Stanford_LLM_Tutor
1.0.0
Este repositorio contiene la implementación de un bot AI construido utilizando un modelo de transformador ( gpt2 ) de abrazar la cara. El chatbot aprovecha FAISS para el almacenamiento de la base de datos vectorial para hacer coincidir eficientemente las consultas de los usuarios con datos relevantes. Los datos utilizados para la generación de capacitación y respuesta se eliminaron del curso oficial de Stanford LLM.
gpt2 de abrazar la cara. Raspado de datos : los datos se raspan de varias conferencias del curso de Stanford LLM. Las etiquetas h2 , h3 y <strong> sirven como claves, y el contenido correspondiente se clasifica en párrafos, tablas, enlaces, ecuaciones, listas ordenadas y listas desordenadas.
Base de datos vectorial (FAISS) : las claves se almacenan en una base de datos Vector FAISS utilizando una distancia L2 para una recuperación eficiente. Cuando se recibe una consulta de usuario, FAISS encuentra las 2 teclas de correspondencia más cercanas basadas en la similitud vectorial.
Generación de pedido : el chatbot construye un aviso estructurado utilizando los datos recuperados de FAISS. Este mensaje incluye párrafos, tablas, ecuaciones, enlaces, listas ordenadas y listas desordenadas como relevantes para las teclas coincidentes.
Generación de respuesta : el aviso construido se alimenta al modelo GPT-2 para generar una respuesta coherente y relevante a la consulta del usuario.
Los datos raspados de las conferencias del curso de Stanford LLM tienen el siguiente esquema:
key1:{
{
'paragraphs': [],
'tables': [],
'links': [],
'equations': [],
'ordered_lists': [],
'unordered_lists': []
} }
key2:{
{
'paragraphs': [],
'tables': [],
'links': [],
'equations': [],
'ordered_lists': [],
'unordered_lists': []
} }
Cada clave corresponde a etiquetas h2 , h3 o <strong> de las páginas de conferencias. Los datos asociados con cada clave incluyen párrafos, tablas, enlaces, ecuaciones, listas ordenadas y listas desordenadas si existen.
Consulta de usuario : "¿Cuáles son los beneficios y los daños?"
Recuperación FAISS : la consulta se combina con las 2 claves más cercanas en la base de datos de vectores utilizando la distancia L2.
Construcción rápida :
# Create a structured prompt
prompt = f"**Question:** {query}nn"
# Add top 2 matched sections
prompt += f"**Sections:**n- {result_key1}n- {result_key2}nn"
# Add content to the prompt
for result_key, result_content in [(result_key1, result_content1), (result_key2, result_content2)]:
if result_content.get('paragraphs'):
prompt += "**Paragraphs:**n" + "n".join(result_content['paragraphs']) + "nn"
if result_content.get('ordered_lists'):
prompt += "**Ordered Lists:**n" + "n".join(["n".join(ol) for ol in result_content['ordered_lists']]) + "nn"
if result_content.get('unordered_lists'):
prompt += "**Unordered Lists:**n" + "n".join(["n".join(ul) for ul in result_content['unordered_lists']]) + "nn"
if result_content.get('tables'):
prompt += "**Tables:**n" + "n".join(["n".join(table) for table in result_content['tables']]) + "nn"
if result_content.get('links'):
prompt += "**Links:**n" + "n".join(result_content['links']) + "nn"
if result_content.get('equations'):
prompt += "**Equations:**n" + "n".join(result_content['equations']) + "nn"
# Add a closing statement
prompt += "Answer is :"
# Define max_length
max_length = min(len(prompt) + 100, 750)
# Generate response
response = generator(prompt[:750], max_length=max_length, num_return_sequences=1, truncation=True, pad_token_id=50256)
Respuesta generada : el modelo GPT-2 utiliza el indicador para generar una respuesta detallada.
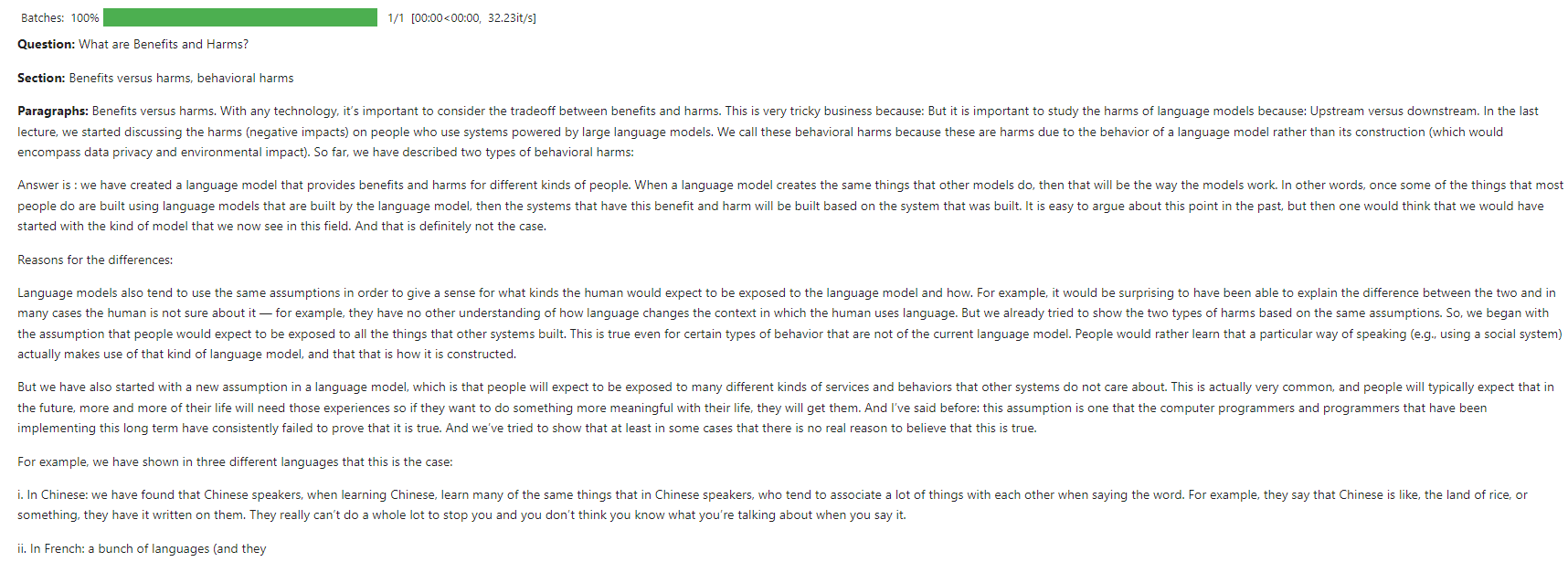
Esta captura de pantalla muestra una interacción de ejemplo en la que el chatbot responde a una consulta de usuario sobre los conceptos básicos de los LLM.
El modelo fue entrenado en Kaggle utilizando recursos de CPU.
¡Las contribuciones son bienvenidas! Abra un problema o envíe una solicitud de extracción para cualquier mejoras o nuevas funciones.
Este proyecto tiene licencia bajo la licencia MIT. Consulte el archivo de licencia para obtener más detalles.


