mdb openfga
1.0.0
La recherche vectorielle MongoDB Atlas permet des recherches de similitude efficaces basées sur des représentations vectorielles. Cela est particulièrement bénéfique lorsque vous travaillez avec des données non structurées comme le texte, les images ou l'audio, où les recherches traditionnelles basées sur les mots clés peuvent échouer.
Avantages clés:
Intégration avec OpenFGA:
Lorsqu'elle est combinée avec OpenFGA, la recherche de vecteurs MongoDB Atlas fournit une solution puissante pour l'accès aux documents sécurisés. Vous pouvez utiliser la recherche vectorielle pour récupérer des documents pertinents en fonction de leur contenu, puis appliquer les règles de contrôle d'accès d'OpenFGA pour garantir que seuls les utilisateurs autorisés peuvent afficher les résultats.
Exemple:
Imaginez un système de gestion de documents où les utilisateurs peuvent rechercher des documents en fonction de leur contenu. En utilisant la recherche vectorielle MongoDB Atlas, vous pouvez récupérer efficacement des documents sémantiquement similaires à la requête de l'utilisateur. OpenFGA peut ensuite être utilisé pour appliquer le contrôle d'accès, garantissant que les utilisateurs ne voient que des documents qu'ils sont autorisés à afficher.
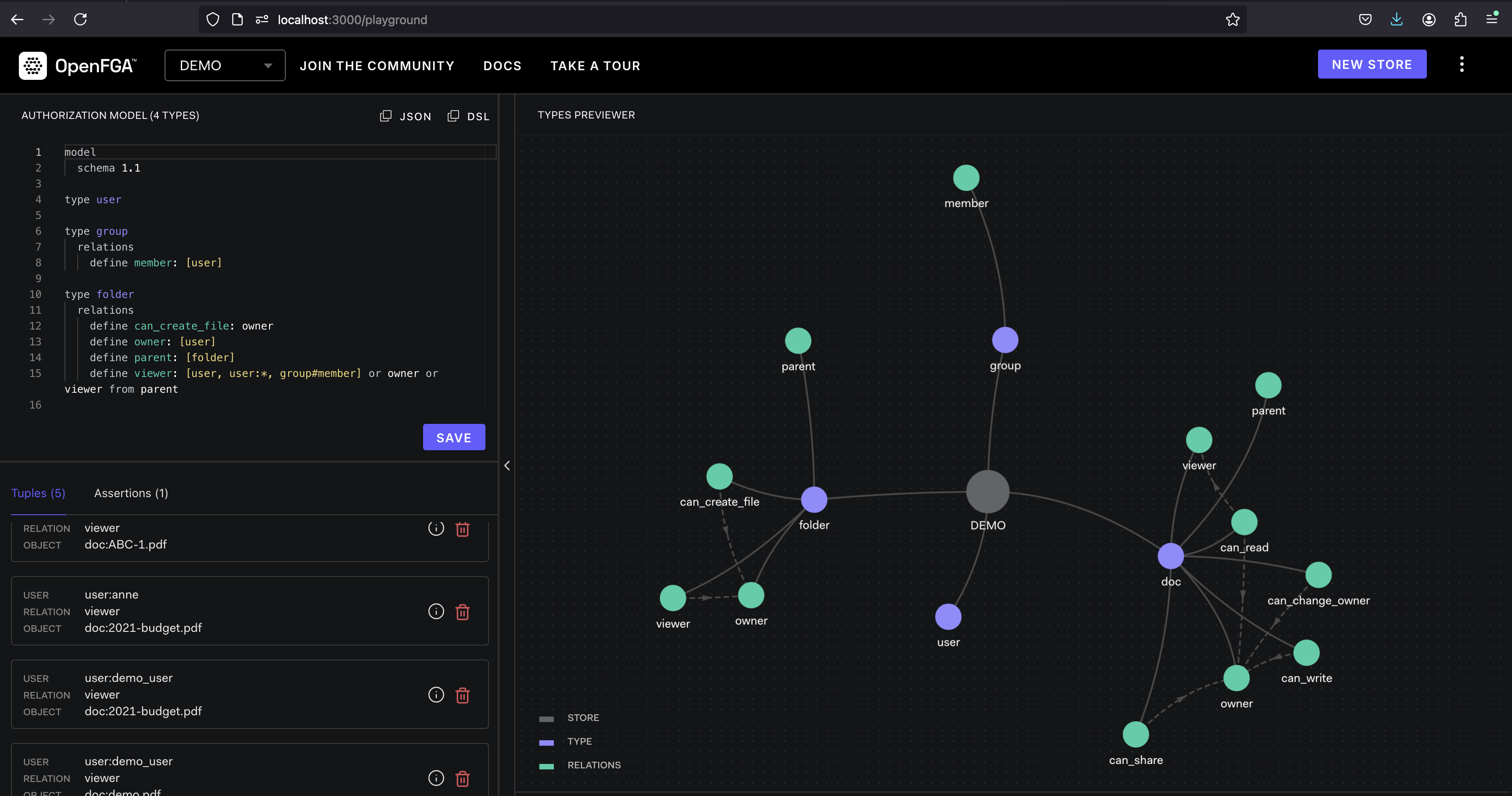
OpenFGA est une plate-forme d'autorisation open source conçue pour fournir un contrôle d'accès à grain fin pour les applications natives dans le cloud. Il offre une solution flexible et évolutive pour gérer les autorisations des utilisateurs et l'accès aux ressources.
OpenFGA fonctionne sur le concept de tuples . Un tuple représente une autorisation, composée d'un utilisateur, d'une relation (par exemple, "lire", "écrire") et un objet (par exemple, un fichier, une base de données). Les politiques sont définies pour spécifier quels tuples sont autorisés ou refusés. Lorsqu'un utilisateur essaie d'accéder à une ressource, OpenFGA évalue le tuple correspondant aux politiques définies pour déterminer si l'accès est accordé ou refusé.
Tirez l'image OpenFGA Docker:
docker pull openfga/openfgaExécutez le conteneur OpenFGA avec des ports exposés:
docker run -p 8080:8080 -p 3000:3000 openfga/openfga runTirez l'image de docker locale de l'atlas MongoDB:
docker pull mongodb/mongodb-atlas-localExécutez le conteneur local Mongodb Atlas:
docker run -p 27017:27017 mongodb/mongodb-atlas-localCette section vous guide à travers la création d'un index de recherche de vecteur pour des recherches de similitude efficaces dans les données OpenFGA.
Connectez-vous au cluster d'atlas local à l'aide mongosh :
mongosh " mongodb://localhost/demo?directConnection=true " Passez à la base de données demo (remplacez par votre nom de base de données réel si nécessaire):
use demo
Créer un index de recherche de vecteur nommé "vector_index" sur le champ "Embeddings":
db . mdb_fga . createSearchIndex (
"vector_index" ,
"vectorSearch" , // index type
{
fields : [
{
"type" : "vector" ,
"numDimensions" : 1536 ,
"path" : "embeddings" ,
"similarity" : "cosine"
} ,
]
}
) ;Installation des bibliothèques Python requises
pip install asyncio requests pymongo unstructured openai Cette commande installe toutes les bibliothèques nécessaires ( asyncio , requests , pymongo , unstructured et openai ) pour exécuter le code python.
Non structuré: extraire le sens des documents
Non structuré vous permet de décomposer des documents de texte en unités plus petites et plus gérables. Imaginez un document de recherche: non structuré peut le diviser en sections, paragraphes ou même phrases, ce qui facilite le traitement et l'analyse. La bibliothèque aide également à extraire des entités comme les noms, les dates et les emplacements, en aidant à la recherche d'informations.
OpenFGA: sécuriser l'accès aux données extraites
Vous définissez des politiques qui régissent les autorisations des utilisateurs en fonction de conditions spécifiques. Lorsqu'un utilisateur essaie d'accéder à un document ou à ses données extraites, OpenFGA évalue l'utilisateur et le document correspondants contre ces politiques, accordant ou refusant l'accès.
MongoDB Atlas Vector Search: Trouver des documents similaires efficacement
Imaginez que vous recherchez un concept spécifique dans une collection de documents. Les recherches basées sur les mots clés peuvent manquer des documents pertinents qui ne contiennent pas les mots clés exacts. La recherche vectorielle, cependant, analyse les représentations vectorielles du contenu du document, vous permettant de trouver des documents sémantiquement similaires, même s'ils utilisent des formules différentes.
La puissance de combiner ces outils
En intégrant ces trois outils, vous créez un système de gestion de documents robuste et sécurisé. Voici le workflow:
add_tuple dans openfga La fonction add_tuple que vous avez vue dans l'extrait de code joue un rôle crucial dans la gestion du contrôle d'accès dans l'application MDB-OpenFGA. Il interagit avec OpenFGA pour accorder à un utilisateur l'autorisation de visualiser une ressource spécifique.
Voici une ventilation du fonctionnement add_tuple :
Arguments:
USER : Cela représente l'utilisateur pour lequel vous accordez la permission. Le code le forme comme "user:"+USER pour la cohérence dans OpenFGA.RESOURCE : Cela représente la ressource à laquelle l'utilisateur a accès à. Dans l'exemple, il est formaté comme "doc:"+RESOURCE (en supposant des documents).Appel de l'API:
/stores/{store_id}/write ). Ce point de terminaison est utilisé pour écrire des données (tuples) dans la boutique OpenFGA.writes : Cette clé contient un objet spécifiant les tuples à ajouter.tuple_keys : Il s'agit d'un tableau contenant les objets Tuple définissant les autorisations. Chaque objet Tuple a trois propriétés:user : l'ID utilisateur comme formaté plus tôt.relation : Cela définit le type d'autorisation accordé. Dans ce cas, il est réglé sur "viewer" pour indiquer l'accès en lecture.object : l'ID de ressource comme formaté précédemment.authorization_model_id : Cela spécifie l'ID du modèle d'autorisation utilisé dans OpenFGA. Ce modèle définit les règles de contrôle d'accès qui régissent la façon dont les tuples sont évalués.Réponse:
Essentiellement, add_tuple crée un nouveau tuple dans OpenFGA, indiquant qu'un utilisateur spécifique ( USER ) a la permission de visualiser une ressource spécifique ( RESOURCE ). Ce tuple sera ensuite utilisé par les mécanismes de contrôle d'accès d'OpenFGA pour déterminer si l'utilisateur est autorisé à accéder à la ressource lors des demandes futures.
check_authorization dans MDB-OpenFGA La fonction check_authorization joue un rôle vital dans l'application MDB-OpenFGA. Il est chargé de déterminer si un utilisateur donné a la permission d'accéder à une ressource spécifique en fonction des stratégies de contrôle d'accès définies dans OpenFGA.
Comment ça marche:
Arguments:
tuple_key : Il s'agit d'un objet JSON qui représente un tuple. Un tuple, comme vous le savez, définit une autorisation. Il contient généralement trois propriétés:user : l'ID utilisateur.relation : Le type d'autorisation (par exemple, "Viewer", "Editor").object : l'ID de ressource.Appel de l'API:
/stores/{store_id}/check . Ce critère d'évaluation est utilisé pour évaluer un tuple contre le modèle d'autorisation défini.authorization_model_id : L'ID du modèle d'autorisation est utilisé.tuple_key : l'objet Tuple que vous souhaitez vérifier.Réponse:
bool :true : l'utilisateur a la permission.false : l'utilisateur n'a pas l'autorisation. Essentiellement, check_authorization prend un tuple en entrée et requêtes OpenFGA pour déterminer si l'utilisateur spécifié dans le tuple est autorisé à effectuer l'action (relation) sur la ressource spécifiée (objet).
Exécuter la démo
python3 demo.py
Starting FGA setup...
FGA setup response: {'code': 'write_failed_due_to_invalid_input', 'message': "cannot write a tuple which already exists: user: 'user:demo_user', relation: 'viewer', object: 'doc:demo.pdf': invalid write input"}
Clearing the db first...
Database cleared.
Starting PDF document partitioning...
PDF partitioning and database insertion completed successfully.
Waiting for index to be updated. This may take a few seconds...
Starting search tool...
Access Granted: User 'demo_user' has permission to read document 'demo.pdf'.
Access Denied: User 'demo_user-denyme' does not have permission to read document 'demo.pdf'.
import asyncio
import requests
import json
import pymongo
from unstructured . partition . auto import partition
from openai import AzureOpenAI
class FGA_MDB_DEMO :
def __init__ ( self , azure_endpoint , api_version , api_key , mongo_uri , fga_api_url , fga_store_id , fga_api_token , authorization_model_id , db_name , collection_name ):
self . az_client = AzureOpenAI ( azure_endpoint = azure_endpoint , api_version = api_version , api_key = api_key )
self . mongo_client = pymongo . MongoClient ( mongo_uri )
self . fga_api_url = fga_api_url
self . fga_store_id = fga_store_id
self . fga_api_token = fga_api_token
self . authorization_model_id = authorization_model_id
self . db_name = db_name
self . collection_name = collection_name
def generate_embeddings ( self , text , model = "" ):
return self . az_client . embeddings . create ( input = [ text ], model = model ). data [ 0 ]. embedding
def check_authorization ( self , tuple_key ):
url = f" { self . fga_api_url } /stores/ { self . fga_store_id } /check"
headers = {
"Authorization" : f"Bearer { self . fga_api_token } " ,
"content-type" : "application/json" ,
}
data = {
"authorization_model_id" : self . authorization_model_id ,
"tuple_key" : tuple_key
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
return response . json ()
def add_tuple ( self , USER , RESOURCE ):
url = f" { self . fga_api_url } /stores/ { self . fga_store_id } /write"
headers = {
"Authorization" : f"Bearer { self . fga_api_token } " ,
"content-type" : "application/json" ,
}
data = {
"writes" : {
"tuple_keys" : [
{
"user" : "user:" + USER ,
"relation" : "viewer" ,
"object" : "doc:" + RESOURCE
}
]
},
"authorization_model_id" : self . authorization_model_id
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
return response . json ()
def search_tool ( self , text , USER_ID ):
response = self . mongo_client [ self . db_name ][ self . collection_name ]. aggregate ([
{
"$vectorSearch" : {
"index" : "vector_index" ,
"queryVector" : self . az_client . embeddings . create ( model = "text-embedding-ada-002" , input = text ). data [ 0 ]. embedding ,
"path" : "embeddings" ,
"limit" : 5 ,
"numCandidates" : 30
}
}, { "$project" :{ "_id" : 0 , "embeddings" : 0 , "metadata" : 0 }}
])
for doc in response :
tuple_key = { "user" : "user:" + USER_ID , "relation" : "viewer" , "object" : "doc:" + doc [ "source" ]}
response = self . check_authorization ( tuple_key )
if response [ 'allowed' ]:
print ( f"Access Granted: User ' { USER_ID } ' has permission to read document ' { doc [ 'source' ] } '." )
else :
print ( f"Access Denied: User ' { USER_ID } ' does not have permission to read document ' { doc [ 'source' ] } '." )
def partition_pdf ( self , resource ):
mdb_db = self . mongo_client [ self . db_name ]
mdb_collection = mdb_db [ self . collection_name ]
print ( "Clearing the db first..." )
mdb_collection . delete_many ({})
print ( "Database cleared." )
print ( "Starting PDF document partitioning..." )
elements = partition ( resource )
for element in elements :
mdb_collection . insert_one ({
"text" : str ( element . text ),
"embeddings" : self . generate_embeddings ( str ( element . text ), "text-embedding-ada-002" ),
"metadata" : {
"raw_element" : element . to_dict (),
},
"source" : resource
})
print ( "PDF partitioning and database insertion completed successfully." )
def fga_setup ( self , user , resource ):
response = self . add_tuple ( user , resource )
print ( f"FGA setup response: { response } " )
async def main ( self , user , resource ):
print ( "Starting FGA setup..." )
self . fga_setup ( user , resource )
self . partition_pdf ( resource )
print ( "Waiting for index to be updated. This may take a few seconds..." )
await asyncio . sleep ( 15 )
print ( "Starting search tool..." )
self . search_tool ( "test" , user )
self . search_tool ( "test" , user + "-denyme" )
print ( "Process completed successfully." )
if __name__ == "__main__" :
fga_mdb_demo = FGA_MDB_DEMO (
azure_endpoint = "" ,
api_version = "2024-04-01-preview" ,
api_key = "" ,
mongo_uri = "mongodb://localhost:27017/demo?directConnection=true" ,
fga_api_url = 'http://localhost:8080' ,
fga_store_id = '01J8VP1HYCHN459VT76DQG0W2R' ,
fga_api_token = '' ,
authorization_model_id = '01J8VP3BMPZNFJ480G5ZNF3H0C' ,
db_name = "demo" ,
collection_name = "mdb_fga"
)
asyncio . run ( fga_mdb_demo . main ( "demo_user" , "demo.pdf" ))

