siamese triplet
1.0.0
Implementación de Pytorch de redes siamesas y triplete para integrar a los aprendizaje.
Las redes siamesas y triplete son útiles para aprender mapeos de la imagen a un espacio euclidiano compacto donde las distancias corresponden a una medida de similitud [2]. Los incrustaciones capacitadas de esa manera se pueden usar como vectores de características para tareas de clasificación o de aprendizaje de pocos disparos.
Requiere Pytorch 0.4 con Vision de antorchas 0.2.1
Para Pytorch 0.3 COMPATIBILIDAD Etiqueta de pago Torch-0.3.1
Entrenaremos incrustaciones en el conjunto de datos MNIST. Los experimentos se ejecutaron en el cuaderno Jupyter.
Pasaremos por el aprendizaje de integridades de características supervisadas utilizando diferentes funciones de pérdida en el conjunto de datos MNIST. Esto es solo para fines de visualización, por lo que utilizaremos incrustaciones bidimensionales, que no es la mejor opción en la práctica.
Para cada experimento se usa la misma red de incrustación (32 Conv 5x5 -> Prelu -> Maxpool 2x2 -> 64 Conv 5x5 -> Prelu -> Maxpool 2x2 -> Dense 256 -> Prelu -> Dense 256 -> Prelu -> Dense 2) y no realizamos ninguna búsqueda de hiperparameter.
Agregamos una capa totalmente conectada con el número de clases y entrenamos la red para su clasificación con SoftMax y Entroly. La red entrena a ~ 99% de precisión. Extraemos incrustaciones 2 dimensionales de la penúltima capa:
Conjunto de tren:
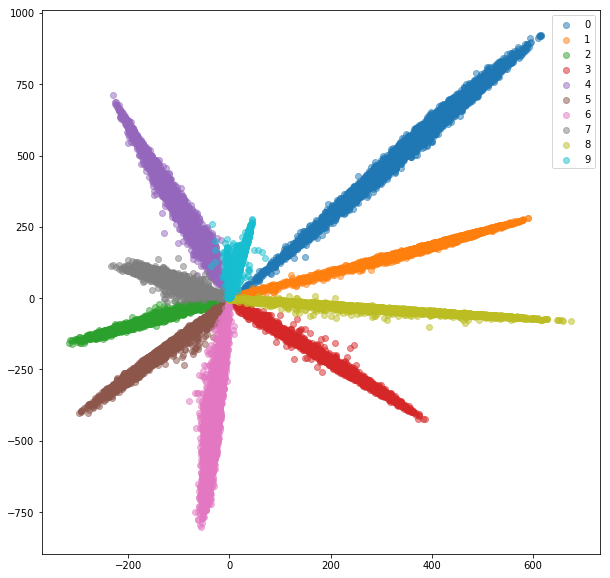
Conjunto de pruebas:
Mientras que las incrustaciones se ven separables (que es para lo que los entrenamos), no tienen buenas propiedades métricas. Puede que no sean la mejor opción como descriptor para nuevas clases.
Ahora entrenaremos una red siamesa que toma un par de imágenes y entrena los incrustaciones para que la distancia entre ellos se minimice si son de la misma clase y es mayor que algún valor de margen si representan diferentes clases. Minimizaremos una función de pérdida de contraste [1]:
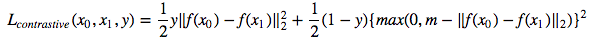
La clase siamesemnista muestras pares positivos y negativos aleatorios que luego se alimentan a la red siamesa.
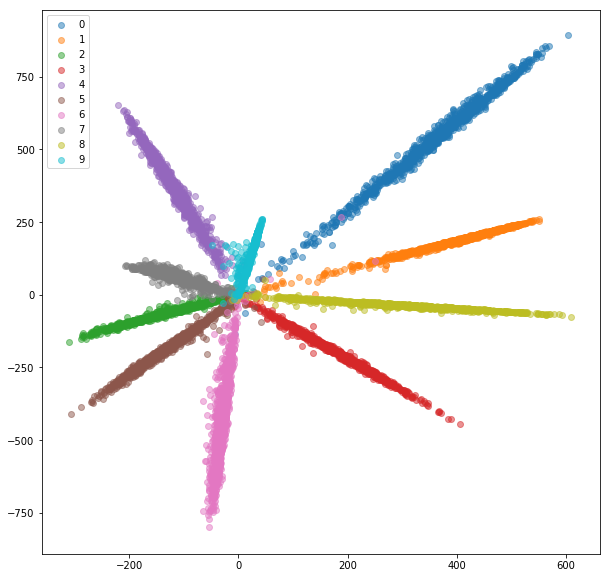
Después de 20 épocas de entrenamiento, aquí están los incrustaciones que recibimos para el conjunto de entrenamiento:
Conjunto de pruebas:
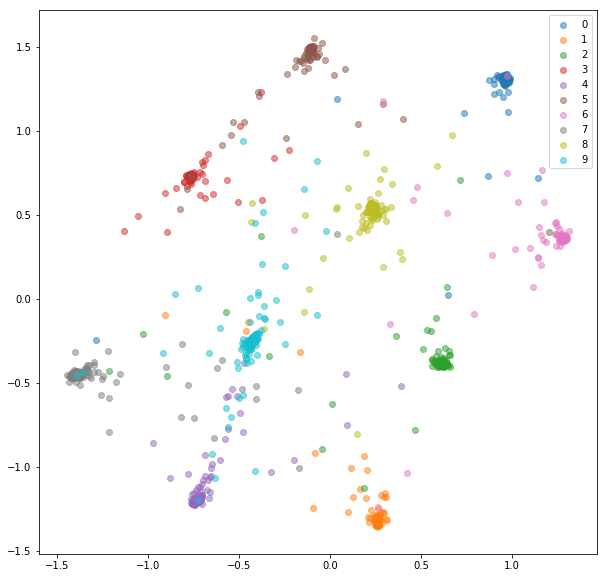
Las integridades aprendidas se agrupan mucho mejor dentro de la clase.
Entrenaremos una red de triplete, que toma un ancla, un ejemplo positivo (de la misma clase que un ancla) y negativo (de una clase diferente a un ancla). El objetivo es aprender incrustaciones de tal manera que el ancla esté más cerca del ejemplo positivo que el ejemplo negativo por algún valor de margen.
 Fuente: Schroff, Florian, Dmitry Kalenichenko y James Philbin. Facenet: una incrustación unificada para el reconocimiento y el agrupamiento de la cara. CVPR 2015.
Fuente: Schroff, Florian, Dmitry Kalenichenko y James Philbin. Facenet: una incrustación unificada para el reconocimiento y el agrupamiento de la cara. CVPR 2015.
Pérdida de triplete : 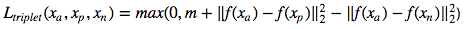
La clase TripletMnist muestras un ejemplo positivo y negativo para cada ancla posible.
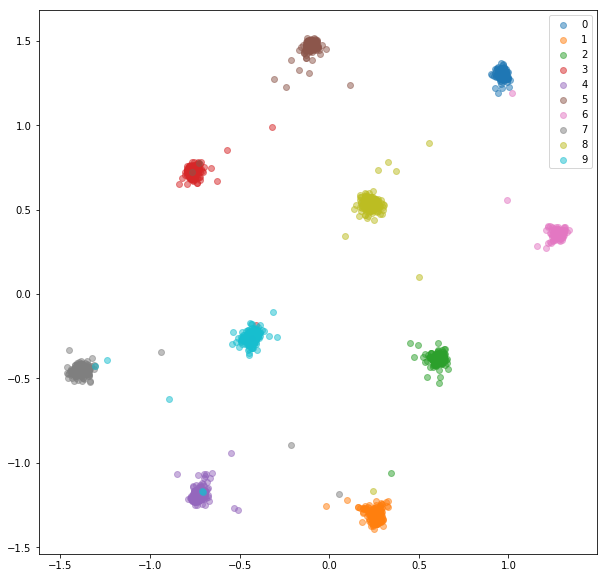
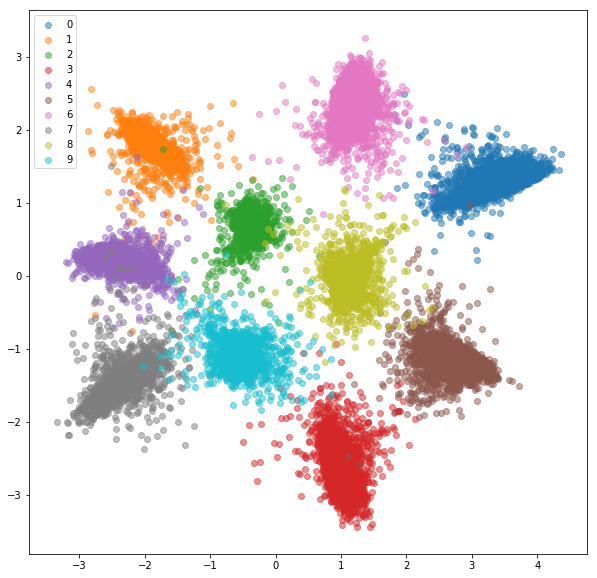
Después de 20 épocas de entrenamiento, aquí están los incrustaciones que recibimos para el conjunto de entrenamiento:
Conjunto de pruebas:
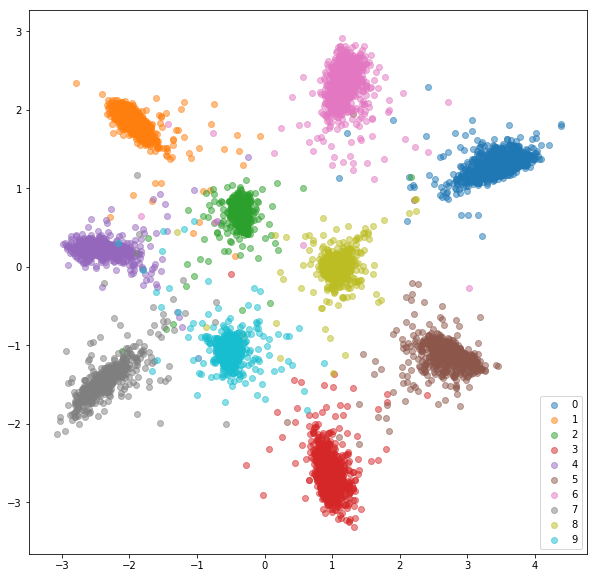
Las integridades aprendidas no son tan cercanas entre sí dentro de la clase como en el caso de la red siamesa, pero para eso no es lo que los optimizamos. Queríamos que los incrustaciones estuvieran más cerca de otros incrustaciones de la misma clase que de las otras clases y podemos ver que ahí es donde va a la capacitación.
Hay un par de problemas con las redes siamesas y triplete:
Para abordar estos problemas de manera eficiente, alimentaremos una red con mini lotes estándar como lo hicimos para la clasificación. La función de pérdida será responsable de la selección de pares y trillizos duros dentro de la mini lote. Si alimentamos la red con 16 imágenes por 10 clases, podemos procesar hasta 159*160/2 = 12720 pares y 10*16*15/2*(9*16) = 172800 trillizos, en comparación con 80 pares y 53 trillizos en la implementación previa.
Por lo general, no es la mejor idea para procesar todos los pares o trillizos posibles dentro de un mini lote. Podemos encontrar algunas estrategias sobre cómo seleccionar trillizos en [2] y [3].
Alimentaremos una red con mini lotes, como lo hicimos para la red de clasificación. Esta vez usaremos un muestreador de lotes especial que muestreará n_clases y n_samples dentro de cada clase, lo que resulta en mini lotes de tamaño n_classes*n_samples .
Para cada mini lote, se seleccionarán pares positivos y negativos utilizando etiquetas proporcionadas.
MNIST es un conjunto de datos bastante fácil y los incrustaciones de los pares seleccionados al azar ya eran bastante buenos, no vemos mucha mejora aquí.
INCREGOS DEL TRENO:
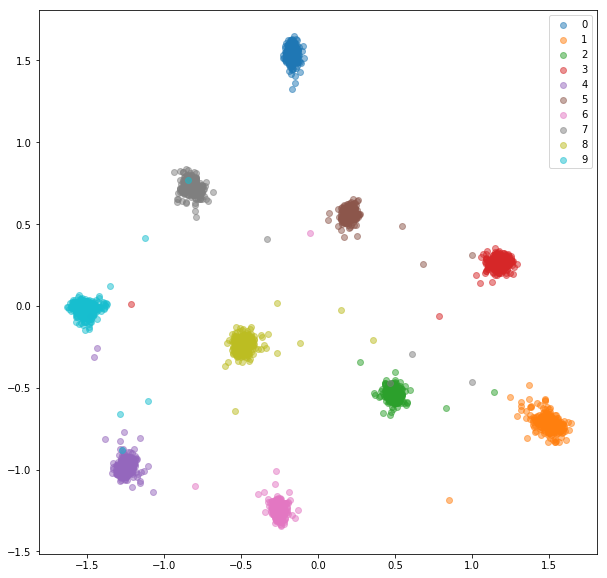
ENCUENTRA DE ENCUESTA:
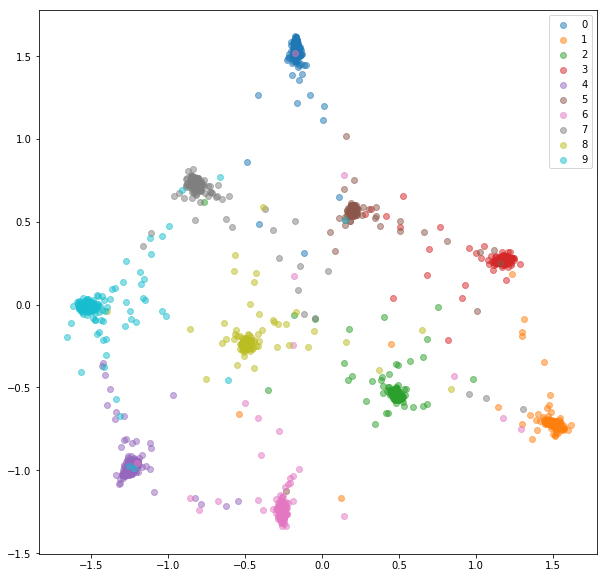
Alimentaremos una red con mini lotes como con la selección de pares en línea. Hay un par de estrategias que podemos usar para la selección de tripletes dadas las etiquetas y las integridades predichas:
La estrategia para la selección de triplete debe elegirse cuidadosamente. Una mala estrategia podría conducir a un entrenamiento ineficiente o, lo que es peor, a modelar el colapso (todas las embedidas terminan teniendo los mismos valores).
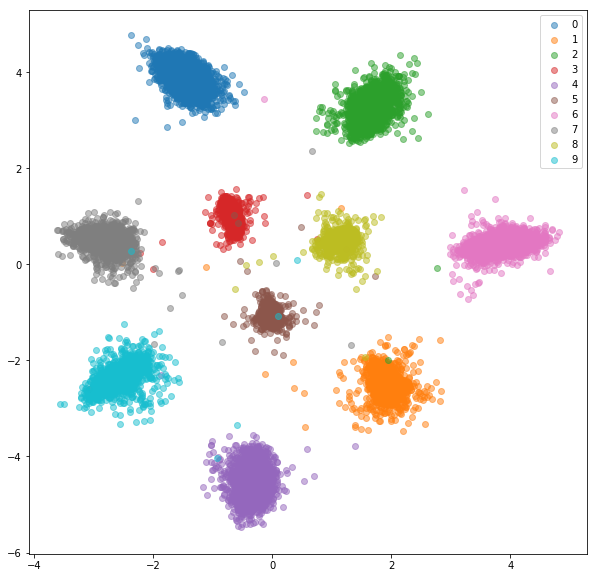
Esto es lo que tenemos con negativos duros al azar para cada par positivo.
Conjunto de entrenamiento:
Conjunto de pruebas:
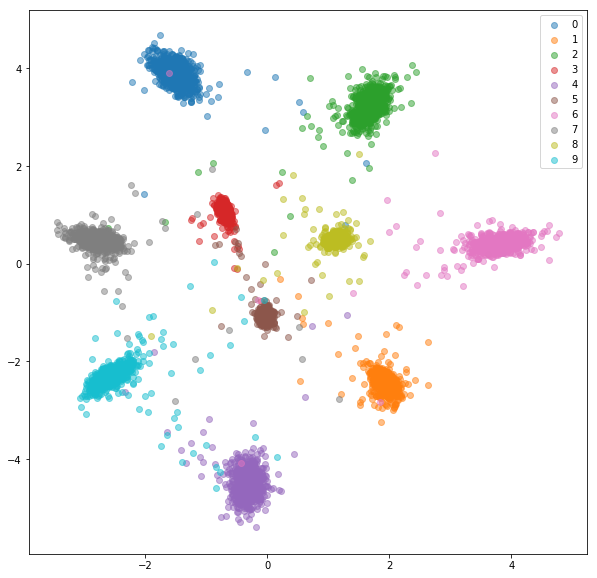
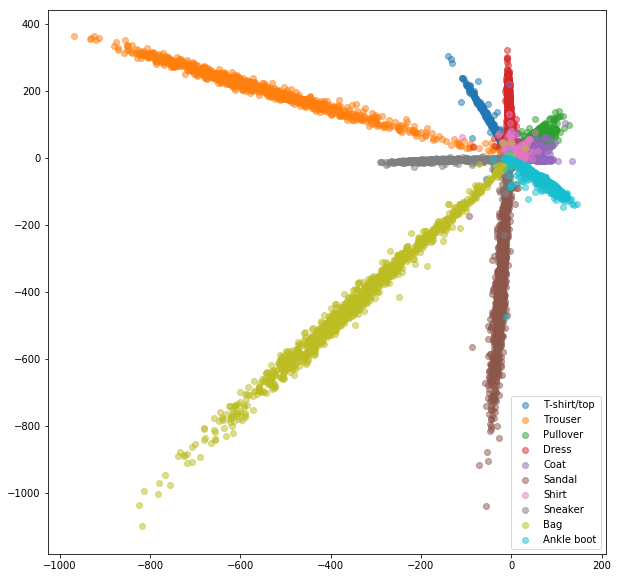
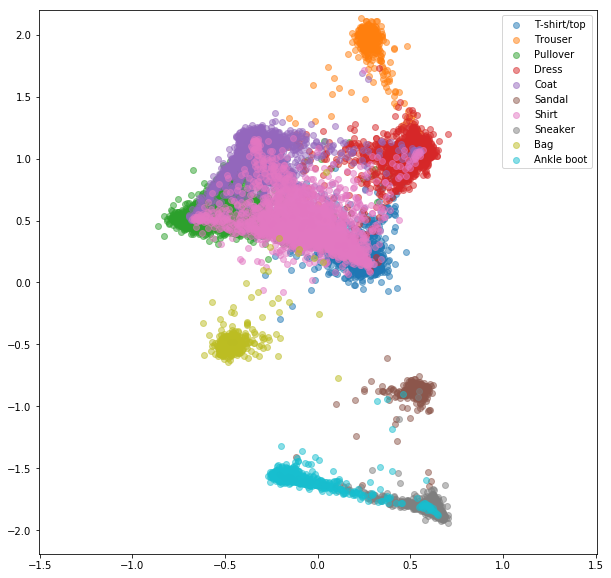
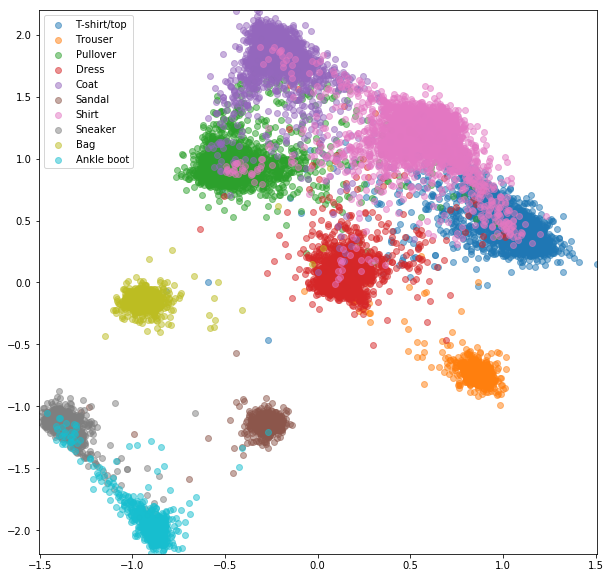
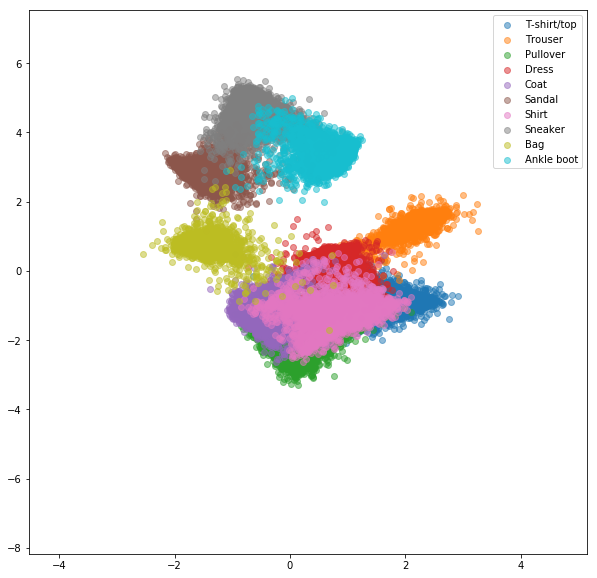
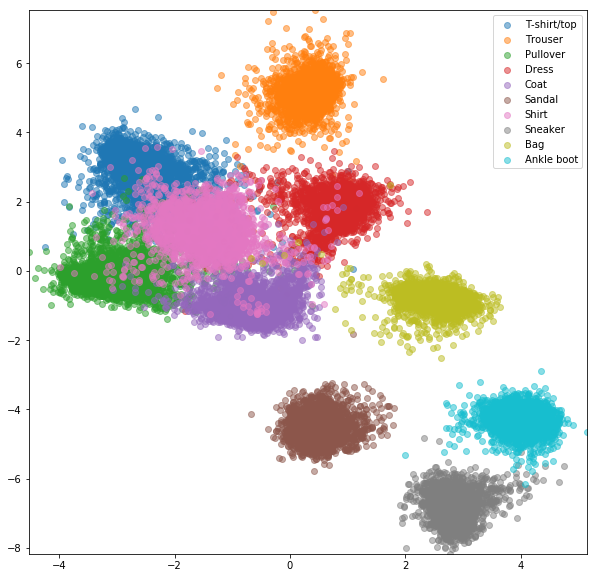
Se realizaron experimentos similares para el conjunto de datos FashionMnist, donde las ventajas de la minería negativa en línea son un poco más visibles. Se usó la misma arquitectura de red con solo integridades bidimensionales, lo que probablemente no sea lo suficientemente complejo como para aprender buenos incrustaciones. Los conjuntos de datos más complejos con clases de mayor número deberían beneficiarse aún más de la minería en línea.
Network siamese con pares seleccionados al azar
Pérdida de contraste en línea con minería negativa
Red de triplete con trillizos aleatorios
Pérdida de triplete en línea con minería negativa
[1] Raia Hadsell, Sumit Chopra, Yann Lecun, Reducción de la dimensionalidad al aprender un mapeo invariante, CVPR 2006
[2] Schroff, Florian, Dmitry Kalenichenko y James Philbin. Facenet: una incrustación unificada para el reconocimiento y el agrupamiento de la cara. CVPR 2015
[3] Alexander Hermans, Lucas Beyer, Bastian Leibe, en defensa de la pérdida de triplete para la reidentificación de la persona, 2017
[4] Brandon Amos, Bartosz Ludwiczuk, Mahadev Satyanarayanan, Openface: una biblioteca de reconocimiento facial de uso general con aplicaciones móviles, 2016
[5] Yi Sun, Xiaogang Wang, Xiaooou Tang, Deep Learning Face Representation por Verificación de identificación conjunta, NIPS 2014


