persian tts
Initial Android release

Persian TTS est un simple moteur de synthèse de texte à vitesses et une application réactive que j'ai initialement développée en tant que projet de remise des diplômes de baccalauréat.
Le projet est cependant destiné à obtenir des améliorations progressives au fil du temps.
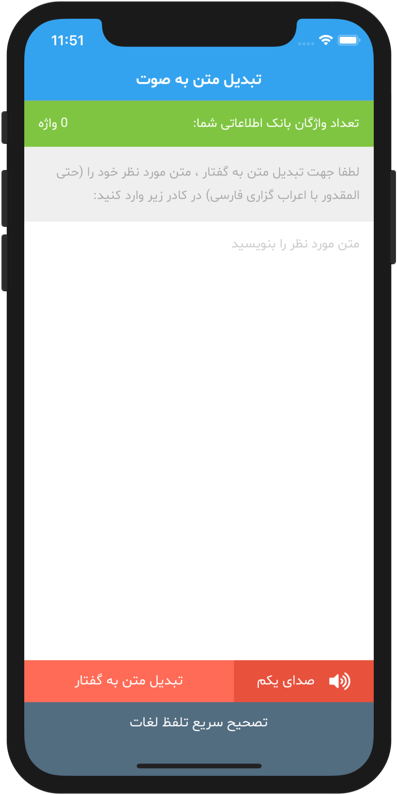
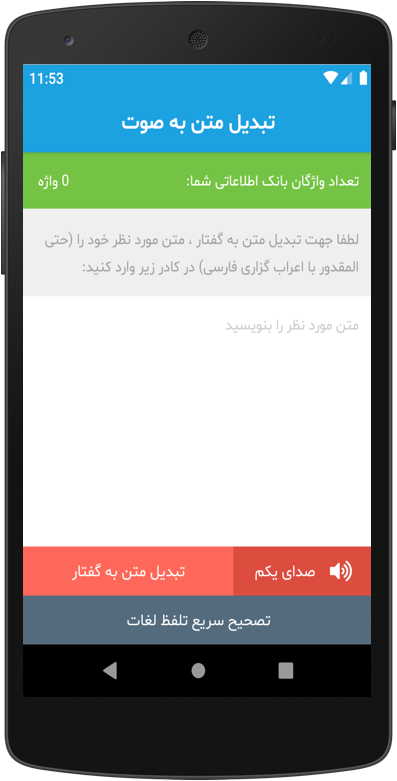
![]()
![]()
![]()
Les applications Persian-TTS sont alimentées par React Native, vous en aurez donc besoin pour compiler correctement les applications. Pour compiler la version Android, avoir un SDK Android approprié sur votre machine est un incontournable et la compilation de variéments iOS a évidemment besoin que vous ayez une copie Xcode de travail et un outil fonctionnel de gestion de la dépendance à cocoapodes sur une machine à système d'exploitation macOS.
Vous devrez également avoir un outil de gestion des dépendances pour accéder au NPM et télécharger les dépendances du projet. Le fil est utilisé dans ce projet, mais NPM ou d'autres outils pourraient également être utilisés.
Vous pouvez d'abord obtenir le code source en le clonant
git clone [email protected]:amfolio/persian-tts.git cd ios
pod install Ensuite, passez au répertoire du package et installez ses dépendances à l'aide de yarn install ou npm install
Pour lancer des applications dans des émulateurs de systèmes d'exploitation Android et / ou iOS, vous pouvez utiliser les commandes suivantes:
react-native run-androidreact-native run-iosLa structure de ce projet est tout simplement identique à de nombreuses autres structures de projet réactif. Vous trouverez ci-dessous une vue d'ensemble de la structure principale:
Peu de temps, le projet utilise un «synthétisant concatnatif» pour atteindre son objectif. En langue persane, un ensemble de mots illimité pourrait être construit en concatnation des paires "consonne + voyelle". Pour Bravity ici, nous appelons ces paires simplement "Syllabes".
Pour faire fonctionner la synthèse, le projet a initialement un ensemble de 169 voix de syllabes, recodés de ma propre voix (donc ce n'est pas une narration professionnelle?). Ce nombre est dévoué comme ci-dessous:
| Type de voix | Nombre de fichiers correspondant |
|---|---|
| voyelles | 6 |
| consonnes silencieuses | 23 |
| syllabe (consonne + voyelle) | 138 |
| espaces | 2 |
| Total | 169 |
Le processus de synthèse est ensuite possible en concatnation des syllabes à l'aide de la bibliothèque FFMPEG et son wrapper React-Native-FFMPEG. Voici un schéma rapide de ce qui se passe.
Dans la première étape, la correspondance phonétique pour l'entrée persane est créée à l'aide de la fonction d'utilité TextTophonems.
const input = "سلام" ; // means "Hello" in persian
const output = textToPhonems ( input ) ; // ["sa", "lā", "m"];Le résultat de l'étape 1 passe par la fonction d'utilité PhonemStoffmpeg et obtient une commande de concatnation FFMPEG valide:
const ffmpeg = phonemsToFFMpeg ( output ) ;Et le résultat serait:
ffmpeg
-I sa.wav -I lā.wav -I m.wav
-filter_complex ‘[0:0][1:0][2:0]concat=n=3:v=0:a=1[out]’
-map ‘[out]’ output.wavL'application appelle FFMPEG à l'aide de React-Native-FFMPEG et les étapes suivantes sont effectuées dans les coulisses:
| Avant la concatnation | ||
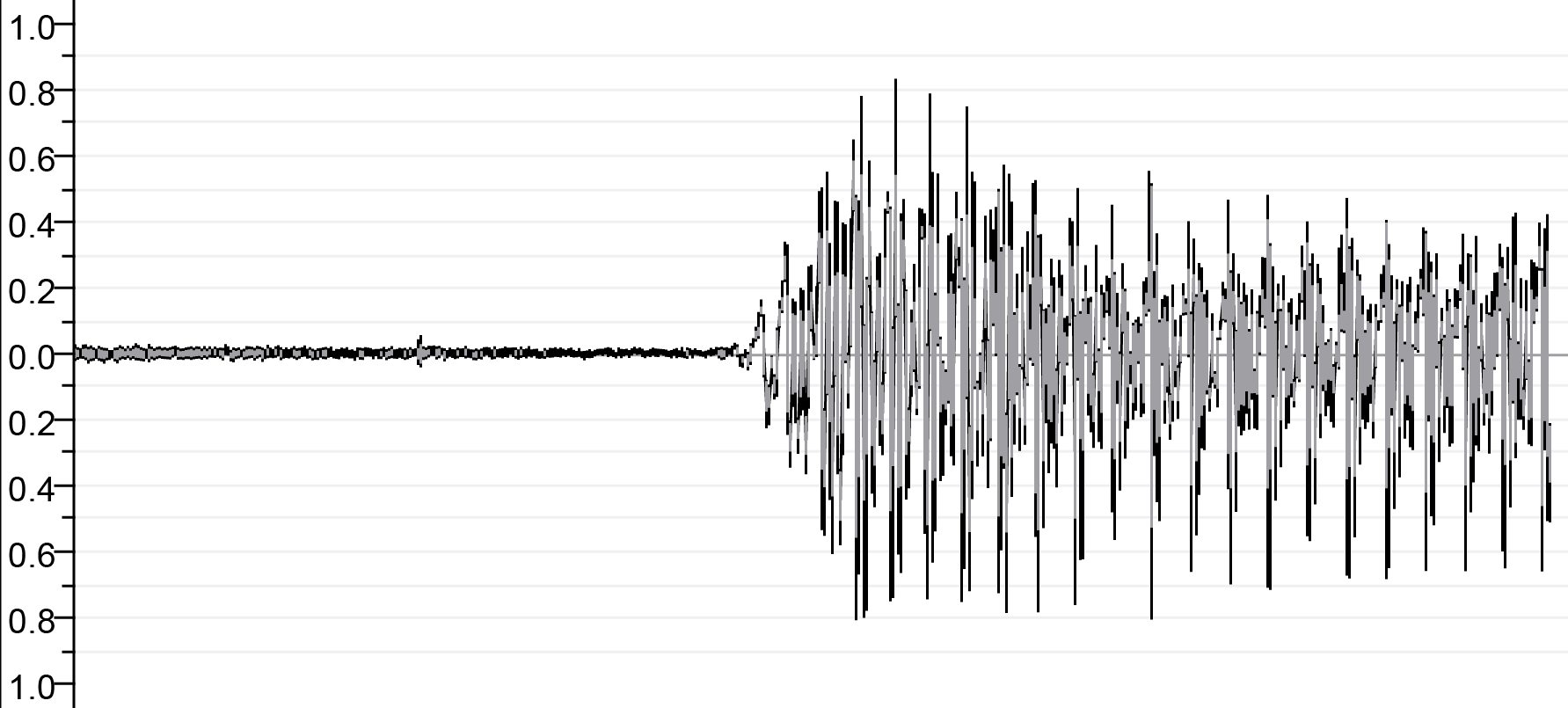 | 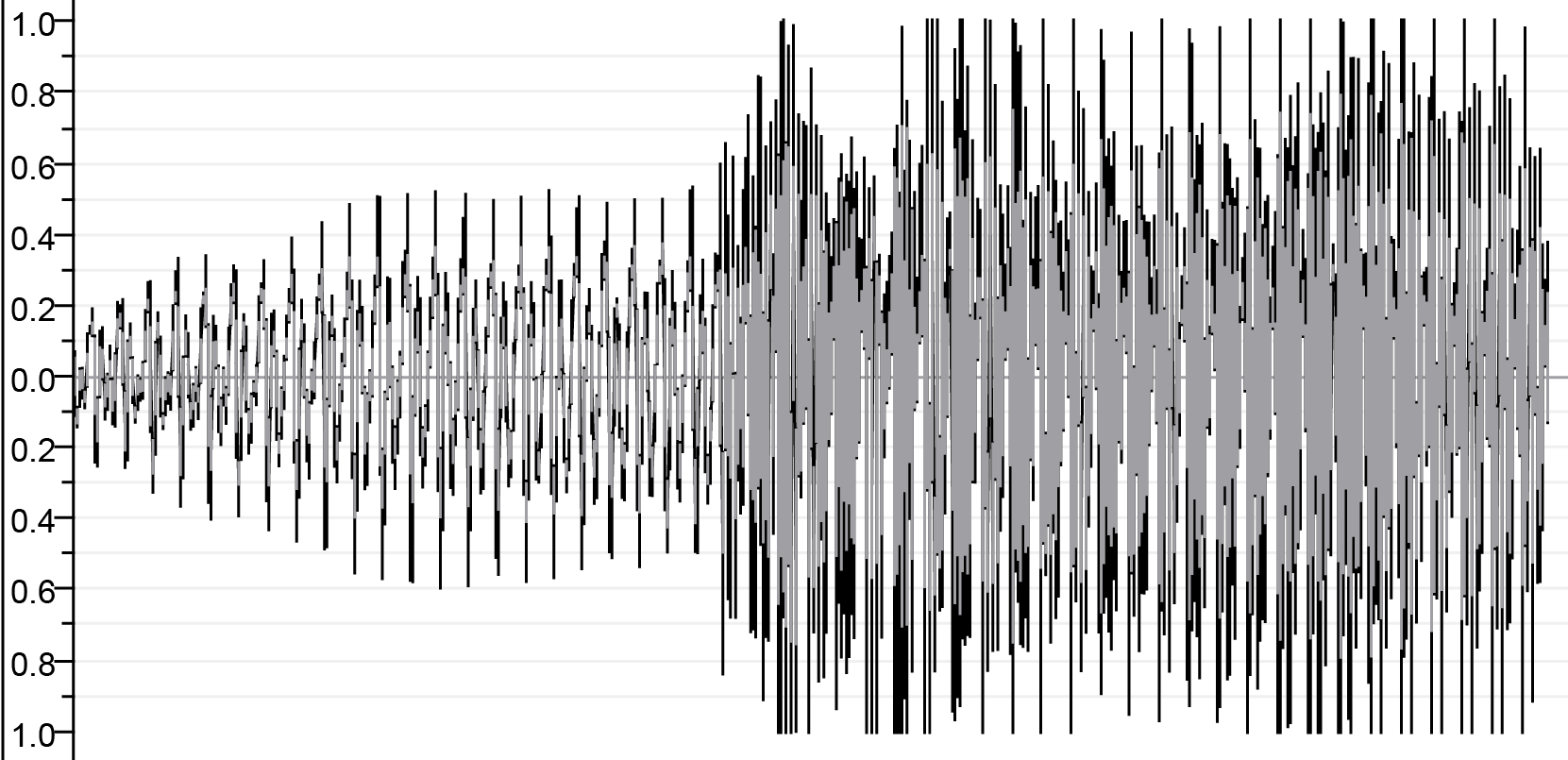 | 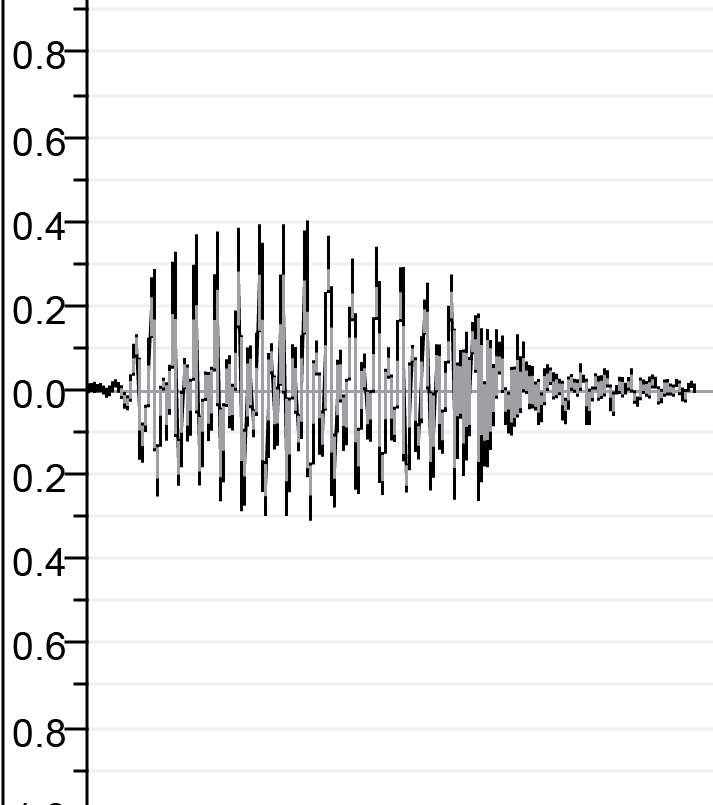 |
| SA.WAV | lā.wav | m.wav |
| Après la concatnation | ||
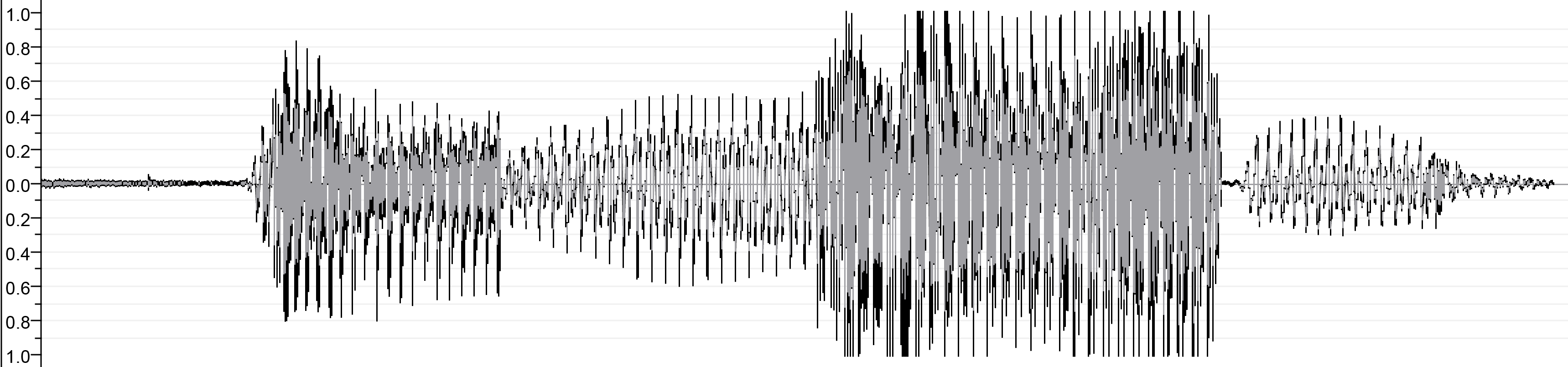 | ||
| output.wav | ||
Le fichier audio de sortie est lu sur les plates-formes iOS et Android grâce à la bibliothèque React-Native-Sound. La lecture des ressources du bundle et les transférer à Sandbox / SD-Card Emplacement est également possible grâce à React-Native-FS
Le remerciement spécial va au directeur de mon projet, le Dr Mohammad Taheri qui m'a donné la confiance d'approcher ce sujet et m'a guidé à travers les meilleures étapes pour le rendre possible. Sans lui, je n'aurais probablement jamais eu de recherches académiques.
Les prochains remerciements vont à la communauté des développeurs qui partagent généreusement la technologie de pointe avec les autres. C'est simplement grâce à cette communauté que la réinventure des roues n'est plus nécessaire.
Voici une courte liste de bibliothèques qui m'ont aidé à l'infini dans mon chemin de développement:
Ce référentiel est initialement construit comme un effort minimum pour une solution de texte vocale open-source persan. Je serais très reconnaissant de toute contribution des problèmes signalant aux bugfix et améliorations.
La contribution en ajoutant plus de voix au projet est également très bien accueillie et vous pouvez également mentionner votre nom dans Voices.json.
N'hésitez pas à envoyer des demandes de traction en cas de nécessité.


