mdb openfga
1.0.0
Mongodb Atlas Vector検索により、ベクトル表現に基づいて効率的な類似性検索が可能になります。これは、従来のキーワードベースの検索が不足する可能性のあるテキスト、画像、オーディオなどの非構造化データを使用する場合に特に有益です。
重要な利点:
OpenFGAとの統合:
OpenFGAと組み合わせると、Mongodb Atlas Vector Searchは、安全なドキュメントアクセスのための強力なソリューションを提供します。ベクトル検索を使用して、コンテンツに基づいて関連するドキュメントを取得し、OpenFGAのアクセス制御ルールを適用して、認定ユーザーのみが結果を表示できるようにします。
例:
ユーザーがコンテンツに基づいてドキュメントを検索できるドキュメント管理システムを想像してください。 Mongodb Atlas Vector検索を使用することにより、ユーザーのクエリと意味的に類似したドキュメントを効率的に取得できます。その後、OpenFGAを使用してアクセス制御を実施し、ユーザーが表示することが許可されているドキュメントのみを表示できるようにします。
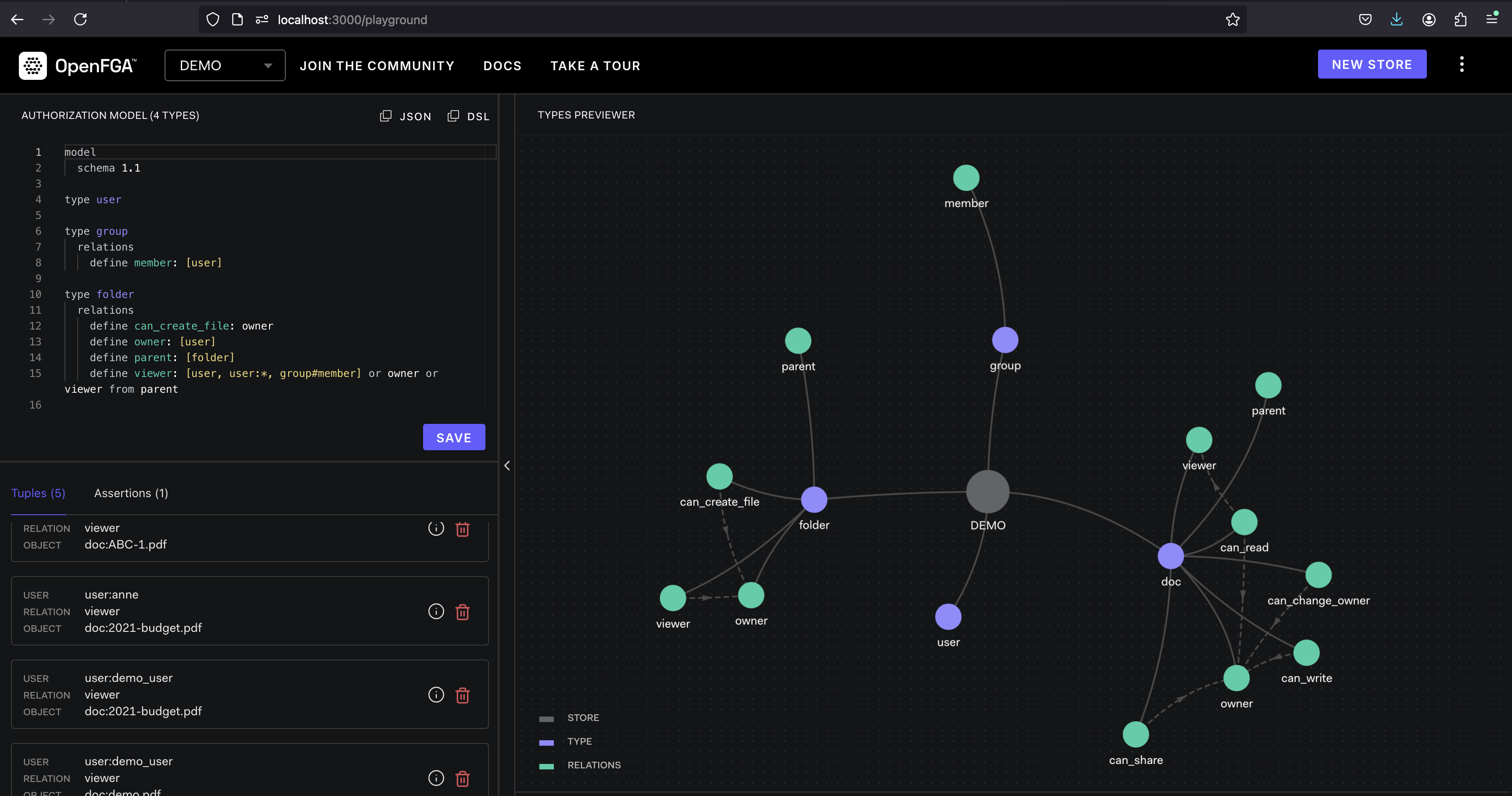
OpenFGAは、Cloud-Nativeアプリケーションに細粒のアクセス制御を提供するように設計されたオープンソースの認証プラットフォームです。ユーザーの許可とリソースへのアクセスを管理するための柔軟でスケーラブルなソリューションを提供します。
OpenFGAは、タプルの概念を操作します。タプルは、ユーザー、関係(「読み取り」、「書き込み」など)、およびオブジェクト(ファイル、データベースなど)で構成される許可を表します。ポリシーは、どのタプルが許可または拒否されるかを指定するために定義されています。ユーザーがリソースにアクセスしようとすると、OpenFGAは定義されたポリシーに対して対応するタプルを評価して、アクセスが許可されるか拒否されているかを判断します。
OpenFGA Docker画像を引く:
docker pull openfga/openfga露出したポートでOpenFGAコンテナを実行します。
docker run -p 8080:8080 -p 3000:3000 openfga/openfga runMongodb Atlas Local Docker画像を引く:
docker pull mongodb/mongodb-atlas-localMongodb Atlas Local Containerを実行します。
docker run -p 27017:27017 mongodb/mongodb-atlas-localこのセクションでは、OpenFGAデータ内の効率的な類似性検索のベクトル検索インデックスを作成することをガイドします。
mongoshを使用してローカルアトラスクラスターに接続します。
mongosh " mongodb://localhost/demo?directConnection=true " demoデータベースに切り替えます(必要に応じて実際のデータベース名に置き換えます):
use demo
「埋め込み」フィールドに「vector_index」という名前のベクトル検索インデックスを作成します。
db . mdb_fga . createSearchIndex (
"vector_index" ,
"vectorSearch" , // index type
{
fields : [
{
"type" : "vector" ,
"numDimensions" : 1536 ,
"path" : "embeddings" ,
"similarity" : "cosine"
} ,
]
}
) ;必要なPythonライブラリのインストール
pip install asyncio requests pymongo unstructured openaiこのコマンドは、Pythonコードを実行するために必要なすべてのライブラリ( asyncio 、 requests 、 pymongo 、 unstructured 、およびopenai )をインストールします。
非構造:ドキュメントから意味を抽出します
非構造化により、テキストドキュメントをより小さく、より管理しやすいユニットに分割することができます。研究論文を想像してみてください。非構造化は、セクション、段落、または文章に分割し、処理と分析を容易にすることができます。ライブラリは、情報の取得を支援する名前、日付、場所などのエンティティを抽出するのにも役立ちます。
OpenFGA:抽出されたデータへのアクセスを保護します
特定の条件に基づいてユーザー許可を管理するポリシーを定義します。ユーザーがドキュメントまたはその抽出されたデータにアクセスしようとすると、OpenFGAは対応するユーザーとこれらのポリシーに対してドキュメントを評価し、アクセスを許可または拒否します。
Mongodb Atlas Vector Search:同様のドキュメントを効率的に見つける
ドキュメントコレクション内で特定の概念を探していると想像してください。キーワードベースの検索では、正確なキーワードが含まれていない関連ドキュメントを見逃す可能性があります。ただし、ベクトル検索では、ドキュメントコンテンツのベクトル表現を分析し、異なる言葉遣いを使用しても、意味的に類似したドキュメントを見つけることができます。
これらのツールを組み合わせる力
これら3つのツールを統合することにより、堅牢で安全なドキュメント管理システムを作成します。これがワークフローです:
add_tupleを使用して権限を追加しますコードスニペットで見たadd_tuple関数は、MDB-OpenFGAアプリケーション内のアクセス制御を管理する上で重要な役割を果たします。 OpenFGAと対話して、特定のリソースを表示する許可をユーザーに付与します。
これは、 add_tupleどのように機能するかの内訳です:
議論:
USER :これは、許可を与えているユーザーを表します。コードは、OpenFGA内の一貫性のための"user:"+USERとしてフォーマットします。RESOURCE :これは、ユーザーがアクセスを許可されているリソースを表します。この例では、 "doc:"+RESOURCE (ドキュメントを想定)としてフォーマットされています。APIコール:
/stores/{store_id}/write )へのPOSTリクエストを構築します。このエンドポイントは、OpenFGAストアにデータ(タプル)を書き込むために使用されます。writes :このキーは、追加するタプルを指定するオブジェクトを保持します。tuple_keys :これは、権限を定義するタプルオブジェクトを含む配列です。各タプルオブジェクトには3つのプロパティがあります。user :先ほどフォーマットされたユーザーID。relation :これは、許可されている許可の種類を定義します。この場合、読み取りアクセスを示すために"viewer"に設定されています。object :以前にフォーマットされたリソースID。authorization_model_id :これは、OpenFGAで使用されている承認モデルのIDを指定します。このモデルは、タプルの評価方法を支配するアクセス制御ルールを定義します。応答:
本質的に、 add_tuple OpenFGAに新しいタプルを作成し、特定のユーザー( USER )が特定のリソース( RESOURCE )を表示する許可を持っていると述べています。このタプルは、OpenFGAのアクセス制御メカニズムによって使用され、ユーザーが将来のリクエスト中にリソースにアクセスすることを許可されているかどうかを判断します。
check_authorization理解check_authorization関数は、mdb-openfgaアプリケーションで重要な役割を果たします。 OpenFGAで定義されているアクセス制御ポリシーに基づいて、特定のユーザーが特定のリソースにアクセスする許可があるかどうかを判断する責任があります。
それがどのように機能するか:
議論:
tuple_key :これはタプルを表すJSONオブジェクトです。ご存知のように、タプルは許可を定義します。通常、3つのプロパティが含まれます。user :ユーザーID。relation :許可の種類(例:「視聴者」、「編集者」)。object :リソースID。APIコール:
/stores/{store_id}/checkにpostリクエストを送信します。このエンドポイントは、定義された承認モデルに対するタプルを評価するために使用されます。authorization_model_id :使用されている承認モデルのID。tuple_key :確認したいタプルオブジェクト。応答:
bool値が含まれています。true :ユーザーに許可があります。false :ユーザーには許可がありません。本質的に、 check_authorization入力としてタプルを取り、OpenFGAをクエリして、タプルで指定されたユーザーが指定されたリソース(オブジェクト)でアクション(関係)を実行できるかどうかを判断します。
デモを実行します
python3 demo.py
Starting FGA setup...
FGA setup response: {'code': 'write_failed_due_to_invalid_input', 'message': "cannot write a tuple which already exists: user: 'user:demo_user', relation: 'viewer', object: 'doc:demo.pdf': invalid write input"}
Clearing the db first...
Database cleared.
Starting PDF document partitioning...
PDF partitioning and database insertion completed successfully.
Waiting for index to be updated. This may take a few seconds...
Starting search tool...
Access Granted: User 'demo_user' has permission to read document 'demo.pdf'.
Access Denied: User 'demo_user-denyme' does not have permission to read document 'demo.pdf'.
import asyncio
import requests
import json
import pymongo
from unstructured . partition . auto import partition
from openai import AzureOpenAI
class FGA_MDB_DEMO :
def __init__ ( self , azure_endpoint , api_version , api_key , mongo_uri , fga_api_url , fga_store_id , fga_api_token , authorization_model_id , db_name , collection_name ):
self . az_client = AzureOpenAI ( azure_endpoint = azure_endpoint , api_version = api_version , api_key = api_key )
self . mongo_client = pymongo . MongoClient ( mongo_uri )
self . fga_api_url = fga_api_url
self . fga_store_id = fga_store_id
self . fga_api_token = fga_api_token
self . authorization_model_id = authorization_model_id
self . db_name = db_name
self . collection_name = collection_name
def generate_embeddings ( self , text , model = "" ):
return self . az_client . embeddings . create ( input = [ text ], model = model ). data [ 0 ]. embedding
def check_authorization ( self , tuple_key ):
url = f" { self . fga_api_url } /stores/ { self . fga_store_id } /check"
headers = {
"Authorization" : f"Bearer { self . fga_api_token } " ,
"content-type" : "application/json" ,
}
data = {
"authorization_model_id" : self . authorization_model_id ,
"tuple_key" : tuple_key
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
return response . json ()
def add_tuple ( self , USER , RESOURCE ):
url = f" { self . fga_api_url } /stores/ { self . fga_store_id } /write"
headers = {
"Authorization" : f"Bearer { self . fga_api_token } " ,
"content-type" : "application/json" ,
}
data = {
"writes" : {
"tuple_keys" : [
{
"user" : "user:" + USER ,
"relation" : "viewer" ,
"object" : "doc:" + RESOURCE
}
]
},
"authorization_model_id" : self . authorization_model_id
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
return response . json ()
def search_tool ( self , text , USER_ID ):
response = self . mongo_client [ self . db_name ][ self . collection_name ]. aggregate ([
{
"$vectorSearch" : {
"index" : "vector_index" ,
"queryVector" : self . az_client . embeddings . create ( model = "text-embedding-ada-002" , input = text ). data [ 0 ]. embedding ,
"path" : "embeddings" ,
"limit" : 5 ,
"numCandidates" : 30
}
}, { "$project" :{ "_id" : 0 , "embeddings" : 0 , "metadata" : 0 }}
])
for doc in response :
tuple_key = { "user" : "user:" + USER_ID , "relation" : "viewer" , "object" : "doc:" + doc [ "source" ]}
response = self . check_authorization ( tuple_key )
if response [ 'allowed' ]:
print ( f"Access Granted: User ' { USER_ID } ' has permission to read document ' { doc [ 'source' ] } '." )
else :
print ( f"Access Denied: User ' { USER_ID } ' does not have permission to read document ' { doc [ 'source' ] } '." )
def partition_pdf ( self , resource ):
mdb_db = self . mongo_client [ self . db_name ]
mdb_collection = mdb_db [ self . collection_name ]
print ( "Clearing the db first..." )
mdb_collection . delete_many ({})
print ( "Database cleared." )
print ( "Starting PDF document partitioning..." )
elements = partition ( resource )
for element in elements :
mdb_collection . insert_one ({
"text" : str ( element . text ),
"embeddings" : self . generate_embeddings ( str ( element . text ), "text-embedding-ada-002" ),
"metadata" : {
"raw_element" : element . to_dict (),
},
"source" : resource
})
print ( "PDF partitioning and database insertion completed successfully." )
def fga_setup ( self , user , resource ):
response = self . add_tuple ( user , resource )
print ( f"FGA setup response: { response } " )
async def main ( self , user , resource ):
print ( "Starting FGA setup..." )
self . fga_setup ( user , resource )
self . partition_pdf ( resource )
print ( "Waiting for index to be updated. This may take a few seconds..." )
await asyncio . sleep ( 15 )
print ( "Starting search tool..." )
self . search_tool ( "test" , user )
self . search_tool ( "test" , user + "-denyme" )
print ( "Process completed successfully." )
if __name__ == "__main__" :
fga_mdb_demo = FGA_MDB_DEMO (
azure_endpoint = "" ,
api_version = "2024-04-01-preview" ,
api_key = "" ,
mongo_uri = "mongodb://localhost:27017/demo?directConnection=true" ,
fga_api_url = 'http://localhost:8080' ,
fga_store_id = '01J8VP1HYCHN459VT76DQG0W2R' ,
fga_api_token = '' ,
authorization_model_id = '01J8VP3BMPZNFJ480G5ZNF3H0C' ,
db_name = "demo" ,
collection_name = "mdb_fga"
)
asyncio . run ( fga_mdb_demo . main ( "demo_user" , "demo.pdf" ))

