Stanford_LLM_Tutor
1.0.0
ที่เก็บนี้มีการใช้งานบอท AI ที่สร้างขึ้นโดยใช้โมเดลหม้อแปลง ( gpt2 ) จากการกอดใบหน้า chatbot ใช้ประโยชน์จากที่เก็บข้อมูลฐานข้อมูลเวกเตอร์เพื่อจับคู่แบบสอบถามผู้ใช้อย่างมีประสิทธิภาพกับข้อมูลที่เกี่ยวข้อง ข้อมูลที่ใช้สำหรับการฝึกอบรมและการสร้างการตอบสนองถูกคัดลอกมาจากหลักสูตร Stanford LLM อย่างเป็นทางการ
gpt2 จากการกอดใบหน้า การขูดข้อมูล : ข้อมูลถูกคัดลอกมาจากการบรรยายต่าง ๆ ของหลักสูตร Stanford LLM แท็ก h2 , h3 และ <strong> ทำหน้าที่เป็นคีย์และเนื้อหาที่เกี่ยวข้องถูกแบ่งออกเป็นย่อหน้า, ตาราง, ลิงก์, สมการ, รายการที่สั่งซื้อและรายการที่ไม่ได้เรียงลำดับ
ฐานข้อมูลเวกเตอร์ (FAISS) : คีย์จะถูกเก็บไว้ในฐานข้อมูลเวกเตอร์ FAISS โดยใช้ระยะทาง L2 สำหรับการดึงที่มีประสิทธิภาพ เมื่อได้รับแบบสอบถามผู้ใช้ FAISS จะพบคีย์การจับคู่ที่ใกล้เคียงที่สุด 2 อันดับแรกตามความคล้ายคลึงกันของเวกเตอร์
การสร้างพรอมต์ : chatbot สร้างพรอมต์ที่มีโครงสร้างโดยใช้ข้อมูลที่ดึงมาจาก FAISS พรอมต์นี้รวมถึงย่อหน้าตารางสมการลิงก์รายการที่สั่งซื้อและรายการที่ไม่ได้เรียงลำดับซึ่งเกี่ยวข้องกับคีย์ที่ตรงกัน
การสร้างการตอบสนอง : พรอมต์ที่สร้างขึ้นจะถูกป้อนเข้าสู่โมเดล GPT-2 เพื่อสร้างการตอบสนองที่สอดคล้องกันและเกี่ยวข้องกับแบบสอบถามผู้ใช้
ข้อมูลที่คัดลอกมาจากการบรรยายหลักสูตร Stanford LLM มีสคีมาต่อไปนี้:
key1:{
{
'paragraphs': [],
'tables': [],
'links': [],
'equations': [],
'ordered_lists': [],
'unordered_lists': []
} }
key2:{
{
'paragraphs': [],
'tables': [],
'links': [],
'equations': [],
'ordered_lists': [],
'unordered_lists': []
} }
แต่ละคีย์สอดคล้องกับแท็ก h2 , h3 หรือ <strong> จากหน้าบรรยาย ข้อมูลที่เกี่ยวข้องกับแต่ละคีย์รวมถึงย่อหน้าตารางลิงก์สมการรายการที่สั่งซื้อและรายการที่ไม่ได้เรียงลำดับหากมีอยู่
แบบสอบถามผู้ใช้ : "ประโยชน์และอันตรายคืออะไร"
FAISS Retrieval : แบบสอบถามถูกจับคู่กับคีย์ที่ใกล้เคียงที่สุด 2 อันดับแรกในฐานข้อมูลเวกเตอร์โดยใช้ระยะทาง L2
การก่อสร้างที่รวดเร็ว :
# Create a structured prompt
prompt = f"**Question:** {query}nn"
# Add top 2 matched sections
prompt += f"**Sections:**n- {result_key1}n- {result_key2}nn"
# Add content to the prompt
for result_key, result_content in [(result_key1, result_content1), (result_key2, result_content2)]:
if result_content.get('paragraphs'):
prompt += "**Paragraphs:**n" + "n".join(result_content['paragraphs']) + "nn"
if result_content.get('ordered_lists'):
prompt += "**Ordered Lists:**n" + "n".join(["n".join(ol) for ol in result_content['ordered_lists']]) + "nn"
if result_content.get('unordered_lists'):
prompt += "**Unordered Lists:**n" + "n".join(["n".join(ul) for ul in result_content['unordered_lists']]) + "nn"
if result_content.get('tables'):
prompt += "**Tables:**n" + "n".join(["n".join(table) for table in result_content['tables']]) + "nn"
if result_content.get('links'):
prompt += "**Links:**n" + "n".join(result_content['links']) + "nn"
if result_content.get('equations'):
prompt += "**Equations:**n" + "n".join(result_content['equations']) + "nn"
# Add a closing statement
prompt += "Answer is :"
# Define max_length
max_length = min(len(prompt) + 100, 750)
# Generate response
response = generator(prompt[:750], max_length=max_length, num_return_sequences=1, truncation=True, pad_token_id=50256)
การตอบสนองที่สร้างขึ้น : โมเดล GPT-2 ใช้พรอมต์เพื่อสร้างการตอบกลับโดยละเอียด
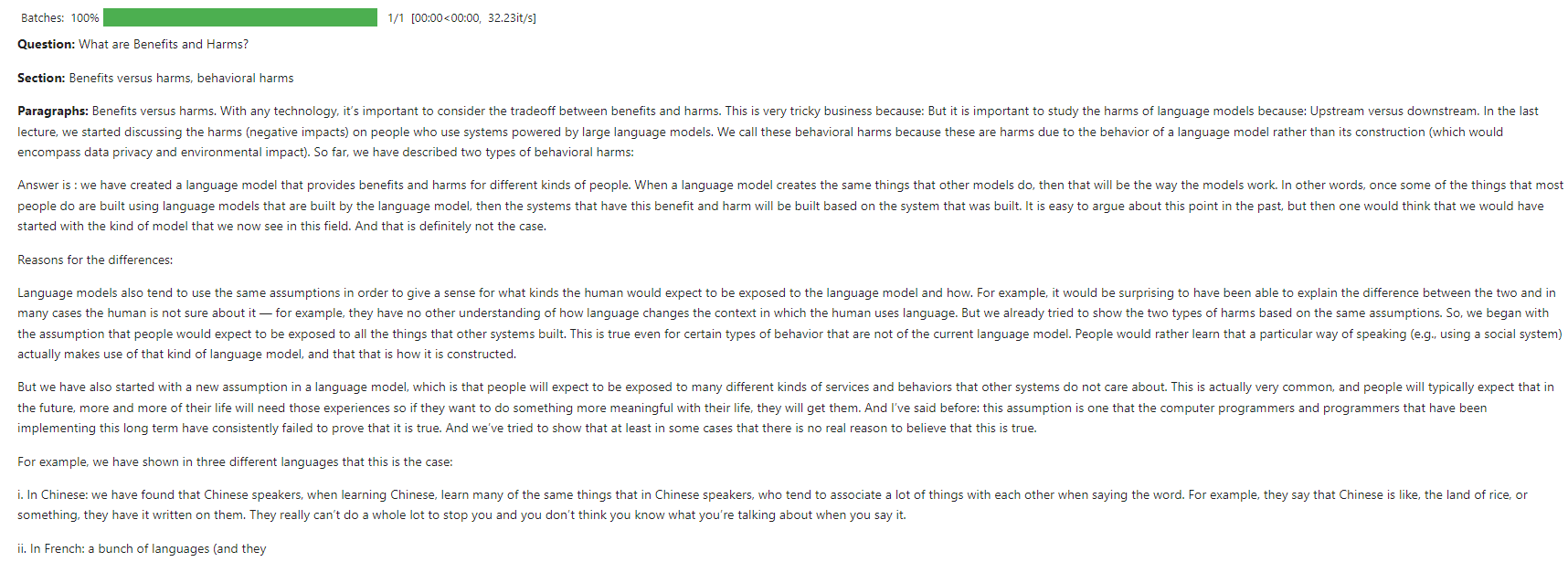
ภาพหน้าจอนี้แสดงตัวอย่างการโต้ตอบที่ chatbot ตอบกลับไปยังแบบสอบถามผู้ใช้เกี่ยวกับพื้นฐานของ LLM
แบบจำลองได้รับการฝึกฝนเกี่ยวกับ Kaggle โดยใช้ทรัพยากร CPU
ยินดีต้อนรับ! โปรดเปิดปัญหาหรือส่งคำขอดึงสำหรับการปรับปรุงหรือคุณสมบัติใหม่
โครงการนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต MIT ดูไฟล์ใบอนุญาตสำหรับรายละเอียด


