siamese triplet
1.0.0
Pytorch -Implementierung von siamesischen und Triplet -Netzwerken zum Lernen von Einbettungen.
Siamese- und Triplet -Netzwerke sind nützlich, um Zuordnungen von Bild zu einem kompakten euklidischen Raum zu lernen, in dem Entfernungen einem Maß für die Ähnlichkeit entsprechen [2]. Einbettungsdings, die so geschult wurden, können als Merkmale Vektoren für die Klassifizierung oder nur wenige Lernaufgaben verwendet werden.
Benötigt Pytorch 0,4 mit Torchvision 0.2.1
Für Pytorch 0.3 Kompatibilitätskasse Tag Torch-0.3.1
Wir schulen Einbettung auf dem MNIST -Datensatz. Experimente wurden im Jupyter -Notizbuch durchgeführt.
Wir werden mit unterschiedlichen Verlustfunktionen im MNIST -Datensatz mit unterschiedlichen Verlustfunktionen mithilfe von Lernfeature -Feature -Einbettungen ausgeglichen. Dies dient nur zu Visualisierungszwecken. Daher werden wir zweidimensionale Einbettungen verwenden, was nicht die beste Wahl in der Praxis ist.
Für jedes Experiment wird dasselbe Einbettungsnetzwerk verwendet (32 conv 5x5 -> prelu -> maxpool 2x2 -> 64 conv 5x5 -> prelu -> maxpool 2x2 -> Dense 256 -> Prelu -> Dense 256 -> Prelu -> Dense 2) und wir führen keine Hyperparameter -Suche durch.
Mit der Anzahl der Klassen fügen wir eine vollständig vernetzte Schicht hinzu und trainieren das Netzwerk zur Klassifizierung mit Softmax und Kreuzentropie. Das Netzwerk trainiert auf eine Genauigkeit von ~ 99%. Wir extrahieren 2 dimensionale Einbettungen aus der vorletzten Schicht:
Zugset:
Testsatz:
Während die Einbettungen trennbar aussehen (wofür wir sie trainiert haben), haben sie keine guten metrischen Eigenschaften. Sie sind möglicherweise nicht die beste Wahl als Deskriptor für neue Klassen.
Jetzt trainieren wir ein siamesisches Netzwerk, das ein Paar Bilder aufnimmt und die Einbettungen trainiert, damit die Entfernung zwischen ihnen minimiert wird, wenn sie aus derselben Klasse sind und größer als ein Margin -Wert sind, wenn sie unterschiedliche Klassen darstellen. Wir werden eine kontrastive Verlustfunktion minimieren [1]:
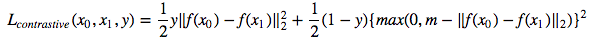
Die Siamesemnist -Klasse milzt zufällige positive und negative Paare, die dann an das siamesische Netzwerk gefüttert werden.
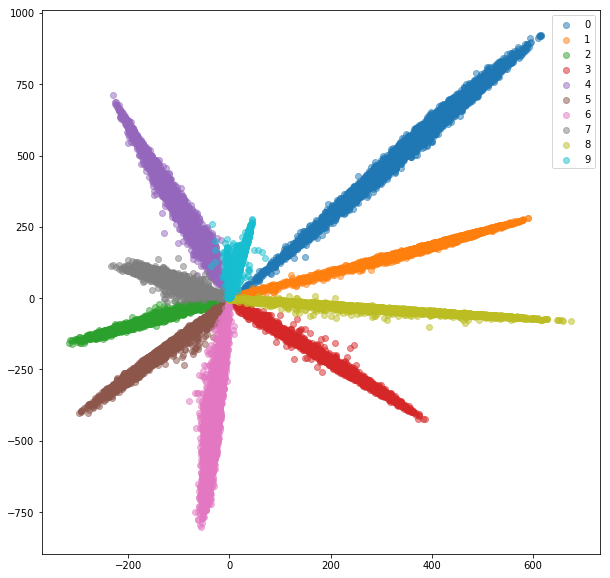
Nach 20 Epochen des Trainings sind hier die Einbettungen, die wir für das Trainingssatz erhalten:
Testsatz:
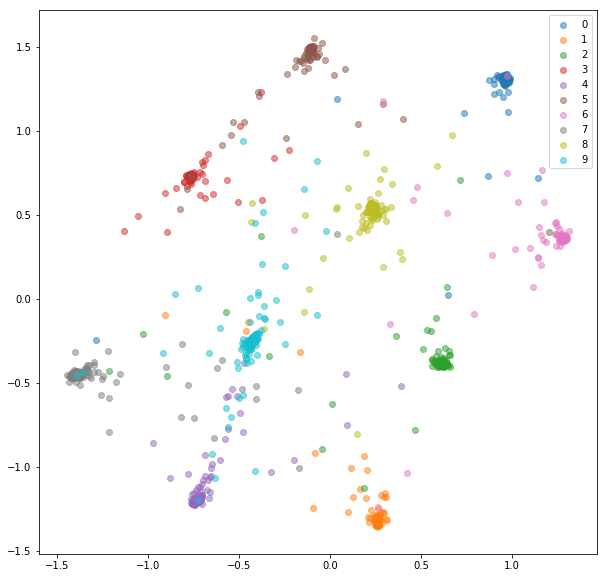
Die gelernten Einbettungen sind innerhalb des Unterrichts viel besser zusammengefasst.
Wir schulen ein Triplet -Netzwerk, das einen Anker, einen positiven (derselben Klasse wie einen Anker) und negativen (unterschiedlichen Klasse als ein Anker) nimmt. Ziel ist es, Einbettungen so zu lernen, dass der Anker näher am positiven Beispiel ist als das negative Beispiel mit einem Margenwert.
 Quelle: Schroff, Florian, Dmitry Kalenichenko und James Philbin. FACENET: Eine einheitliche Einbettung für Gesichtserkennung und Clustering. CVPR 2015.
Quelle: Schroff, Florian, Dmitry Kalenichenko und James Philbin. FACENET: Eine einheitliche Einbettung für Gesichtserkennung und Clustering. CVPR 2015.
Triplettverlust : 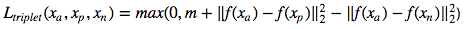
TripletMnist Class Beispiele für jeden möglichen Anker ein positives und negatives Beispiel.
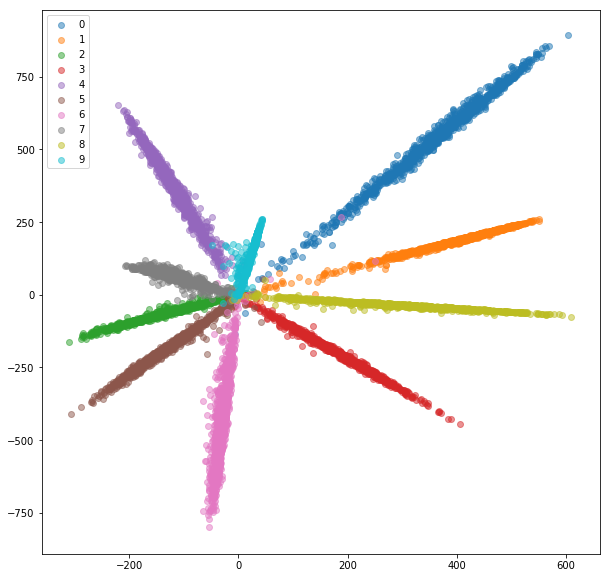
Nach 20 Epochen des Trainings sind hier die Einbettungen, die wir für das Trainingssatz erhalten:
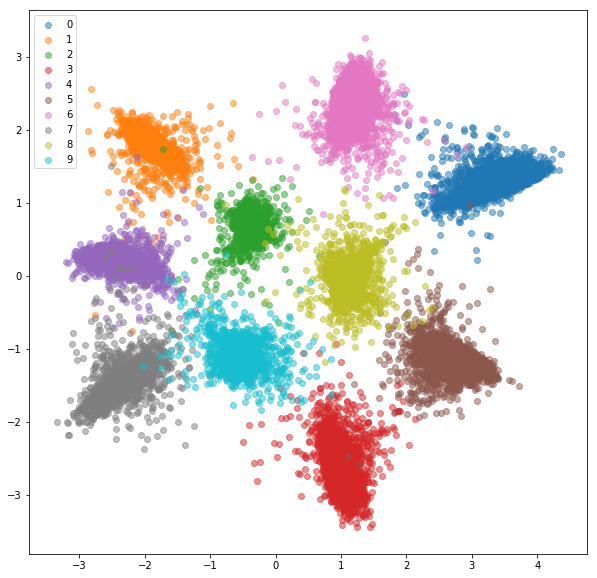
Testsatz:
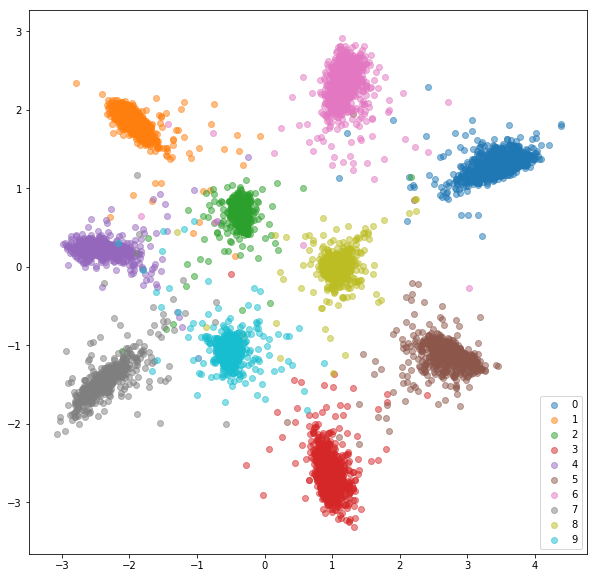
Die erlernten Einbettungen sind innerhalb der Klasse nicht so nahe beieinander wie im Fall von Siamesische Netzwerk, aber dafür haben wir sie nicht optimiert. Wir wollten, dass die Einbettungen näher an anderen Einbettungen aus derselben Klasse sind als an den anderen Klassen, und wir können sehen, dass das Training dorthin geht.
Es gibt ein paar Probleme mit siamesischen und Triplet -Netzwerken:
Um diese Probleme effizient zu bewältigen, füttern wir ein Netzwerk mit Standard-Minibatches wie für die Klassifizierung. Die Verlustfunktion ist für die Auswahl der harten Paare und Drillinge innerhalb von Mini-Batch verantwortlich. Wenn wir das Netzwerk mit 16 Bildern pro 10 Klassen füttern, können wir bis zu 159*160/2 = 12720 Paare und 10*16*15/2*(9*16) = 172800 Tripletts verarbeiten, verglichen mit 80 Paaren und 53 Tripletts in der vorherigen Implementierung.
Normalerweise ist es nicht die beste Idee, alle möglichen Paare oder Drillinge in einem Mini-Batch zu verarbeiten. Wir finden einige Strategien zur Auswahl von Tripletts in [2] und [3].
Wir werden ein Netzwerk mit Mini-Stapeln füttern, wie wir es für das Klassifizierungsnetzwerk getan haben. Dieses Mal verwenden wir einen speziellen Batchsampler, der in jeder Klasse N_classes und N_samples probiert, was zu Mini -Stapeln der Größe n_classes*n_samples führt.
Für jede Mini -Batch -Stapel werden positive und negative Paare unter Verwendung der bereitgestellten Etiketten ausgewählt.
MNIST ist ein ziemlich einfacher Datensatz und die Einbettungen aus den zufällig ausgewählten Paaren waren bereits ziemlich gut, wir sehen hier nicht viel Verbesserung.
Zugeinbettungen:
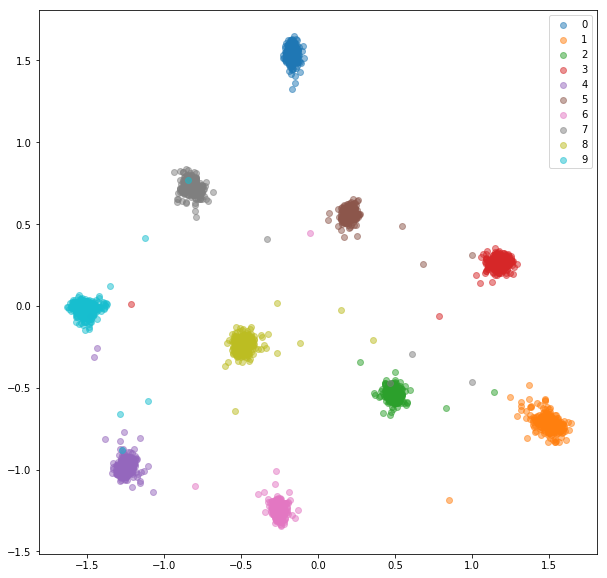
Testeinbettungen:
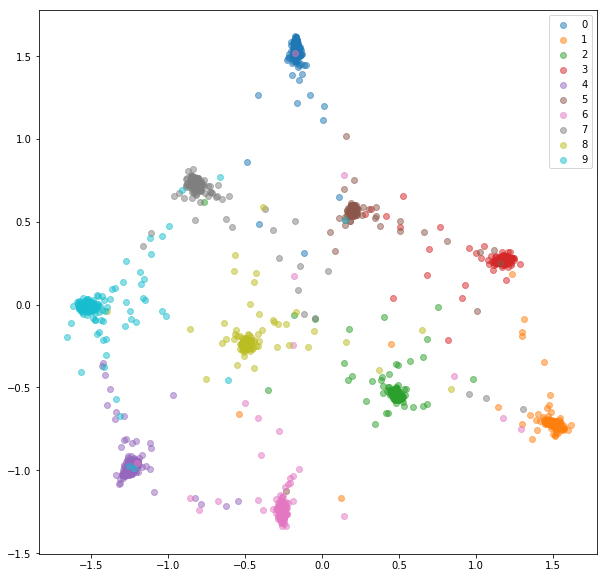
Wir füttern ein Netzwerk mit Mini-Batazen genau wie bei der Online-Paarauswahl. Es gibt ein paar Strategien, die wir für die Triplett -Auswahl anwenden können, die beschriftet und prognostizierte Einbettungen:
Die Strategie für die Triplettauswahl muss sorgfältig ausgewählt werden. Eine schlechte Strategie könnte zu ineffizientem Training oder, noch schlimmer, zu modellieren (alle Einbettungen haben die gleichen Werte).
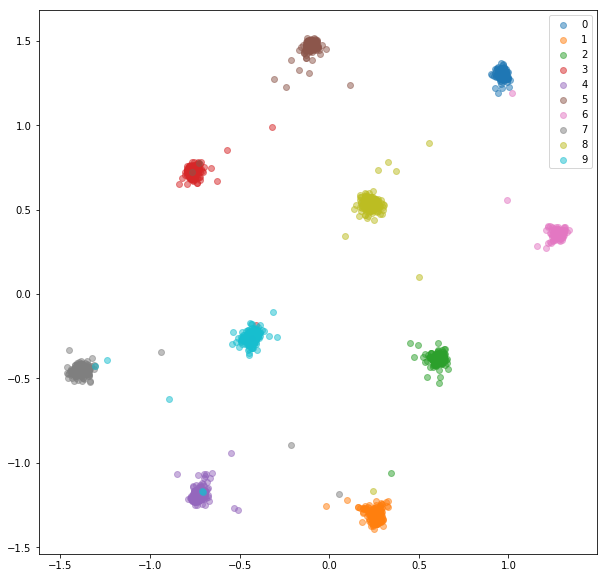
Folgendes haben wir mit zufälligen harten Negativen für jedes positive Paar bekommen.
Trainingset:
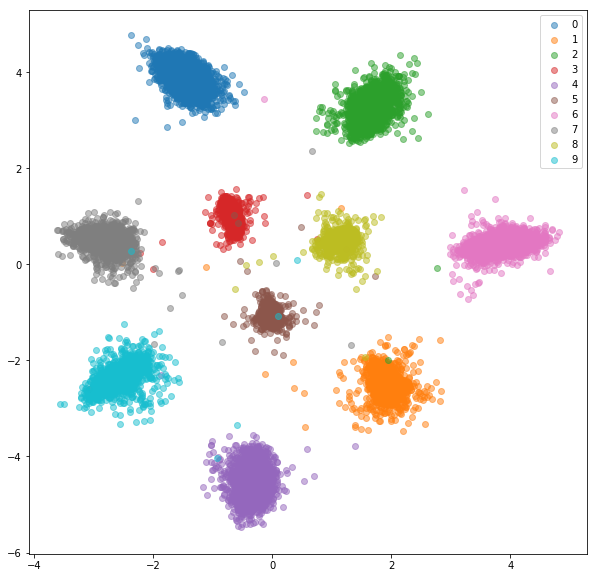
Testsatz:
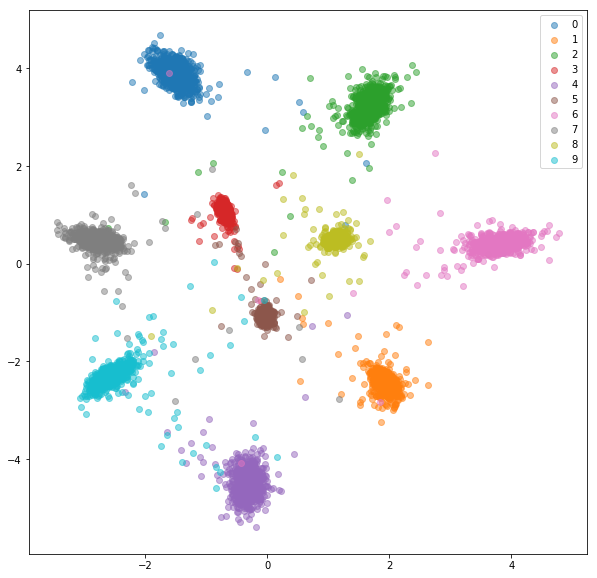
Ähnliche Experimente wurden für FashionMnist -Datensatz durchgeführt, bei denen die Vorteile des Online -negativen Bergbaus etwas sichtbarer sind. Die genaue Netzwerkarchitektur mit nur zweidimensionalen Einbettungen wurde verwendet, was wahrscheinlich nicht komplex genug ist, um gute Einbettungen zu lernen. Komplexere Datensätze mit höheren Zahlenklassen sollten noch mehr vom Online -Mining profitieren.
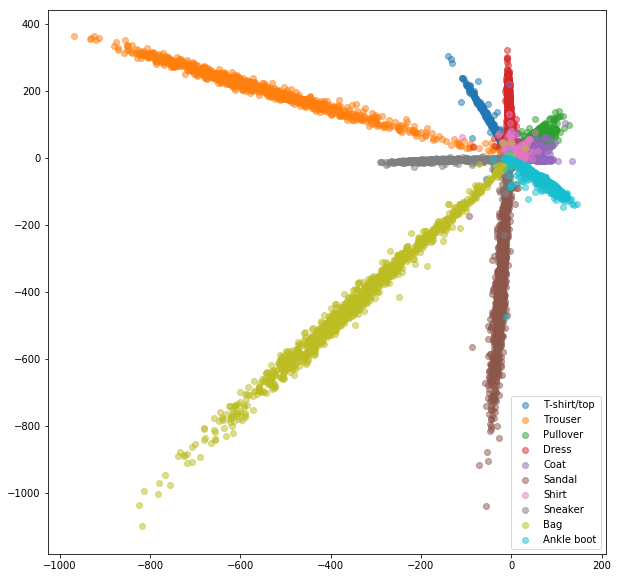
Siamese -Netzwerk mit zufällig ausgewählten Paaren
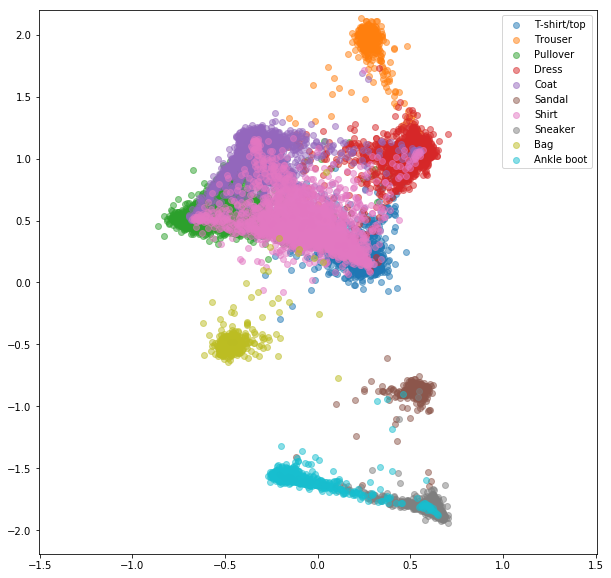
Online -kontrastiven Verlust mit negativem Bergbau
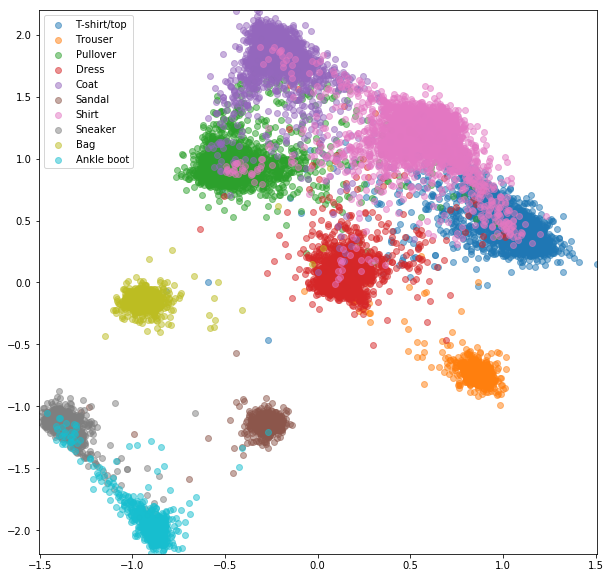
Triplet -Netzwerk mit zufälligen Tripletts
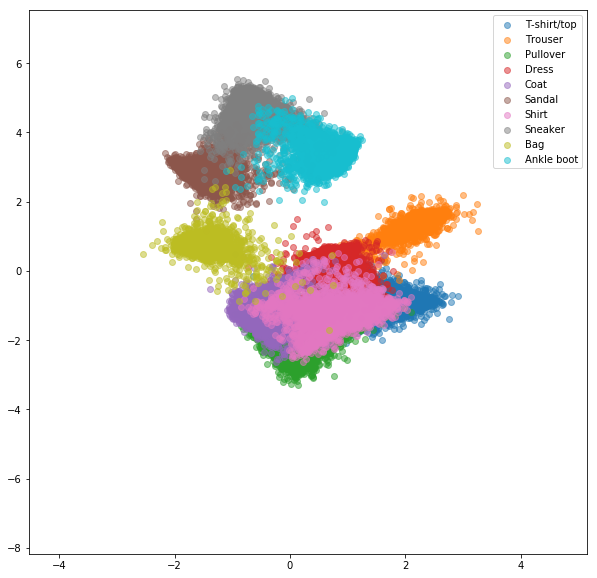
Online -Triplettverlust mit negativem Bergbau
[1] Raia Hadsell, Sumit Chopra, Yann Lecun, Dimensionalitätsreduzierung durch Erlernen einer invarianten Mapping, CVPR 2006
[2] Schroff, Florian, Dmitry Kalenichenko und James Philbin. FACENET: Eine einheitliche Einbettung für Gesichtserkennung und Clustering. CVPR 2015
[3] Alexander Hermans, Lucas Beyer, Bastian Leibe, zur Verteidigung des Triplett-Verlust
[4] Brandon Amos, Bartosz Ludwiczuk, Mahadev Satyanarayanan, Openface: Eine allgemeine Gesichtserkennungsbibliothek mit mobilen Anwendungen, 2016
[5] Yi Sun, Xiaogang Wang, Xiaoou Tang, Deep Learning Face Repräsentation durch gemeinsame Identifizierungserklärung, NIPS 2014


