persian tts
Initial Android release

Персидский TTS-это простой синтезирующий двигатель текста к Speach и реагирующим приложением, которое я изначально разработал в качестве проекта по выпускной степени бакалавра.
Проект, однако, предназначен для получения постепенных улучшений с течением времени.
![]()
![]()
![]()
Приложения Persian-TTS питаются на основе React Native, поэтому вам понадобится для правильного составления приложений. Для компиляции версии Android, наличие правильной Android SDK на вашей машине является обязательной, и, очевидно, компиляция необходимости вариента для iOS, которые вы имеете рабочую копию XCode и функциональный инструмент управления зависимостями кокопод на машине с питанием операционной системы MacOS.
Вам также необходимо будет иметь инструмент управления зависимостями для доступа к NPM и загрузки зависимостей проекта. В этом проекте используется пряжа, но также можно использовать NPM или другие инструменты.
Сначала вы можете получить исходный код, клонируя его
git clone [email protected]:amfolio/persian-tts.git cd ios
pod install Затем перейдите в каталог пакета и установите его зависимости с помощью yarn install или npm install
Чтобы запустить приложения в эмуляторах Android и/или iOS операционных систем, вы можете использовать следующие команды:
react-native run-androidreact-native run-iosСтруктура этого проекта просто идентична многим другим реактивным структурам проекта. Ниже приведена просто большая картина основной структуры:
Вскоре проект использует одобрение «конкатативного синтеза» для достижения своей цели. На персидском языке неограниченный набор слов может быть сконструирован путем объединения "согласных+гласных пар. Для смелости здесь мы называем эти пары просто «слогами».
Чтобы сделать синтезирующую работу, проект первоначально имеет набор из 169 голосов слогов, перекодированный из моего собственного голоса (так что это не профессиональное повествование?). это число предназначено как реже:
| Тип голоса | Соответствующие файлы |
|---|---|
| гласные | 6 |
| молчаливые согласные | 23 |
| слог (согласный+гласный) | 138 |
| пробелы | 2 |
| Общий | 169 |
Затем процесс синтеза осуществляется путем объединения слогов с использованием библиотеки FFMPEG и его обертки реагируют-FFMPEG. Вот быстрая схема того, что происходит.
На первом этапе фонетическая, соответствующая персидскому вводу, создается с использованием функции утилиты TextTophoneEms.
const input = "سلام" ; // means "Hello" in persian
const output = textToPhonems ( input ) ; // ["sa", "lā", "m"];Результат шага 1 проходит через функцию утилиты Phonemstoffmpeg и получает действительную команду FFMPEG Concatnation:
const ffmpeg = phonemsToFFMpeg ( output ) ;И результат будет:
ffmpeg
-I sa.wav -I lā.wav -I m.wav
-filter_complex ‘[0:0][1:0][2:0]concat=n=3:v=0:a=1[out]’
-map ‘[out]’ output.wavПриложение вызывает FFMPEG с использованием React-C-FFMPEG, и следующие шаги делаются за кулисами:
| Перед контактом | ||
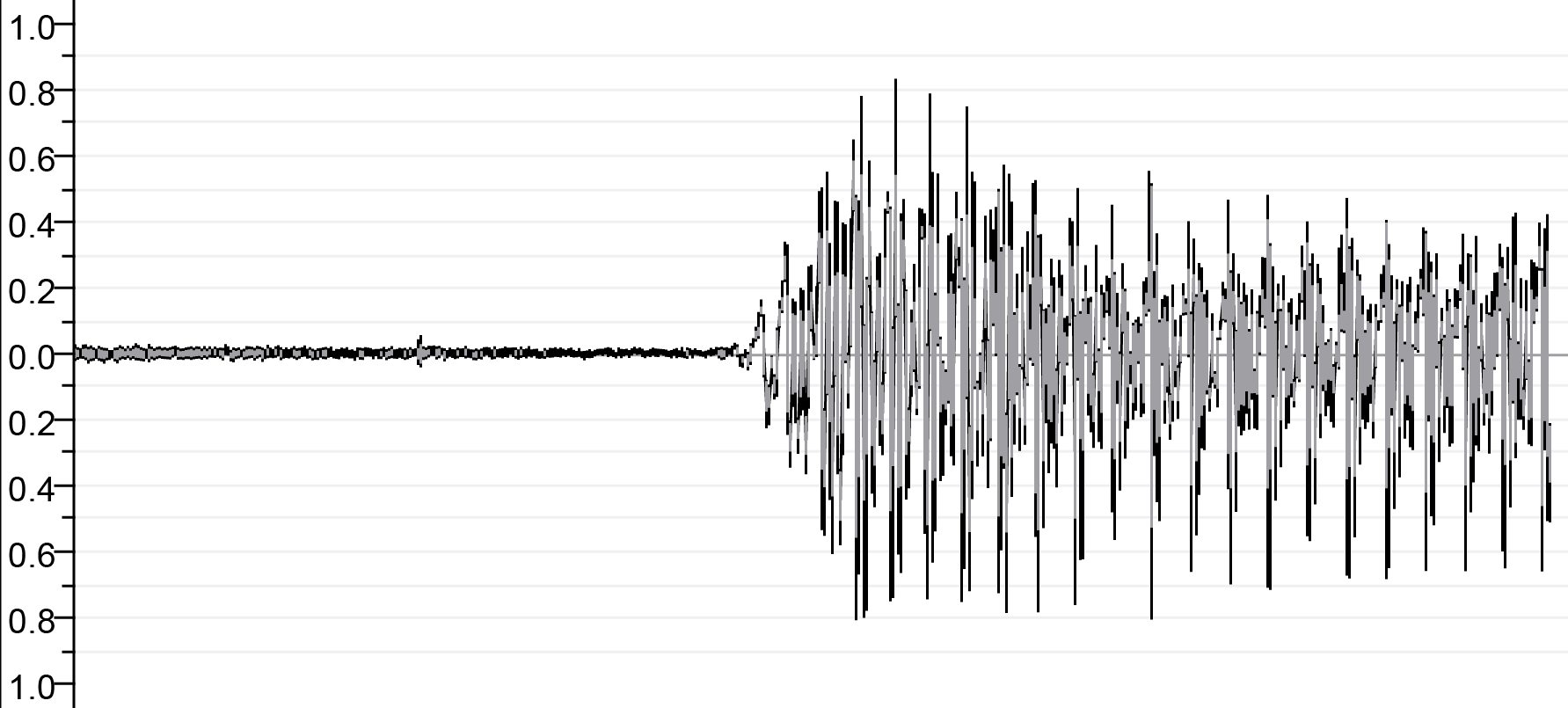 |  | 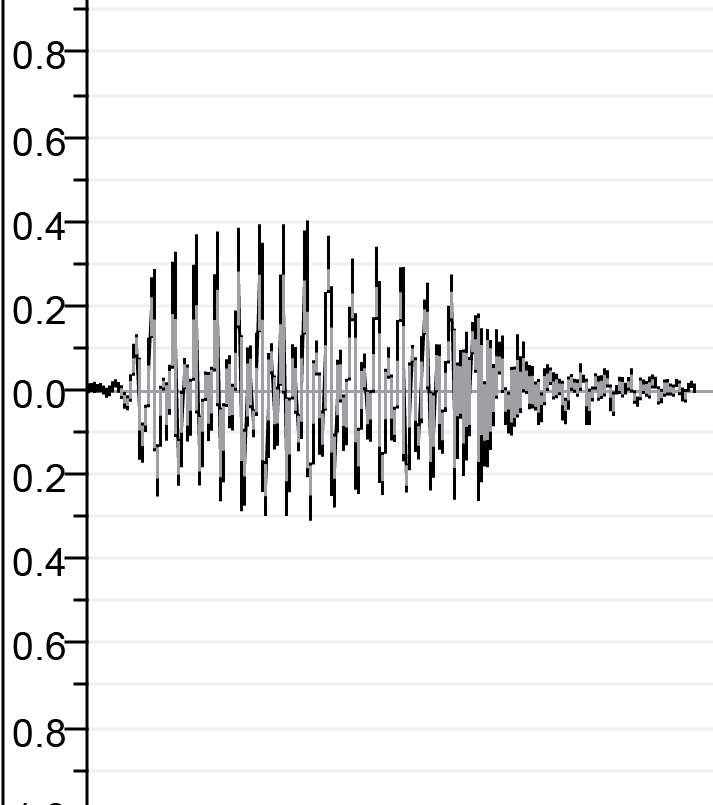 |
| Sa.wav | Lā.wav | М.В. |
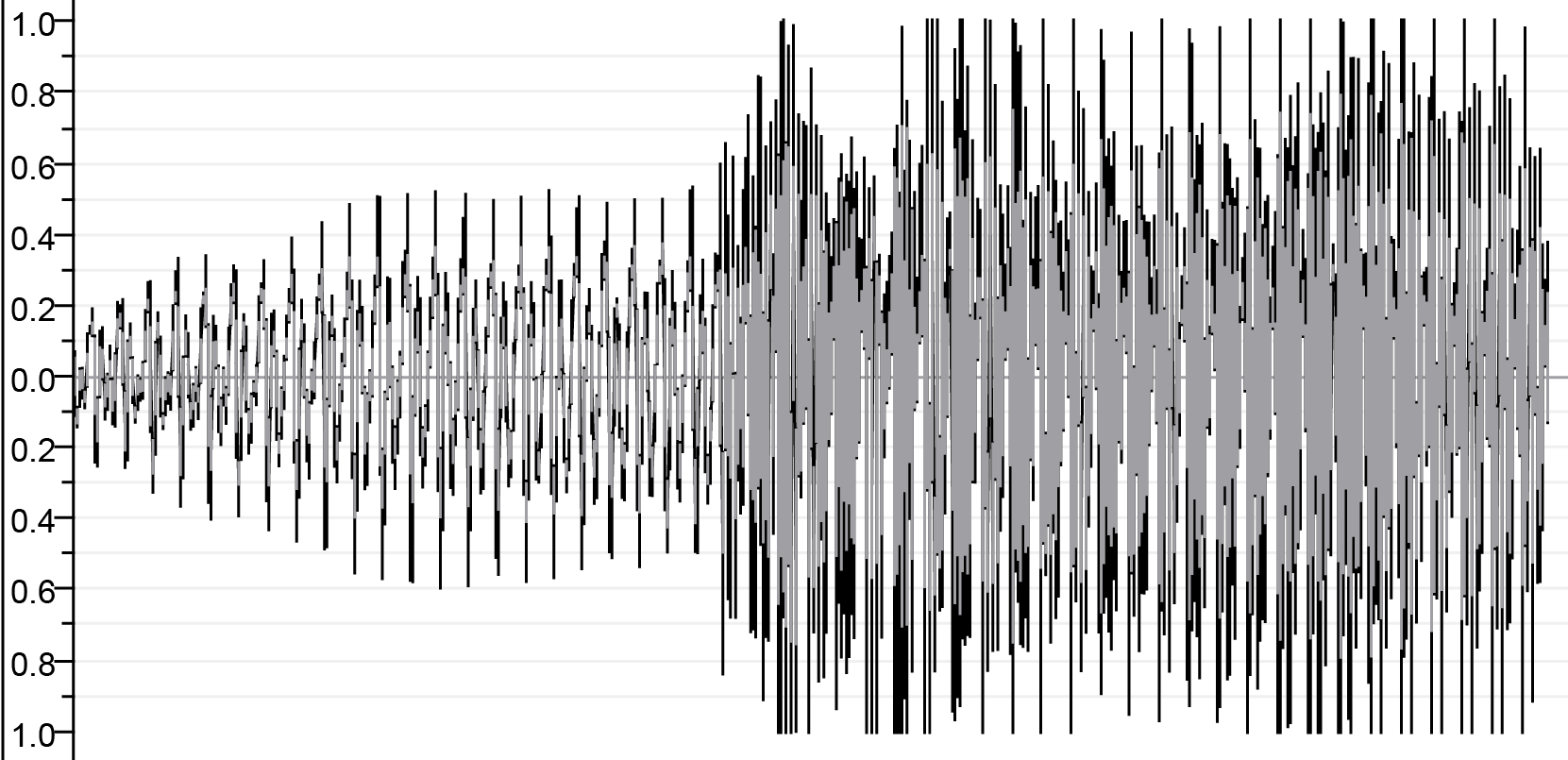
| После соратника | ||
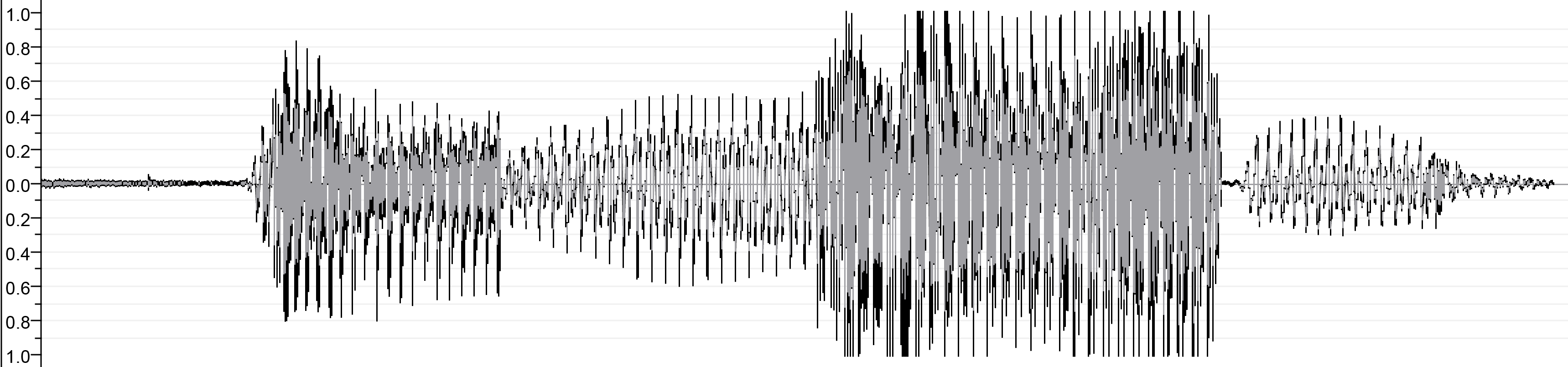 | ||
| output.wav | ||
Выходной аудиофайл воспроизводится как на платформах iOS и Android благодаря библиотеке React-Sound. Чтение ресурсов Bundle и передача их в Sandbox/SD-карта также возможна благодаря React-Native-FS
Особая благодарность вам подходит директору моего проекта, доктору Мохаммаду Тахери, который дал мне уверенность в том, чтобы приблизиться к этому вопросу и направил меня через лучшие шаги, чтобы сделать это возможным. Без него я бы, вероятно, никогда бы не попал в такие академические исследования.
Следующая большая благодарность сообществу разработчиков, которое щедро разделяет передовые технологии с другими. Именно благодаря этому сообществу заново изобретать колеса больше не необходимо.
Вот краткий список библиотек, которые бесконечно помогли мне в моем пути развития:
Этот репозиторий изначально построен как минимальные усилия для персидского языка с открытым исходным исходным решением. Я был бы очень благодарен за любой вклад из вопросов, отчитывающихся в ошибки и улучшения.
Вклад путем добавления большего количества голосов в проект также очень приветствуется, и вы также можете упомянуть свое имя в voices.json.
Пожалуйста, не стесняйтесь отправлять запросы на привлечение в случае почувствовать какую -либо необходимость.


