Stanford_LLM_Tutor
1.0.0
Dieses Repository enthält die Implementierung eines AI -Bots, das mit einem Transformatormodell ( gpt2 ) aus dem Umarmungsgesicht erstellt wurde. Der Chatbot nutzt FAISS für den Speicher der Vektordatenbank, um Benutzeranfragen mit relevanten Daten effizient zu übereinstimmen. Die für die Erzeugung von Schulungen und Reaktion verwendeten Daten wurden aus dem offiziellen Stanford LLM -Kurs abgekratzt.
gpt2 -Modell vom Umarmungsgesicht. Datenkratzen : Die Daten werden aus verschiedenen Vorträgen des Stanford LLM -Kurses abgeschafft. Die Tags h2 , h3 und <strong> dienen als Schlüssel, und der entsprechende Inhalt wird in Absätze, Tabellen, Links, Gleichungen, geordnete Listen und nicht ordnungsgemäße Listen eingeteilt.
Vektordatenbank (FAISS) : Die Tasten werden in einer FAISS -Vektor -Datenbank unter Verwendung der L2 -Distanz zum effizienten Abrufen gespeichert. Wenn eine Benutzerabfrage empfangen wird, findet FAISS die Top -2 -Anpassungsschlüssel basierend auf der Vektorähnlichkeit.
Schnellgenerierung : Der Chatbot konstruiert eine strukturierte Eingabeaufforderung unter Verwendung der von FAISS abgerufenen Daten. Diese Eingabeaufforderung enthält Absätze, Tabellen, Gleichungen, Links, geordnete Listen und ungeordnete Listen, die für die übereinstimmenden Schlüssel relevant sind.
Antwortgenerierung : Die konstruierte Eingabeaufforderung wird in das GPT-2-Modell eingespeist, um eine kohärente und relevante Antwort auf die Benutzerabfrage zu generieren.
Die Daten, die aus den Lectures der Stanford LLM -Kurse abkratzen, haben das folgende Schema:
key1:{
{
'paragraphs': [],
'tables': [],
'links': [],
'equations': [],
'ordered_lists': [],
'unordered_lists': []
} }
key2:{
{
'paragraphs': [],
'tables': [],
'links': [],
'equations': [],
'ordered_lists': [],
'unordered_lists': []
} }
Jeder Schlüssel entspricht h2 , h3 oder <strong> -Tags aus den Vorlesungsseiten. Die mit jedem Schlüssel zugeordneten Daten enthalten Absätze, Tabellen, Links, Gleichungen, geordnete Listen und ungeordnete Listen, wenn sie vorhanden sind.
Benutzerabfrage : "Was sind Vorteile und Schäden?"
FAISS RELUVALAL : Die Abfrage ist mit den Top -2 -Tasten in der Vektordatenbank mit der L2 -Distanz angepasst.
Sofortige Konstruktion :
# Create a structured prompt
prompt = f"**Question:** {query}nn"
# Add top 2 matched sections
prompt += f"**Sections:**n- {result_key1}n- {result_key2}nn"
# Add content to the prompt
for result_key, result_content in [(result_key1, result_content1), (result_key2, result_content2)]:
if result_content.get('paragraphs'):
prompt += "**Paragraphs:**n" + "n".join(result_content['paragraphs']) + "nn"
if result_content.get('ordered_lists'):
prompt += "**Ordered Lists:**n" + "n".join(["n".join(ol) for ol in result_content['ordered_lists']]) + "nn"
if result_content.get('unordered_lists'):
prompt += "**Unordered Lists:**n" + "n".join(["n".join(ul) for ul in result_content['unordered_lists']]) + "nn"
if result_content.get('tables'):
prompt += "**Tables:**n" + "n".join(["n".join(table) for table in result_content['tables']]) + "nn"
if result_content.get('links'):
prompt += "**Links:**n" + "n".join(result_content['links']) + "nn"
if result_content.get('equations'):
prompt += "**Equations:**n" + "n".join(result_content['equations']) + "nn"
# Add a closing statement
prompt += "Answer is :"
# Define max_length
max_length = min(len(prompt) + 100, 750)
# Generate response
response = generator(prompt[:750], max_length=max_length, num_return_sequences=1, truncation=True, pad_token_id=50256)
Erzeugte Antwort : Das GPT-2-Modell verwendet die Eingabeaufforderung, um eine detaillierte Antwort zu generieren.
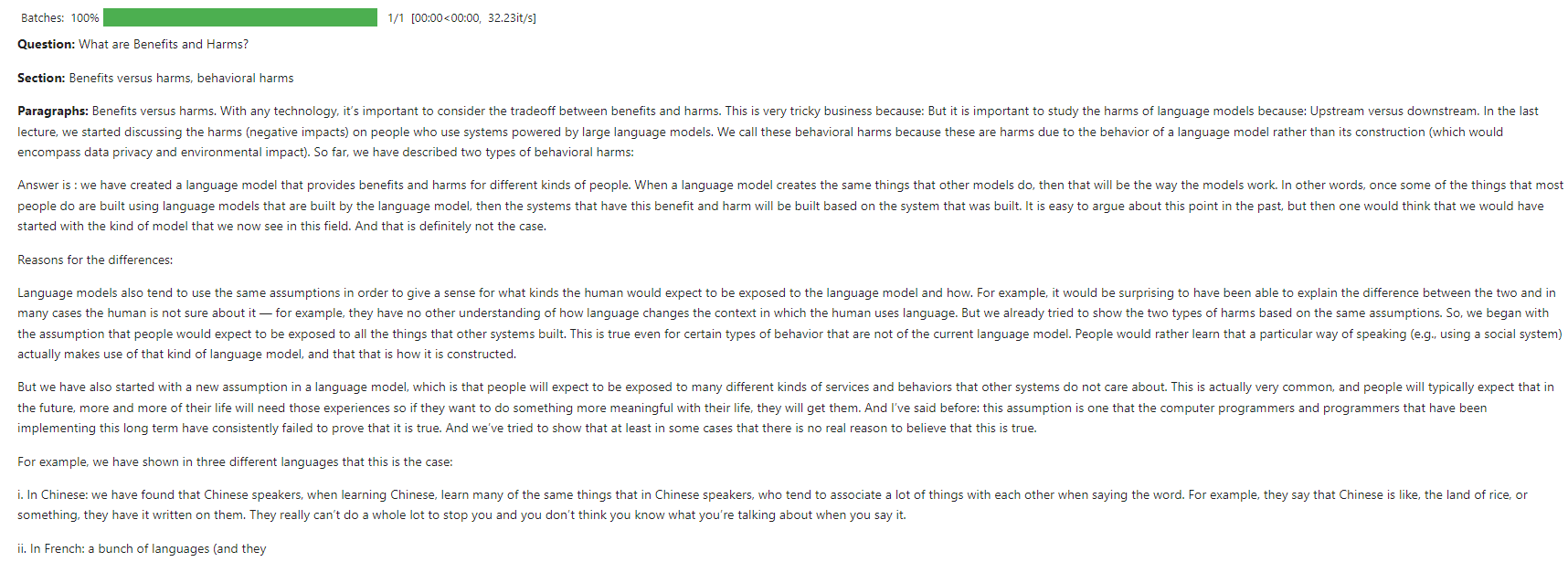
Dieser Screenshot zeigt eine Beispiel -Interaktion, bei der der Chatbot auf eine Benutzerabfrage zu den Grundlagen von LLMs reagiert.
Das Modell wurde mit CPU -Ressourcen auf Kaggle trainiert.
Beiträge sind willkommen! Bitte eröffnen Sie ein Problem oder senden Sie eine Pull -Anfrage für Verbesserungen oder neue Funktionen.
Dieses Projekt ist unter der MIT -Lizenz lizenziert. Weitere Informationen finden Sie in der Lizenzdatei.


