siamese triplet
1.0.0
การใช้งาน Pytorch ของเครือข่ายสยามและทริปเปิลสำหรับการเรียนรู้การฝังตัว
เครือข่าย Siamese และ Triplet มีประโยชน์ในการเรียนรู้การแมปจากภาพไปยังพื้นที่ Euclidean ขนาดกะทัดรัดซึ่งระยะทางตรงกับการวัดความคล้ายคลึงกัน [2] EMBEDDINGS ที่ผ่านการฝึกอบรมด้วยวิธีนี้สามารถใช้เป็นคุณสมบัติเวกเตอร์สำหรับการจำแนกประเภทหรืองานการเรียนรู้ไม่กี่นัด
ต้องใช้ pytorch 0.4 กับ Torchvision 0.2.1
สำหรับ pytorch 0.3 การตรวจสอบความเข้ากันได้แท็ก TORCH-0.3.1
เราจะฝึกอบรมการฝังตัวในชุดข้อมูล MNIST การทดลองดำเนินการในสมุดบันทึก Jupyter
เราจะผ่านการเรียนรู้คุณสมบัติการเรียนรู้แบบฝังโดยใช้ฟังก์ชั่นการสูญเสียที่แตกต่างกันในชุดข้อมูล MNIST นี่เป็นเพียงเพื่อจุดประสงค์ในการสร้างภาพดังนั้นเราจะใช้การฝังตัว 2 มิติซึ่งไม่ใช่ตัวเลือกที่ดีที่สุดในทางปฏิบัติ
สำหรับการทดลองทุกครั้งจะใช้เครือข่ายการฝังตัวเดียวกัน (32 Conv 5x5 -> Prelu -> MaxPool 2x2 -> 64 Conv 5x5 -> Prelu -> MaxPool 2x2 -> Dense 256 -> Prelu -> Dense 256 -> Prelu -> Dense 2)
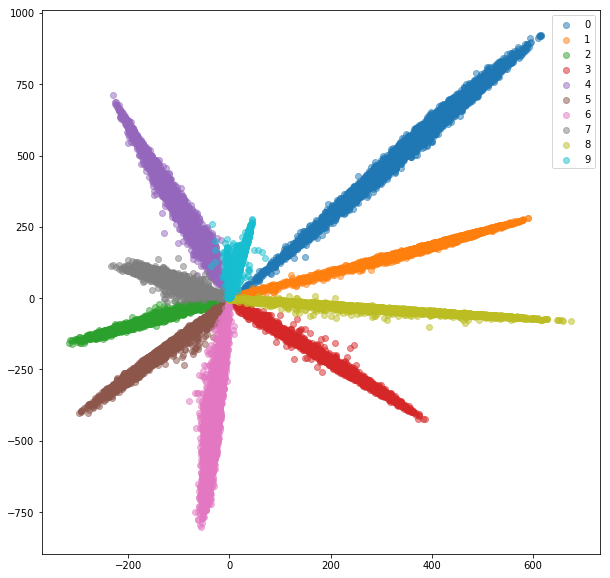
เราเพิ่มเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ด้วยจำนวนคลาสและฝึกอบรมเครือข่ายเพื่อการจำแนกประเภทด้วย softmax และ cross-entropy เครือข่ายรถไฟถึงความแม่นยำ ~ 99% เราแยก 2 มิติฝังตัวจากเลเยอร์สุดท้าย:
ชุดรถไฟ:
ชุดทดสอบ:
ในขณะที่การฝังตัวดูแยกกันได้ (ซึ่งเป็นสิ่งที่เราฝึกฝนพวกเขา) พวกเขาไม่มีคุณสมบัติการวัดที่ดี พวกเขาอาจไม่ใช่ตัวเลือกที่ดีที่สุดในการเป็นตัวบ่งชี้สำหรับคลาสใหม่
ตอนนี้เราจะฝึกอบรมเครือข่ายสยามที่ถ่ายภาพคู่หนึ่งและฝึกอบรมการฝังตัวเพื่อให้ระยะห่างระหว่างพวกเขาลดลงหากพวกเขามาจากชั้นเรียนเดียวกันและมากกว่าค่ามาร์จิ้นบางส่วนหากพวกเขาเป็นตัวแทนของคลาสที่แตกต่างกัน เราจะลดฟังก์ชั่นการสูญเสียแบบตัดกันให้น้อยที่สุด [1]:
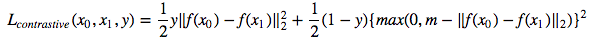
ตัวอย่างคลาส Siamesemnist แบบสุ่มบวกและลบที่ถูกป้อนเข้าสู่เครือข่ายสยาม
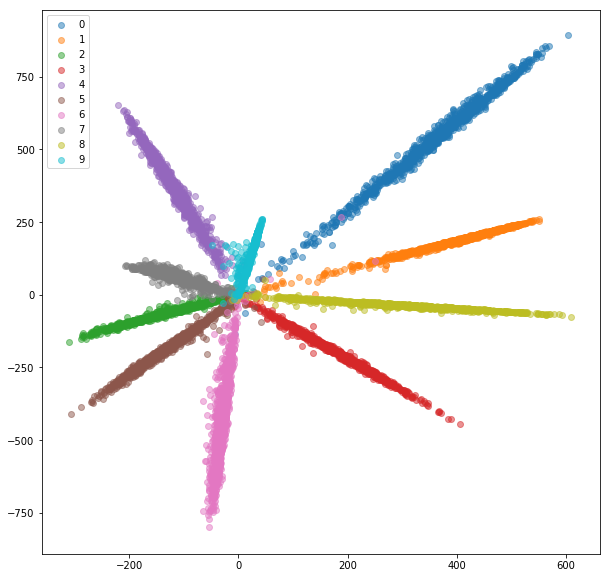
หลังจากการฝึกอบรม 20 ครั้งที่นี่คือการฝังตัวที่เราได้รับสำหรับชุดฝึกอบรม:
ชุดทดสอบ:
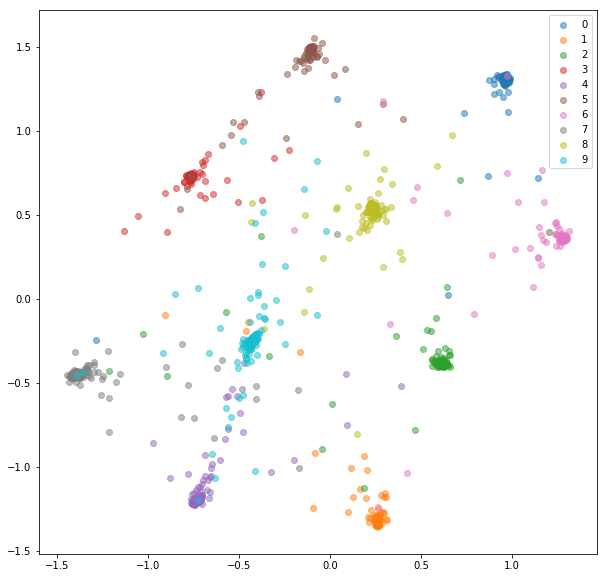
การฝังตัวที่เรียนรู้นั้นเป็นกลุ่มที่ดีกว่าภายในชั้นเรียน
เราจะฝึกอบรมเครือข่าย Triplet ที่ใช้สมอ, บวก (ของคลาสเดียวกันกับจุดยึด) และเชิงลบ (ของคลาสที่แตกต่างจากจุดยึด) วัตถุประสงค์คือเพื่อเรียนรู้การฝังตัวเพื่อให้สมอใกล้กับตัวอย่างที่เป็นบวกมากกว่าตัวอย่างเชิงลบโดยค่ามาร์จิ้น
 ที่มา: Schroff, Florian, Dmitry Kalenichenko และ James Philbin Facenet: การฝังแบบครบวงจรสำหรับการจดจำใบหน้าและการจัดกลุ่ม CVPR 2015
ที่มา: Schroff, Florian, Dmitry Kalenichenko และ James Philbin Facenet: การฝังแบบครบวงจรสำหรับการจดจำใบหน้าและการจัดกลุ่ม CVPR 2015
การสูญเสียแฝดสาม : 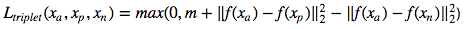
คลาส Tripletmnist ตัวอย่างเป็นตัวอย่างที่เป็นบวกและลบสำหรับสมอที่เป็นไปได้ทุกครั้ง
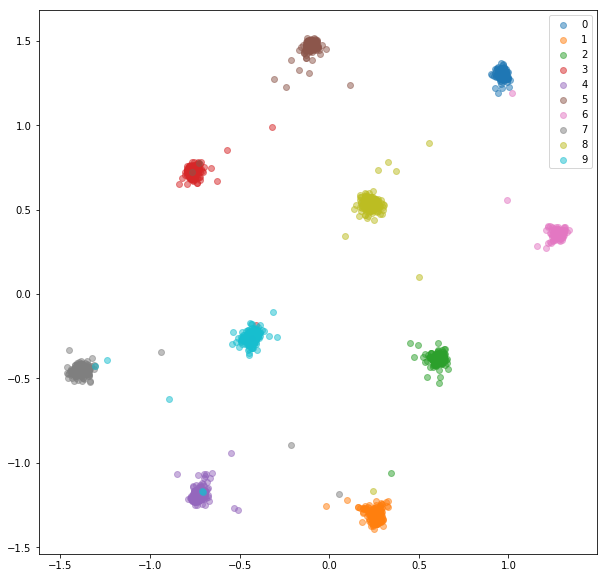
หลังจากการฝึกอบรม 20 ครั้งที่นี่คือการฝังตัวที่เราได้รับสำหรับชุดฝึกอบรม:
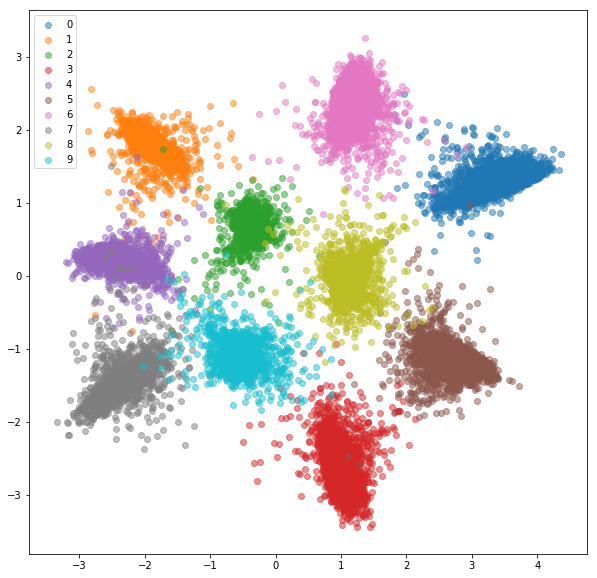
ชุดทดสอบ:
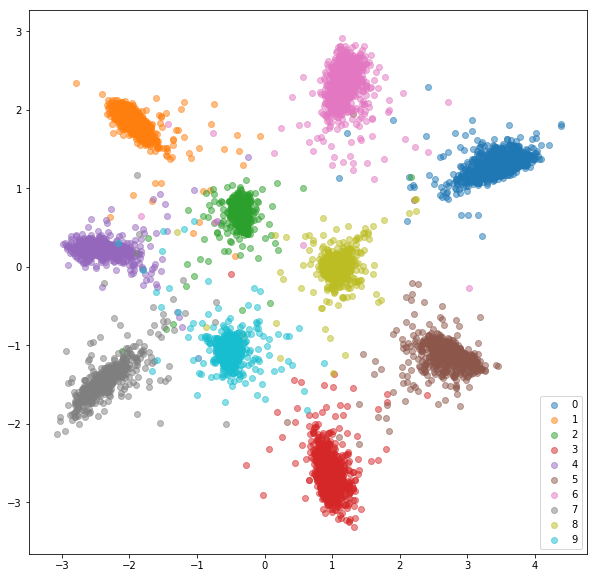
การฝังตัวที่เรียนรู้ไม่ได้อยู่ใกล้กันภายในชั้นเรียนเช่นเดียวกับในกรณีของเครือข่ายสยาม แต่นั่นไม่ใช่สิ่งที่เราปรับให้เหมาะสม เราต้องการให้ Embeddings ใกล้ชิดกับการฝังตัวอื่น ๆ จากชั้นเรียนเดียวกันมากกว่าจากชั้นเรียนอื่น ๆ และเราจะเห็นว่าการฝึกอบรมกำลังจะไป
มีปัญหาสองประการเกี่ยวกับเครือข่ายสยามและทริปเล็ต:
เพื่อจัดการกับปัญหาเหล่านี้ได้อย่างมีประสิทธิภาพเราจะป้อนเครือข่ายด้วยแบทช์ขนาดเล็กมาตรฐานเช่นเดียวกับที่เราทำเพื่อการจำแนกประเภท ฟังก์ชั่นการสูญเสียจะรับผิดชอบในการเลือกคู่แข็งและแฝดสามภายในมินิแบทช์ หากเราป้อนเครือข่ายด้วยภาพ 16 ภาพต่อ 10 คลาสเราสามารถประมวลผลได้สูงสุด 159*160/2 = 12720 คู่และ 10*16*15/2*(9*16) = 172800 Triplets เมื่อเทียบกับ 80 คู่และ 53 triplets ในการดำเนินการก่อนหน้านี้
โดยปกติแล้วมันไม่ใช่ความคิดที่ดีที่สุดในการประมวลผลคู่ที่เป็นไปได้ทั้งหมดหรือสามเท่าภายในมินิแบทช์ เราสามารถค้นหากลยุทธ์บางอย่างเกี่ยวกับวิธีการเลือก triplets ใน [2] และ [3]
เราจะป้อนเครือข่ายด้วยมินิแบทช์เช่นเดียวกับที่เราทำสำหรับเครือข่ายการจำแนกประเภท เวลานี้เราจะใช้ batchsampler พิเศษที่จะตัวอย่าง n_classes และ n_samples ภายในแต่ละคลาสส่งผลให้ขนาดเล็กของขนาด n_classes*n_samples
สำหรับคู่มินิแบทช์แต่ละคู่จะถูกเลือกโดยใช้ฉลากที่ให้ไว้
MNIST เป็นชุดข้อมูลที่ค่อนข้างง่ายและการฝังตัวจากคู่ที่เลือกแบบสุ่มค่อนข้างดีอยู่แล้วเราไม่เห็นการปรับปรุงมากนักที่นี่
รถไฟฝังตัว:
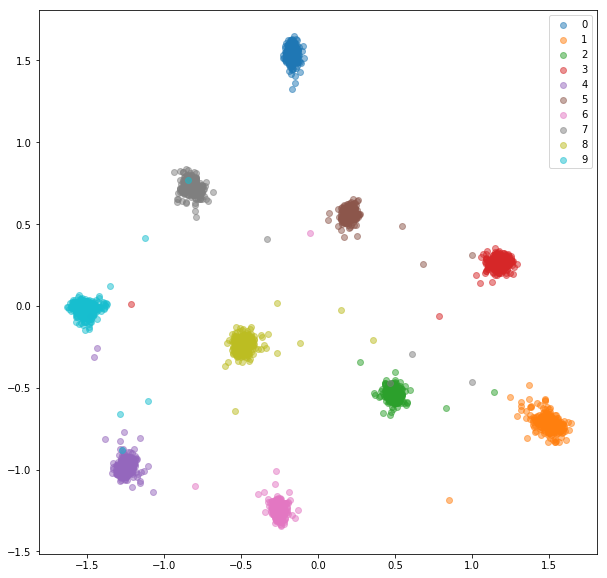
ทดสอบ Embeddings:
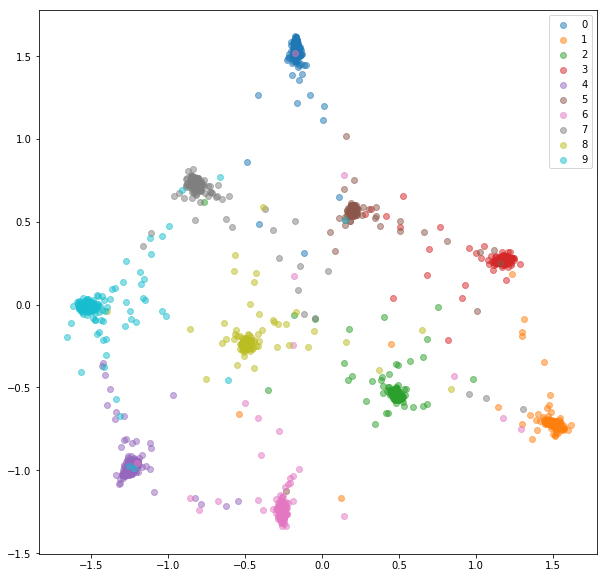
เราจะป้อนเครือข่ายด้วยมินิแบทช์เช่นเดียวกับการเลือกคู่ออนไลน์ มีสองกลยุทธ์ที่เราสามารถใช้สำหรับการเลือก triplet ที่ได้รับฉลากและการคาดการณ์การฝังตัว:
กลยุทธ์สำหรับการเลือก Triplet จะต้องได้รับการคัดเลือกอย่างระมัดระวัง กลยุทธ์ที่ไม่ดีอาจนำไปสู่การฝึกอบรมที่ไม่มีประสิทธิภาพหรือแย่กว่านั้นในการจำลองการยุบตัว (การฝังตัวทั้งหมดที่จบลงด้วยค่าเดียวกัน)
นี่คือสิ่งที่เราได้รับจากเชิงลบแบบสุ่มสำหรับแต่ละคู่บวก
ชุดฝึกอบรม:
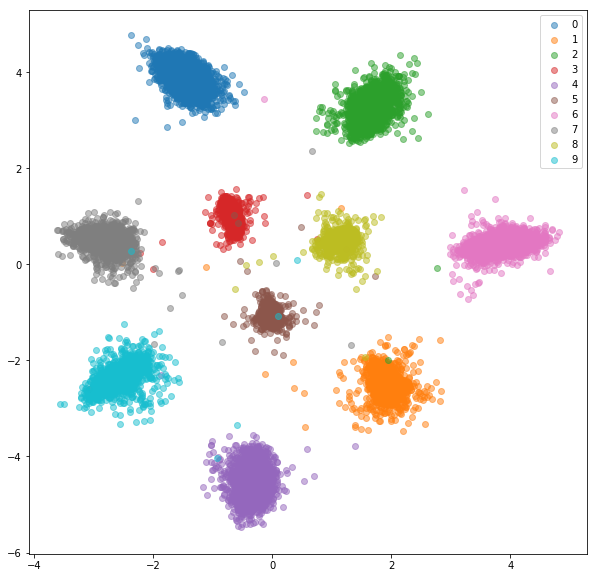
ชุดทดสอบ:
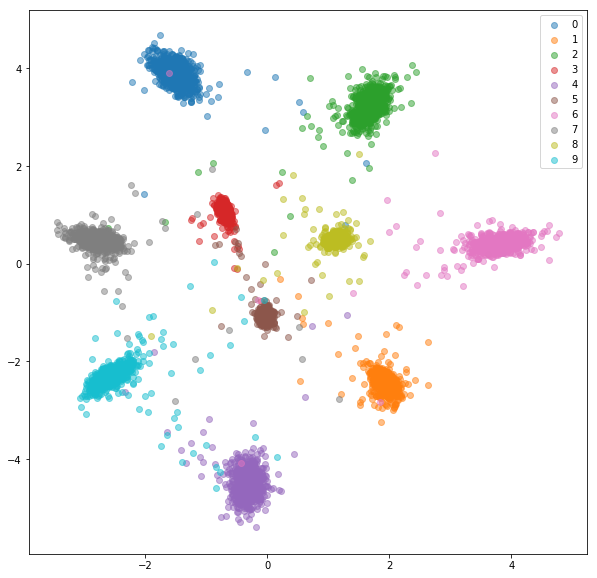
การทดลองที่คล้ายกันได้ดำเนินการสำหรับชุดข้อมูล FashionMnist ซึ่งข้อดีของการขุดเชิงลบออนไลน์จะปรากฏขึ้นเล็กน้อย สถาปัตยกรรมเครือข่ายเดียวกันที่มีการใช้งานแบบฝังเพียง 2 มิติเท่านั้นซึ่งอาจไม่ซับซ้อนพอสำหรับการเรียนรู้การฝังที่ดี ชุดข้อมูลที่ซับซ้อนมากขึ้นที่มีคลาสจำนวนที่สูงขึ้นควรได้รับประโยชน์มากขึ้นจากการขุดออนไลน์
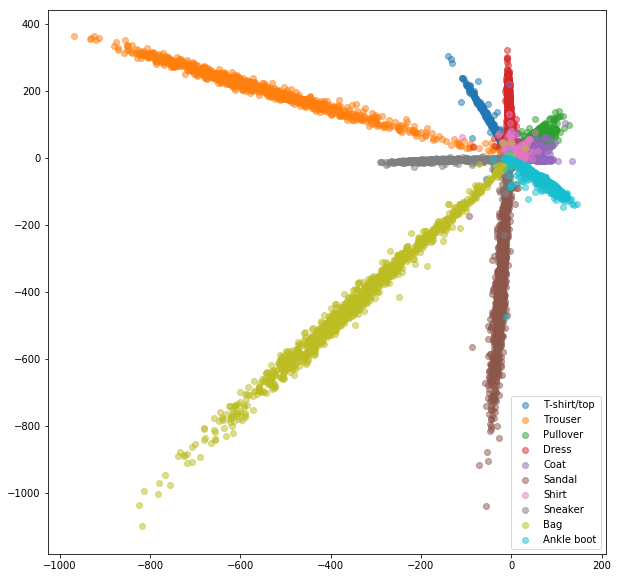
เครือข่ายสยามที่มีคู่ที่เลือกแบบสุ่ม
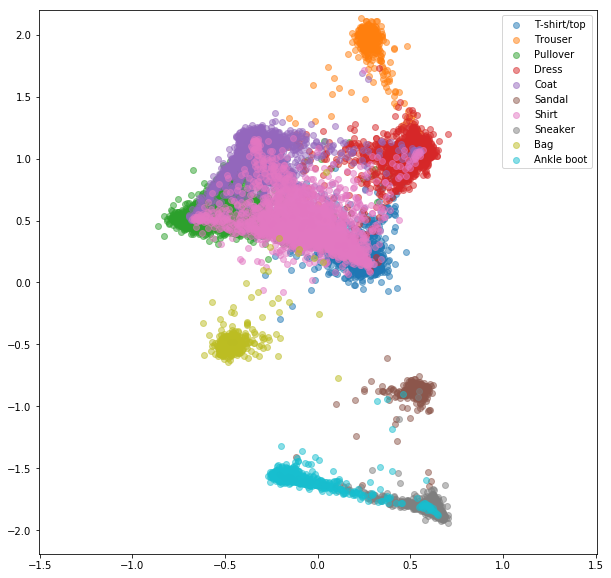
การสูญเสียความคมชัดออนไลน์ด้วยการขุดเชิงลบ
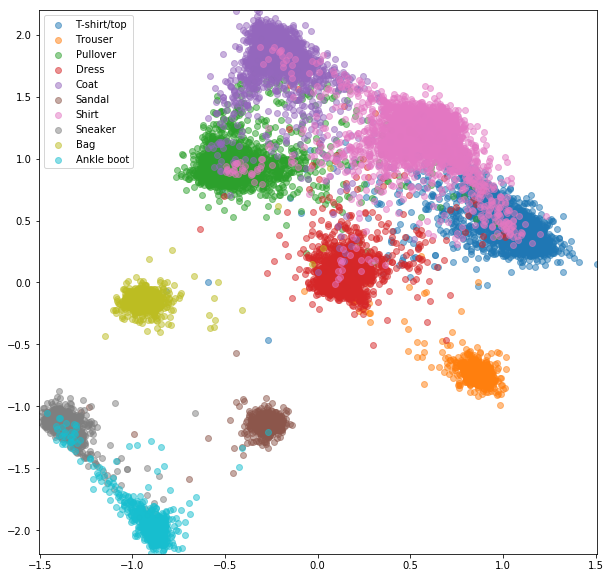
Triplet Network ด้วยการสุ่มแฝดสาม
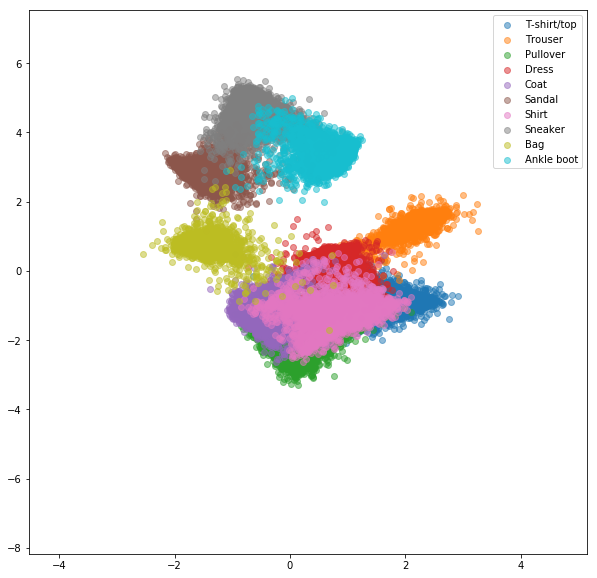
การสูญเสีย triplet ออนไลน์ด้วยการขุดเชิงลบ
[1] Raia Hadsell, Sumit Chopra, Yann Lecun, การลดขนาดโดยการเรียนรู้การทำแผนที่ค่าคงที่, CVPR 2006
[2] Schroff, Florian, Dmitry Kalenichenko และ James Philbin Facenet: การฝังแบบครบวงจรสำหรับการจดจำใบหน้าและการจัดกลุ่ม CVPR 2015
[3] Alexander Hermans, Lucas Beyer, Bastian Leibe, ในการป้องกันการสูญเสีย triplet สำหรับการระบุตัวตนของบุคคล, 2017
[4] Brandon Amos, Bartosz Ludwiczuk, Mahadev Satyanarayanan, OpenFace: ห้องสมุดการจดจำใบหน้าทั่วไปพร้อมแอปพลิเคชันมือถือ 2016
[5] Yi Sun, Xiaogang Wang, Xiaooou Tang, การเรียนรู้อย่างลึกล้ำโดยการแสดงใบหน้าโดยการระบุร่วมกัน, NIPS 2014


