mdb openfga
1.0.0
การค้นหาเวกเตอร์ MongoDB ATLAS ช่วยให้การค้นหาความคล้ายคลึงกันมีประสิทธิภาพตามการเป็นตัวแทนของเวกเตอร์ สิ่งนี้เป็นประโยชน์อย่างยิ่งเมื่อทำงานกับข้อมูลที่ไม่มีโครงสร้างเช่นข้อความรูปภาพหรือเสียงที่การค้นหาตามคำหลักแบบดั้งเดิมอาจสั้นลง
ข้อดีที่สำคัญ:
การรวมเข้ากับ OpenFGA:
เมื่อรวมกับ OpenFGA การค้นหาเวกเตอร์ MongoDB ATLAS จะเป็นโซลูชันที่ทรงพลังสำหรับการเข้าถึงเอกสารที่ปลอดภัย คุณสามารถใช้การค้นหาเวกเตอร์เพื่อดึงเอกสารที่เกี่ยวข้องตามเนื้อหาของพวกเขาจากนั้นใช้กฎการควบคุมการเข้าถึงของ OpenFGA เพื่อให้แน่ใจว่าผู้ใช้ที่ได้รับอนุญาตเท่านั้นสามารถดูผลลัพธ์ได้
ตัวอย่าง:
ลองนึกภาพระบบการจัดการเอกสารที่ผู้ใช้สามารถค้นหาเอกสารตามเนื้อหาของพวกเขา ด้วยการใช้การค้นหาเวกเตอร์ MongoDB ATLAS คุณสามารถดึงเอกสารที่มีความหมายคล้ายกับแบบสอบถามของผู้ใช้อย่างมีประสิทธิภาพ OpenFGA สามารถใช้เพื่อบังคับใช้การควบคุมการเข้าถึงเพื่อให้มั่นใจว่าผู้ใช้จะเห็นเอกสารที่พวกเขาได้รับอนุญาตให้ดูเท่านั้น
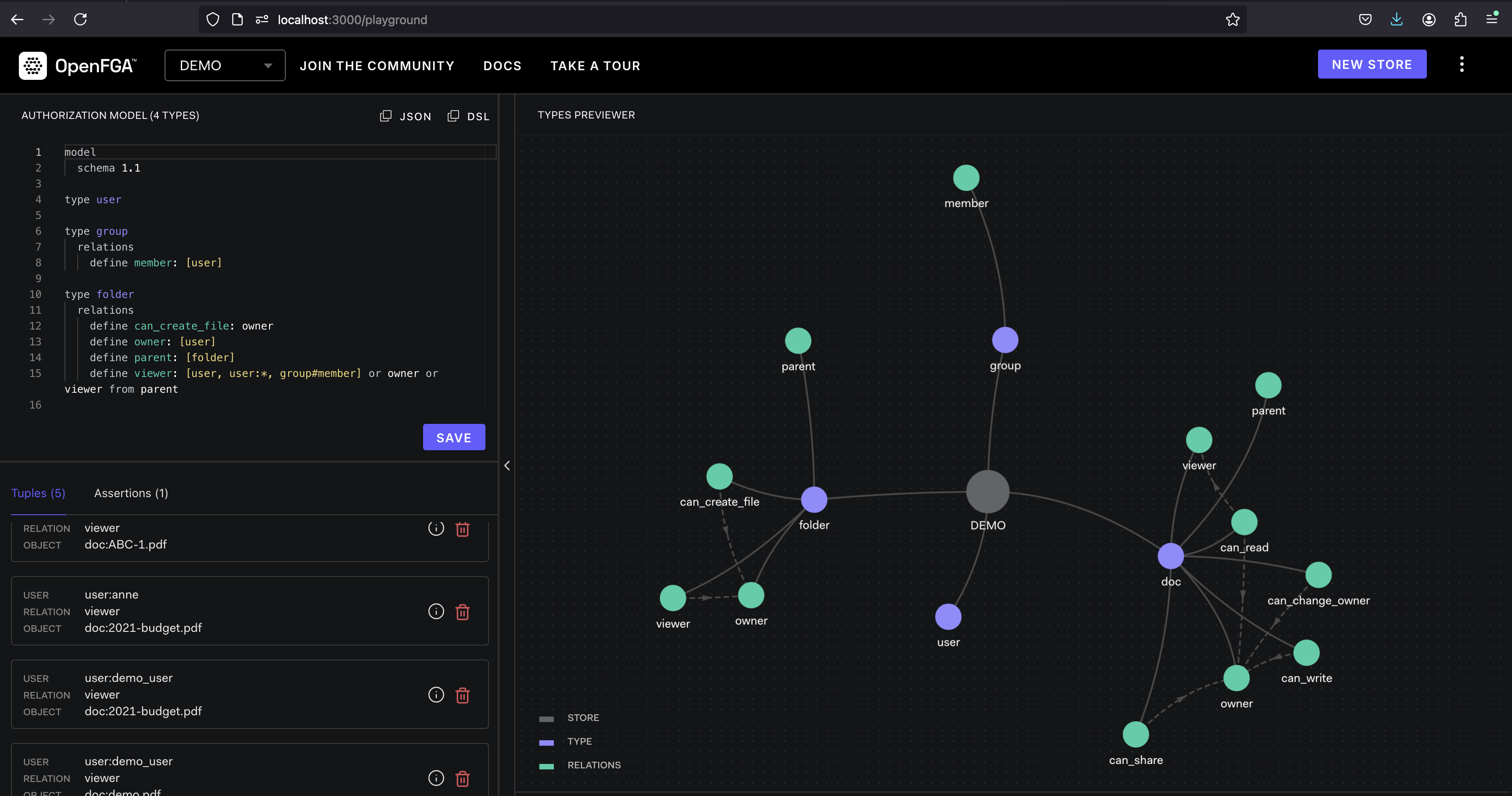
OpenFGA เป็นแพลตฟอร์มการอนุญาตโอเพนซอร์ซที่ออกแบบมาเพื่อให้การควบคุมการเข้าถึงที่ละเอียดสำหรับแอปพลิเคชันคลาวด์ มันมีโซลูชันที่ยืดหยุ่นและปรับขนาดได้สำหรับการจัดการสิทธิ์ของผู้ใช้และการเข้าถึงทรัพยากร
OpenFGA ดำเนินการกับแนวคิดของ Tuples tuple แสดงถึงการอนุญาตซึ่งประกอบด้วยผู้ใช้ความสัมพันธ์ (เช่น "อ่าน", "เขียน") และวัตถุ (เช่นไฟล์ฐานข้อมูล) นโยบายถูกกำหนดเพื่อระบุว่า tuples ใดได้รับอนุญาตหรือปฏิเสธ เมื่อผู้ใช้พยายามเข้าถึงทรัพยากร OpenFGA จะประเมิน tuple ที่เกี่ยวข้องกับนโยบายที่กำหนดเพื่อพิจารณาว่าได้รับหรือปฏิเสธการเข้าถึงหรือไม่
ดึงภาพ OpenFGA Docker:
docker pull openfga/openfgaเรียกใช้คอนเทนเนอร์ OpenFGA ด้วยพอร์ตที่เปิดเผย:
docker run -p 8080:8080 -p 3000:3000 openfga/openfga runดึง MongoDB Atlas Local Docker Image:
docker pull mongodb/mongodb-atlas-localเรียกใช้ MongoDB Atlas Local Container:
docker run -p 27017:27017 mongodb/mongodb-atlas-localส่วนนี้จะแนะนำคุณผ่านการสร้างดัชนีการค้นหาเวกเตอร์เพื่อค้นหาความคล้ายคลึงกันอย่างมีประสิทธิภาพภายในข้อมูล OpenFGA
เชื่อมต่อกับคลัสเตอร์ Atlas ในพื้นที่โดยใช้ mongosh :
mongosh " mongodb://localhost/demo?directConnection=true " สลับไปที่ฐานข้อมูล demo (แทนที่ด้วยชื่อฐานข้อมูลจริงของคุณหากจำเป็น):
use demo
สร้างดัชนีการค้นหาเวกเตอร์ชื่อ "vector_index" บนฟิลด์ "Embeddings":
db . mdb_fga . createSearchIndex (
"vector_index" ,
"vectorSearch" , // index type
{
fields : [
{
"type" : "vector" ,
"numDimensions" : 1536 ,
"path" : "embeddings" ,
"similarity" : "cosine"
} ,
]
}
) ;การติดตั้งไลบรารี Python ที่ต้องการ
pip install asyncio requests pymongo unstructured openai คำสั่งนี้ติดตั้งไลบรารีที่จำเป็นทั้งหมด ( asyncio , requests , pymongo , unstructured และ openai ) สำหรับการเรียกใช้รหัส Python
ไม่มีโครงสร้าง: การแยกความหมายจากเอกสาร
ไม่มีโครงสร้างช่วยให้คุณสามารถแยกเอกสารข้อความออกเป็นหน่วยที่เล็กกว่าและจัดการได้มากขึ้น ลองนึกภาพรายงานการวิจัย: ไม่มีโครงสร้างสามารถแบ่งออกเป็นส่วนย่อหน้าหรือแม้แต่ประโยคทำให้ง่ายต่อการประมวลผลและวิเคราะห์ ห้องสมุดยังช่วยแยกเอนทิตีเช่นชื่อวันที่และสถานที่ซึ่งช่วยในการดึงข้อมูล
OpenFGA: การเข้าถึงข้อมูลที่แยกออกมา
คุณกำหนดนโยบายที่ควบคุมการอนุญาตผู้ใช้ตามเงื่อนไขเฉพาะ เมื่อผู้ใช้พยายามเข้าถึงเอกสารหรือข้อมูลที่แยกออกมา OpenFGA จะประเมินผู้ใช้และเอกสารที่เกี่ยวข้องกับนโยบายเหล่านี้อนุญาตหรือปฏิเสธการเข้าถึง
การค้นหาเวกเตอร์ MongoDB Atlas: การค้นหาเอกสารที่คล้ายกันอย่างมีประสิทธิภาพ
ลองนึกภาพคุณกำลังค้นหาแนวคิดเฉพาะภายในคอลเลกชันเอกสาร การค้นหาตามคำหลักอาจพลาดเอกสารที่เกี่ยวข้องซึ่งไม่มีคำหลักที่แน่นอน อย่างไรก็ตามการค้นหาแบบเวกเตอร์วิเคราะห์การแสดงเวกเตอร์ของเนื้อหาเอกสารช่วยให้คุณค้นหาเอกสารที่คล้ายคลึงกันเชิงความหมายแม้ว่าพวกเขาจะใช้ถ้อยคำที่แตกต่างกัน
พลังของการรวมเครื่องมือเหล่านี้
ด้วยการรวมเครื่องมือทั้งสามนี้คุณจะสร้างระบบการจัดการเอกสารที่แข็งแกร่งและปลอดภัย นี่คือเวิร์กโฟลว์:
add_tuple ใน openfga ฟังก์ชั่น add_tuple ที่คุณเห็นในตัวอย่างโค้ดมีบทบาทสำคัญในการจัดการการควบคุมการเข้าถึงภายในแอปพลิเคชัน MDB-OpenFGA มันโต้ตอบกับ OpenFGA เพื่อให้สิทธิ์ผู้ใช้เพื่อดูทรัพยากรเฉพาะ
นี่คือรายละเอียดของวิธีการทำงานของ add_tuple :
ข้อโต้แย้ง:
USER : สิ่งนี้แสดงถึงผู้ใช้ที่คุณอนุญาตให้อนุญาต รหัสรูปแบบเป็น "user:"+USER เพื่อความสอดคล้องภายใน OpenFGARESOURCE : สิ่งนี้แสดงถึงทรัพยากรที่ผู้ใช้ได้รับอนุญาตให้เข้าถึง ในตัวอย่างมันถูกจัดรูปแบบเป็น "doc:"+RESOURCE (สมมติว่าเอกสาร)API CALL:
/stores/{store_id}/write ) จุดสิ้นสุดนี้ใช้สำหรับการเขียนข้อมูล (tuples) ไปยัง OpenFGA Storewrites : คีย์นี้ถือวัตถุที่ระบุ tuples ที่จะเพิ่มtuple_keys : นี่คืออาร์เรย์ที่มีวัตถุ tuple ที่กำหนดสิทธิ์ แต่ละวัตถุ tuple มีสามคุณสมบัติ:user : รหัสผู้ใช้ตามที่จัดรูปแบบก่อนหน้านี้relation : สิ่งนี้กำหนดประเภทของการอนุญาตที่ได้รับ ในกรณีนี้ตั้งค่าเป็น "viewer" เพื่อระบุการเข้าถึงการอ่านobject : รหัสทรัพยากรตามที่จัดรูปแบบก่อนหน้านี้authorization_model_id : สิ่งนี้ระบุ ID ของรูปแบบการอนุญาตที่ใช้ใน OpenFGA โมเดลนี้กำหนดกฎการควบคุมการเข้าถึงที่ควบคุมวิธีการประเมิน tuplesการตอบสนอง:
ในสาระสำคัญ add_tuple สร้าง tuple ใหม่ใน OpenFGA โดยระบุว่าผู้ใช้เฉพาะ ( USER ) มีสิทธิ์ดูทรัพยากรเฉพาะ ( RESOURCE ) tuple นี้จะถูกใช้โดยกลไกการควบคุมการเข้าถึงของ OpenFGA เพื่อพิจารณาว่าผู้ใช้ได้รับอนุญาตให้เข้าถึงทรัพยากรในระหว่างการร้องขอในอนาคตหรือไม่
check_authorization ใน mdb-openfga ฟังก์ชั่น check_authorization มีบทบาทสำคัญในแอปพลิเคชัน MDB-OpenFGA มันรับผิดชอบในการพิจารณาว่าผู้ใช้ที่ได้รับอนุญาตให้เข้าถึงทรัพยากรเฉพาะตามนโยบายการควบคุมการเข้าถึงที่กำหนดไว้ใน OpenFGA หรือไม่
มันทำงานอย่างไร:
ข้อโต้แย้ง:
tuple_key : นี่คือวัตถุ JSON ที่แสดงถึง tuple Tuple อย่างที่คุณทราบกำหนดการอนุญาต โดยทั่วไปจะมีสามคุณสมบัติ:user : รหัสผู้ใช้relation : ประเภทของการอนุญาต (เช่น "ผู้ชม", "บรรณาธิการ")object : รหัสทรัพยากรAPI CALL:
/stores/{store_id}/check จุดสิ้นสุดนี้ใช้เพื่อประเมิน tuple กับรูปแบบการอนุญาตที่กำหนดไว้authorization_model_id : ID ของรูปแบบการอนุญาตที่ใช้tuple_key : วัตถุ tuple ที่คุณต้องการตรวจสอบการตอบสนอง:
bool :true : ผู้ใช้ได้รับอนุญาตfalse : ผู้ใช้ไม่มีสิทธิ์ ในสาระสำคัญ check_authorization ใช้ tuple เป็นอินพุตและแบบสอบถาม OpenFGA เพื่อตรวจสอบว่าผู้ใช้ที่ระบุใน tuple ได้รับอนุญาตให้ดำเนินการ (ความสัมพันธ์) บนทรัพยากรที่ระบุ (วัตถุ) หรือไม่
เรียกใช้การสาธิต
python3 demo.py
Starting FGA setup...
FGA setup response: {'code': 'write_failed_due_to_invalid_input', 'message': "cannot write a tuple which already exists: user: 'user:demo_user', relation: 'viewer', object: 'doc:demo.pdf': invalid write input"}
Clearing the db first...
Database cleared.
Starting PDF document partitioning...
PDF partitioning and database insertion completed successfully.
Waiting for index to be updated. This may take a few seconds...
Starting search tool...
Access Granted: User 'demo_user' has permission to read document 'demo.pdf'.
Access Denied: User 'demo_user-denyme' does not have permission to read document 'demo.pdf'.
import asyncio
import requests
import json
import pymongo
from unstructured . partition . auto import partition
from openai import AzureOpenAI
class FGA_MDB_DEMO :
def __init__ ( self , azure_endpoint , api_version , api_key , mongo_uri , fga_api_url , fga_store_id , fga_api_token , authorization_model_id , db_name , collection_name ):
self . az_client = AzureOpenAI ( azure_endpoint = azure_endpoint , api_version = api_version , api_key = api_key )
self . mongo_client = pymongo . MongoClient ( mongo_uri )
self . fga_api_url = fga_api_url
self . fga_store_id = fga_store_id
self . fga_api_token = fga_api_token
self . authorization_model_id = authorization_model_id
self . db_name = db_name
self . collection_name = collection_name
def generate_embeddings ( self , text , model = "" ):
return self . az_client . embeddings . create ( input = [ text ], model = model ). data [ 0 ]. embedding
def check_authorization ( self , tuple_key ):
url = f" { self . fga_api_url } /stores/ { self . fga_store_id } /check"
headers = {
"Authorization" : f"Bearer { self . fga_api_token } " ,
"content-type" : "application/json" ,
}
data = {
"authorization_model_id" : self . authorization_model_id ,
"tuple_key" : tuple_key
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
return response . json ()
def add_tuple ( self , USER , RESOURCE ):
url = f" { self . fga_api_url } /stores/ { self . fga_store_id } /write"
headers = {
"Authorization" : f"Bearer { self . fga_api_token } " ,
"content-type" : "application/json" ,
}
data = {
"writes" : {
"tuple_keys" : [
{
"user" : "user:" + USER ,
"relation" : "viewer" ,
"object" : "doc:" + RESOURCE
}
]
},
"authorization_model_id" : self . authorization_model_id
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
return response . json ()
def search_tool ( self , text , USER_ID ):
response = self . mongo_client [ self . db_name ][ self . collection_name ]. aggregate ([
{
"$vectorSearch" : {
"index" : "vector_index" ,
"queryVector" : self . az_client . embeddings . create ( model = "text-embedding-ada-002" , input = text ). data [ 0 ]. embedding ,
"path" : "embeddings" ,
"limit" : 5 ,
"numCandidates" : 30
}
}, { "$project" :{ "_id" : 0 , "embeddings" : 0 , "metadata" : 0 }}
])
for doc in response :
tuple_key = { "user" : "user:" + USER_ID , "relation" : "viewer" , "object" : "doc:" + doc [ "source" ]}
response = self . check_authorization ( tuple_key )
if response [ 'allowed' ]:
print ( f"Access Granted: User ' { USER_ID } ' has permission to read document ' { doc [ 'source' ] } '." )
else :
print ( f"Access Denied: User ' { USER_ID } ' does not have permission to read document ' { doc [ 'source' ] } '." )
def partition_pdf ( self , resource ):
mdb_db = self . mongo_client [ self . db_name ]
mdb_collection = mdb_db [ self . collection_name ]
print ( "Clearing the db first..." )
mdb_collection . delete_many ({})
print ( "Database cleared." )
print ( "Starting PDF document partitioning..." )
elements = partition ( resource )
for element in elements :
mdb_collection . insert_one ({
"text" : str ( element . text ),
"embeddings" : self . generate_embeddings ( str ( element . text ), "text-embedding-ada-002" ),
"metadata" : {
"raw_element" : element . to_dict (),
},
"source" : resource
})
print ( "PDF partitioning and database insertion completed successfully." )
def fga_setup ( self , user , resource ):
response = self . add_tuple ( user , resource )
print ( f"FGA setup response: { response } " )
async def main ( self , user , resource ):
print ( "Starting FGA setup..." )
self . fga_setup ( user , resource )
self . partition_pdf ( resource )
print ( "Waiting for index to be updated. This may take a few seconds..." )
await asyncio . sleep ( 15 )
print ( "Starting search tool..." )
self . search_tool ( "test" , user )
self . search_tool ( "test" , user + "-denyme" )
print ( "Process completed successfully." )
if __name__ == "__main__" :
fga_mdb_demo = FGA_MDB_DEMO (
azure_endpoint = "" ,
api_version = "2024-04-01-preview" ,
api_key = "" ,
mongo_uri = "mongodb://localhost:27017/demo?directConnection=true" ,
fga_api_url = 'http://localhost:8080' ,
fga_store_id = '01J8VP1HYCHN459VT76DQG0W2R' ,
fga_api_token = '' ,
authorization_model_id = '01J8VP3BMPZNFJ480G5ZNF3H0C' ,
db_name = "demo" ,
collection_name = "mdb_fga"
)
asyncio . run ( fga_mdb_demo . main ( "demo_user" , "demo.pdf" ))

