persian tts
Initial Android release

TTS Persia adalah mesin sintesis teks-ke-speach sederhana dan aplikasi reaktif yang awalnya saya kembangkan sebagai proyek kelulusan gelar sarjana saya.
Namun proyek ini dimaksudkan untuk mendapatkan perbaikan bertahap dari waktu ke waktu.
![]()
![]()
![]()
Aplikasi Persia-TTS didukung oleh React Native sehingga Anda akan membutuhkannya untuk menyusun aplikasi dengan benar. Untuk mengkompilasi versi Android, memiliki SDK Android yang tepat di mesin Anda adalah suatu keharusan dan jelas menyusun varient iOS membutuhkan Anda untuk memiliki salinan xcode yang berfungsi dan alat manajemen ketergantungan Cocoapods fungsional pada mesin bertenaga sistem operasi macOS.
Anda juga perlu memiliki alat manajemen ketergantungan untuk mengakses NPM dan mengunduh dependensi proyek. Benang digunakan dalam proyek ini tetapi NPM atau alat lain juga dapat digunakan.
Pertama, Anda bisa mendapatkan kode sumber dengan mengkloningnya
git clone [email protected]:amfolio/persian-tts.git cd ios
pod install Kemudian pindah ke direktori paket dan instal dependensi menggunakan yarn install atau npm install
Untuk meluncurkan aplikasi dalam emulator sistem operasi Android dan/atau iOS, Anda dapat menggunakan perintah berikut:
react-native run-androidreact-native run-iosStruktur proyek ini hanya identik dengan banyak struktur proyek reaknatif lainnya. Di bawah ini hanyalah gambaran besar dari struktur utama:
Singkatnya proyek menggunakan apprach "concatnative sintesizing" untuk mencapai tujuannya. Dalam bahasa Persia, serangkaian kata yang tidak terbatas dapat dibangun dengan menyatukan pasangan "konsonan+vokal". Untuk keberanian di sini kita menyebut pasangan ini hanya "suku kata".
Untuk membuat sintesis berfungsi, proyek ini awalnya memiliki seperangkat 169 suara suku kata, dikodekan ulang dari suara saya sendiri (jadi ini bukan narasi profesional?). Nomor ini diselesaikan sebagai di bawah:
| Jenis suara | Hitung file yang sesuai |
|---|---|
| vokal | 6 |
| konsonan diam | 23 |
| suku kata (konsonan+vokal) | 138 |
| ruang | 2 |
| Total | 169 |
Proses sintesis kemudian dapat dilakukan dengan menggabungkan suku kata menggunakan pustaka FFMPEG dan itu adalah pembungkus FFFMPEG yang bereaksi-asli. Berikut adalah skema cepat tentang apa yang terjadi.
Pada langkah pertama, fonetik yang sesuai untuk input Persia dibuat menggunakan fungsi utilitas TextTophonems.
const input = "سلام" ; // means "Hello" in persian
const output = textToPhonems ( input ) ; // ["sa", "lā", "m"];Hasil dari langkah 1 melewati fungsi utilitas phonemstoffmpeg dan mendapatkan perintah contatnation ffmpeg yang valid:
const ffmpeg = phonemsToFFMpeg ( output ) ;Dan hasilnya adalah:
ffmpeg
-I sa.wav -I lā.wav -I m.wav
-filter_complex ‘[0:0][1:0][2:0]concat=n=3:v=0:a=1[out]’
-map ‘[out]’ output.wavAplikasi memanggil FFMPEG menggunakan react-native-FFFMPEG dan langkah-langkah berikut dilakukan di belakang layar:
| Sebelum pengkhianatan | ||
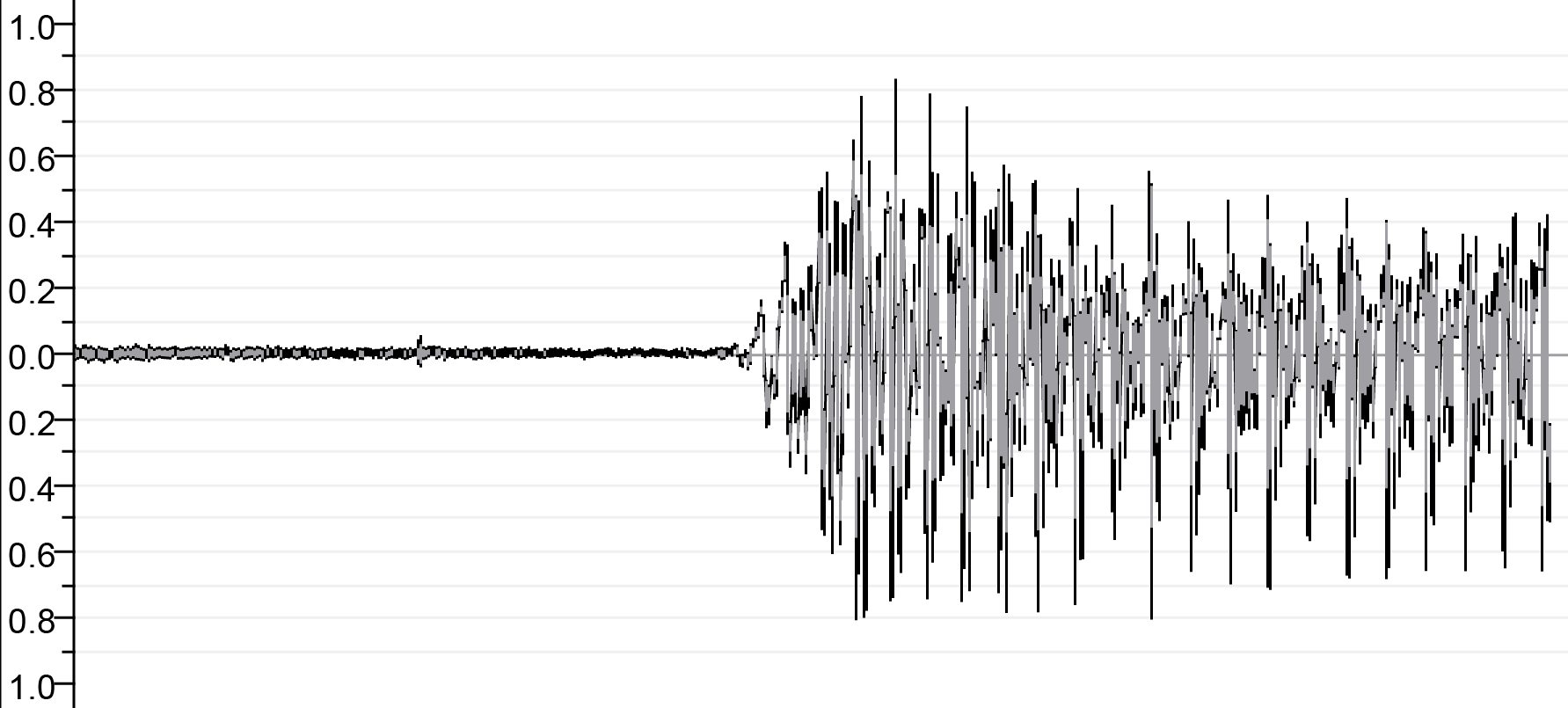 |  | 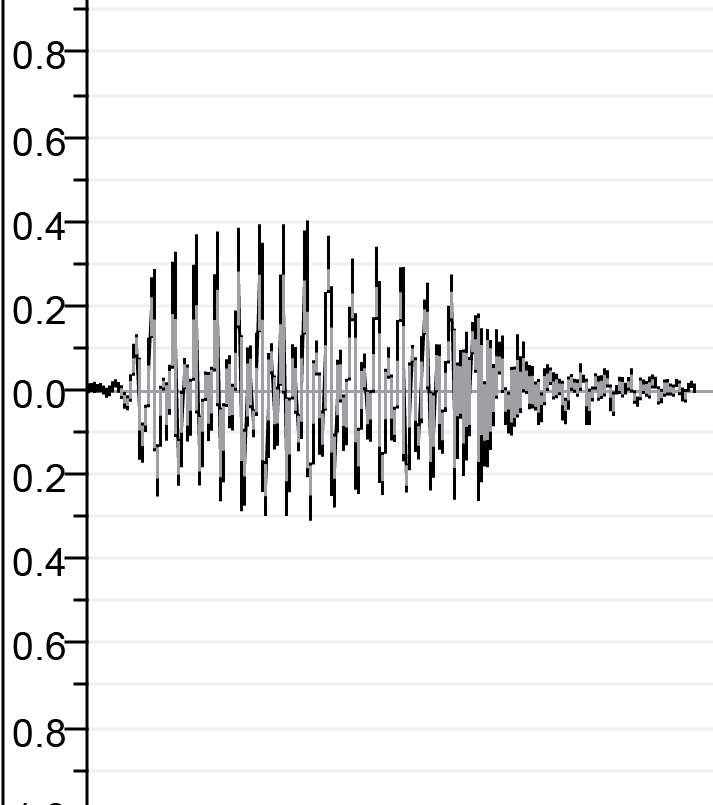 |
| Sa.wav | lā.wav | M.wav |
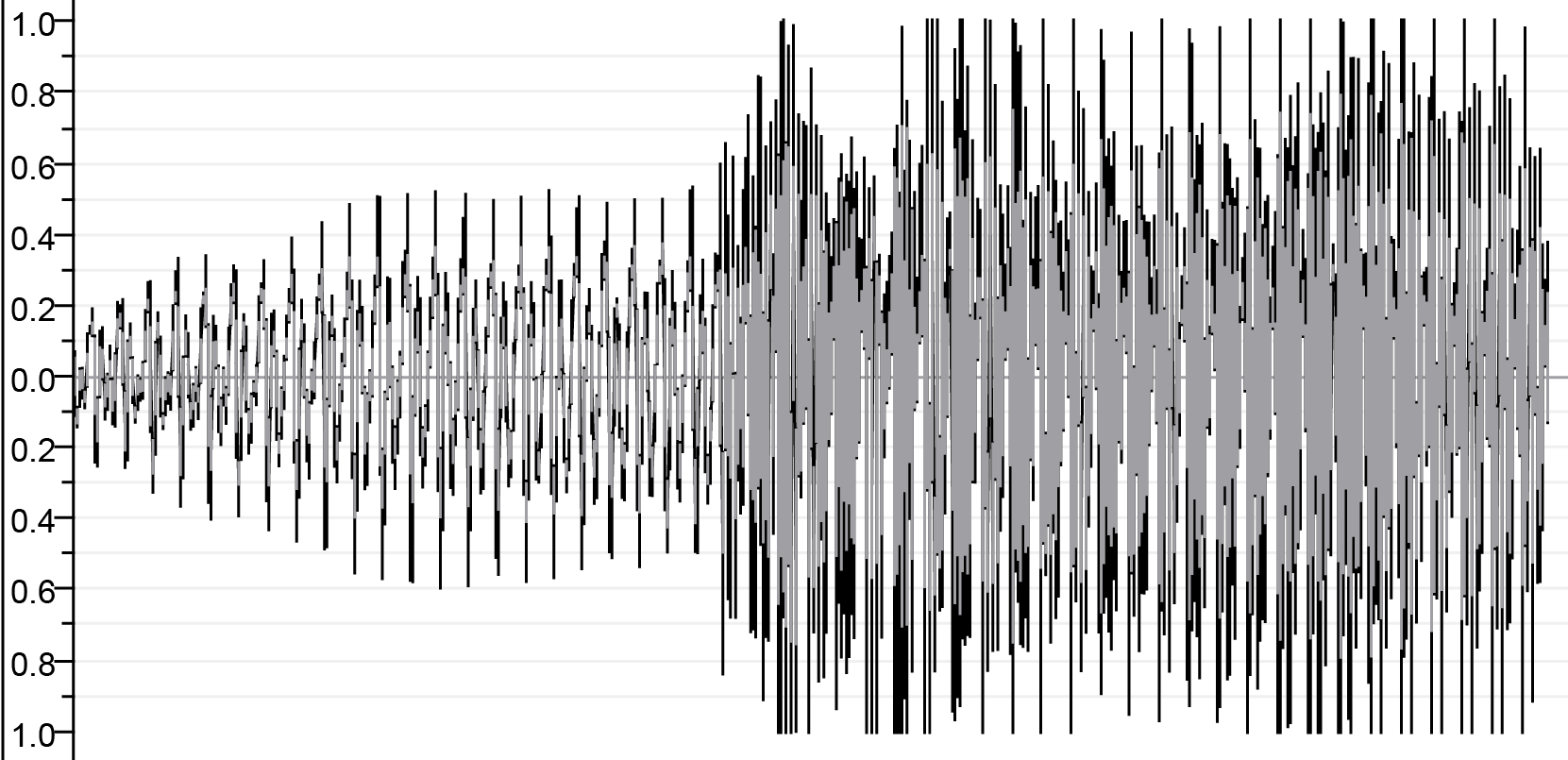
| Setelah gabungan | ||
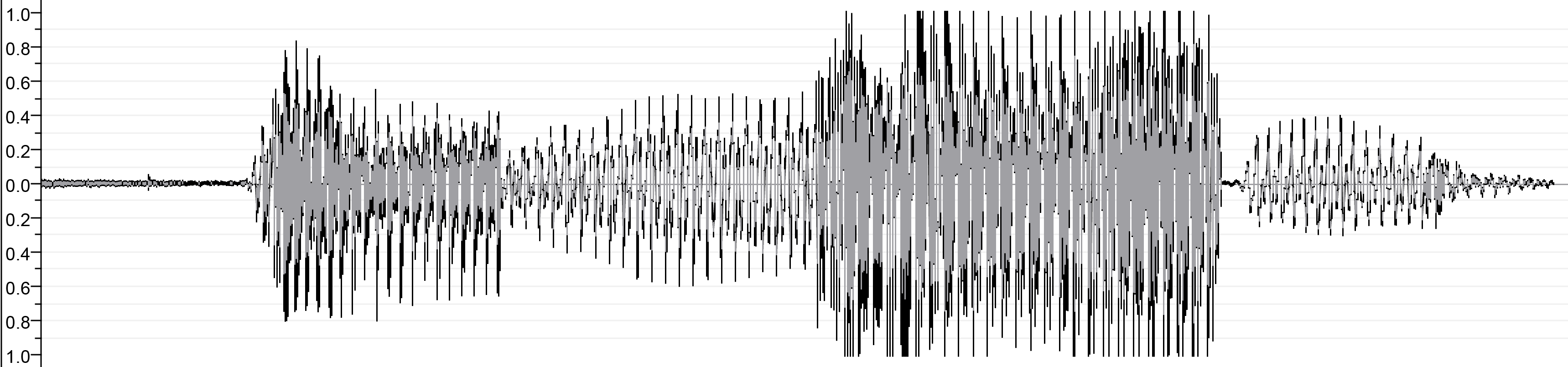 | ||
| output.wav | ||
File audio output diputar pada platform iOS dan Android berkat perpustakaan yang terdengar asli reaksi. Membaca Sumber Daya Bundel dan Mentransfernya ke Lokasi Sandbox/SD-Card juga dimungkinkan berkat React-Native-FS
Terima kasih khusus kepada Direktur Proyek saya, Dr. Mohammad Taheri yang memberi saya kepercayaan diri mendekati subjek ini dan membimbing saya melalui langkah -langkah terbaik untuk memungkinkannya. Tanpa dia, saya mungkin tidak akan pernah masuk ke penelitian akademis seperti itu.
Terima kasih banyak berikutnya kepada komunitas pengembang yang dengan murah hati berbagi teknologi canggih dengan orang lain. Hanya berkat komunitas ini yang menciptakan kembali roda tidak lagi diperlukan.
Berikut adalah daftar pendek perpustakaan yang membantu saya tanpa batas dalam jalur pengembangan saya:
Repositori ini awalnya dibangun sebagai upaya minimum untuk solusi teks-ke-speech open-source bahasa Persia. Saya akan sangat berterima kasih atas kontribusi apa pun dari masalah yang melaporkan perbaikan bug dan perbaikan.
Kontribusi dengan menambahkan lebih banyak suara ke proyek ini juga sangat disambut dan Anda juga dapat menyebutkan nama Anda di voices.json.
Jangan ragu untuk mengirim permintaan tarik jika merasakan kebutuhan apa pun.


