออาชีพ?) หมายเลขนี้ถูกเบี่ยงเบนเป็นตะโกน:
| ประเภทเสียง | จำนวนไฟล์ที่เกี่ยวข้อง |
|---|---|
| สระ | 6 |
| พยัญชนะเงียบ | 23 |
| พยางค์ (พยัญชนะ+สระ) | 138 |
| ช่องว่าง | 2 |
| ทั้งหมด | 169 |
กระบวนการสังเคราะห์นั้นเป็นไปได้โดยการเชื่อมต่อพยางค์โดยใช้ไลบรารี FFMPEG และเป็น wrapper React-Native-FFMPEG นี่คือสคีมาอย่างรวดเร็วของสิ่งที่เกิดขึ้น
ในขั้นตอนแรกการออกเสียงที่สอดคล้องกันสำหรับอินพุตเปอร์เซียถูกสร้างขึ้นโดยใช้ฟังก์ชั่นยูทิลิตี้ texttophonems
const input = "سلام" ; // means "Hello" in persian
const output = textToPhonems ( input ) ; // ["sa", "lā", "m"];ผลลัพธ์ของขั้นตอนที่ 1 ผ่านฟังก์ชั่นยูทิลิตี้ phonemstoffmpeg และได้รับคำสั่ง ffmpeg concatnation ที่ถูกต้อง:
const ffmpeg = phonemsToFFMpeg ( output ) ;และผลลัพธ์จะเป็น:
ffmpeg
-I sa.wav -I lā.wav -I m.wav
-filter_complex ‘[0:0][1:0][2:0]concat=n=3:v=0:a=1[out]’
-map ‘[out]’ output.wavแอปพลิเคชันเรียก FFMPEG โดยใช้ React-Native-FFMPEG และขั้นตอนต่อไปนี้จะเสร็จสิ้นเบื้องหลัง:
| ก่อนเข้าร่วม | ||
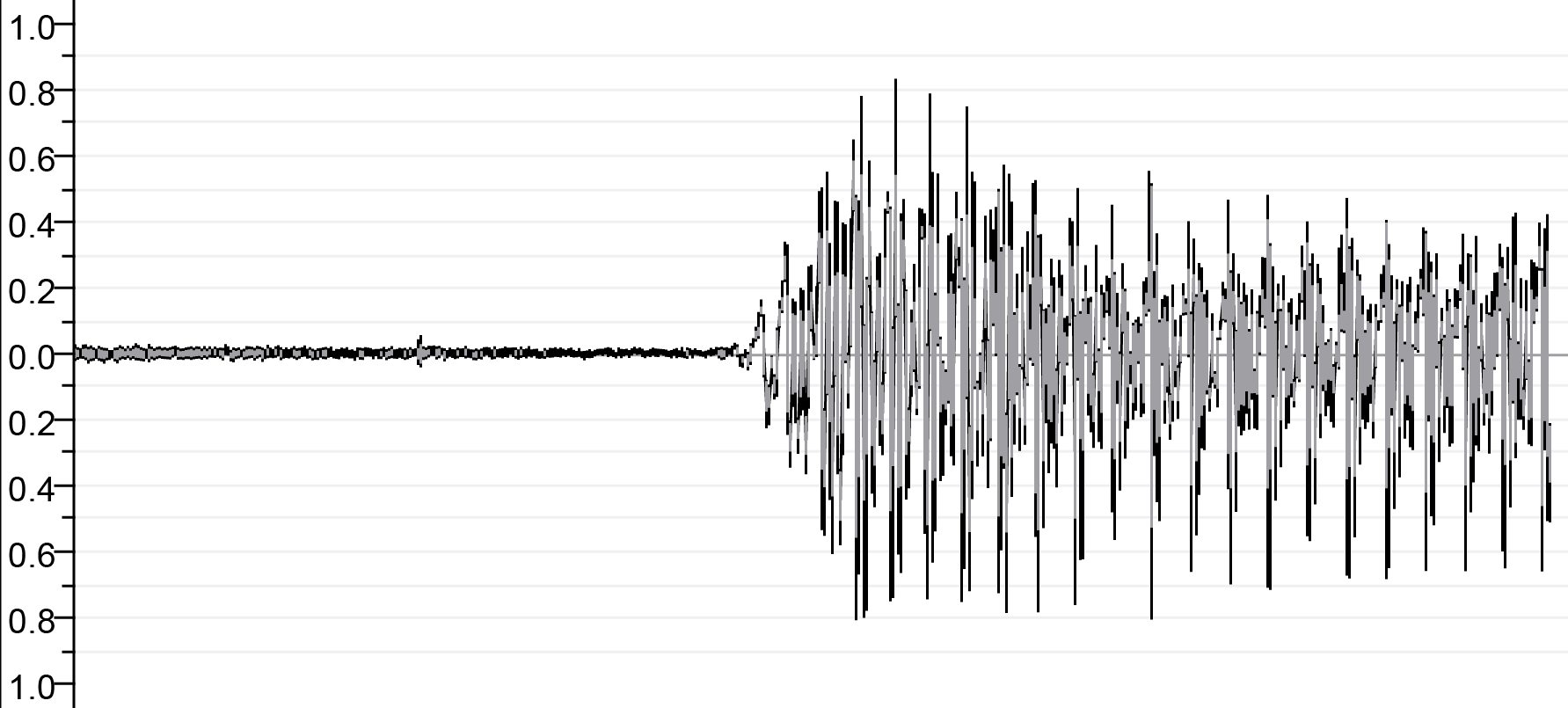 | 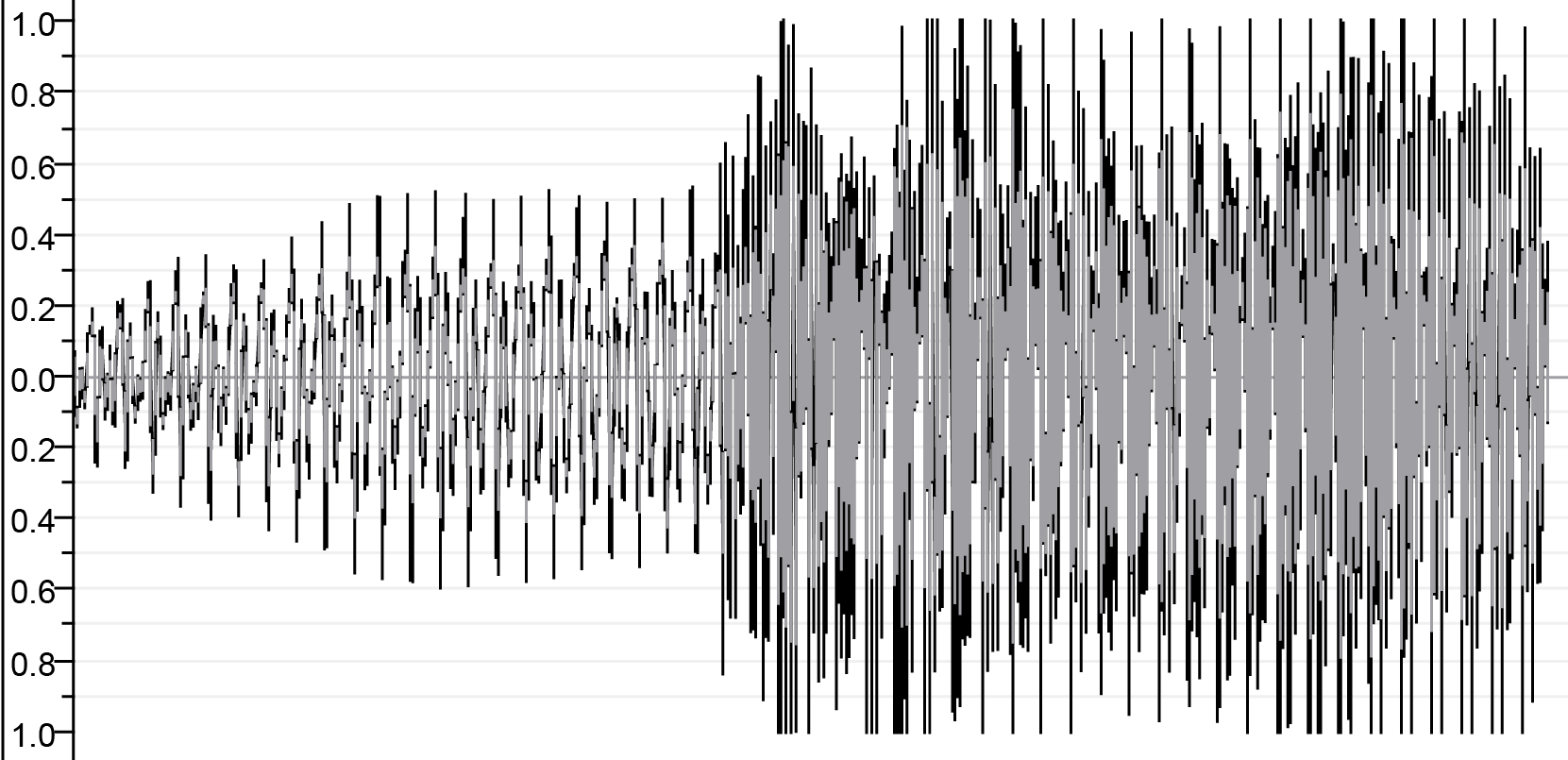 |  |
| Sa.wav | Lā.wav | M.WAV |
| หลังการรวมกัน | ||
 | ||
| เอาท์พุท. wav | ||
ไฟล์เสียงเอาท์พุทจะเล่นได้ทั้งแพลตฟอร์ม iOS และ Android ต้องขอบคุณไลบรารี React-Native-Sound การอ่านแหล่งข้อมูลชุดและการถ่ายโอนไปยังที่ตั้ง Sandbox/SD-Card ก็เป็นไปได้ด้วยการตอบสนองของ Native-Fs
คำขอบคุณเป็นพิเศษไปที่ผู้อำนวยการโครงการของฉันดร. โมฮัมหมัด Taheri ผู้ให้ความมั่นใจในการเข้าใกล้เรื่องนี้และนำทางฉันผ่านขั้นตอนที่ดีที่สุดเพื่อให้เป็นไปได้ ถ้าไม่มีเขาฉันอาจจะไม่เคยไปงานวิจัยทางวิชาการเช่นนี้
การขอบคุณครั้งใหญ่ครั้งต่อไปคือชุมชนนักพัฒนาที่แบ่งปันเทคโนโลยีที่ทันสมัยกับผู้อื่นอย่างใจกว้าง มันเป็นเพียงแค่ต้องขอบคุณชุมชนนี้ที่สร้างล้อใหม่ไม่จำเป็นอีกต่อไป
นี่คือรายการสั้น ๆ ของห้องสมุดที่ช่วยฉันอย่างไม่สิ้นสุดในเส้นทางการพัฒนาของฉัน:
ที่เก็บนี้ถูกสร้างขึ้นในขั้นต้นเป็นความพยายามขั้นต่ำสำหรับโซลูชันการพูดแบบข้อความภาษาเปอร์เซียแบบโอเพนซอร์สเป็นคำพูด ฉันจะรู้สึกขอบคุณอย่างมากกับการมีส่วนร่วมใด ๆ จากปัญหาการรายงานไปจนถึงการแก้ไขข้อผิดพลาดและการปรับปรุง
การมีส่วนร่วมโดยการเพิ่มเสียงเพิ่มเติมในโครงการยังได้รับการต้อนรับอย่างมากและคุณยังสามารถพูดถึงชื่อของคุณใน Voices.json
โปรดส่งคำขอดึงในกรณีที่รู้สึกจำเป็น


