Stanford_LLM_Tutor
1.0.0
Este repositório contém a implementação de um bot da IA construído usando um modelo de transformador ( gpt2 ) de abraçar o rosto. O chatbot utiliza o FAISS for Vector Database Storage para corresponder com eficiência às consultas do usuário com dados relevantes. Os dados utilizados para o treinamento e a geração de respostas foram raspados no curso oficial de Stanford LLM.
gpt2 de abraçar o rosto. Raspagem de dados : os dados são raspados de várias palestras do curso Stanford LLM. As tags h2 , h3 e <strong> servem como chaves, e o conteúdo correspondente é categorizado em parágrafos, tabelas, links, equações, listas ordenadas e listas não ordenadas.
Banco de dados vetorial (FAISS) : As teclas são armazenadas em um banco de dados Vector FAISS usando a distância L2 para recuperação eficiente. Quando uma consulta de usuário é recebida, o FAISS encontra as duas principais teclas correspondentes mais próximas com base na similaridade vetorial.
Geração de prompt : o chatbot constrói um prompt estruturado usando os dados recuperados do FAISS. Este prompt inclui parágrafos, tabelas, equações, links, listas ordenadas e listas não ordenadas como relevantes para as chaves correspondentes.
Geração de resposta : o prompt construído é alimentado no modelo GPT-2 para gerar uma resposta coerente e relevante à consulta do usuário.
Os dados raspados das palestras do curso de Stanford LLM têm o seguinte esquema:
key1:{
{
'paragraphs': [],
'tables': [],
'links': [],
'equations': [],
'ordered_lists': [],
'unordered_lists': []
} }
key2:{
{
'paragraphs': [],
'tables': [],
'links': [],
'equations': [],
'ordered_lists': [],
'unordered_lists': []
} }
Cada tecla corresponde a tags h2 , h3 ou <strong> das páginas de aula. Os dados associados a cada chave incluem parágrafos, tabelas, links, equações, listas ordenadas e listas não ordenadas, se existirem.
Consulta do usuário : "O que são benefícios e danos?"
Recuperação do FAISS : a consulta é correspondida às duas principais teclas mais próximas no banco de dados vetorial usando a distância L2.
Construção imediata :
# Create a structured prompt
prompt = f"**Question:** {query}nn"
# Add top 2 matched sections
prompt += f"**Sections:**n- {result_key1}n- {result_key2}nn"
# Add content to the prompt
for result_key, result_content in [(result_key1, result_content1), (result_key2, result_content2)]:
if result_content.get('paragraphs'):
prompt += "**Paragraphs:**n" + "n".join(result_content['paragraphs']) + "nn"
if result_content.get('ordered_lists'):
prompt += "**Ordered Lists:**n" + "n".join(["n".join(ol) for ol in result_content['ordered_lists']]) + "nn"
if result_content.get('unordered_lists'):
prompt += "**Unordered Lists:**n" + "n".join(["n".join(ul) for ul in result_content['unordered_lists']]) + "nn"
if result_content.get('tables'):
prompt += "**Tables:**n" + "n".join(["n".join(table) for table in result_content['tables']]) + "nn"
if result_content.get('links'):
prompt += "**Links:**n" + "n".join(result_content['links']) + "nn"
if result_content.get('equations'):
prompt += "**Equations:**n" + "n".join(result_content['equations']) + "nn"
# Add a closing statement
prompt += "Answer is :"
# Define max_length
max_length = min(len(prompt) + 100, 750)
# Generate response
response = generator(prompt[:750], max_length=max_length, num_return_sequences=1, truncation=True, pad_token_id=50256)
Resposta gerada : o modelo GPT-2 usa o prompt para gerar uma resposta detalhada.
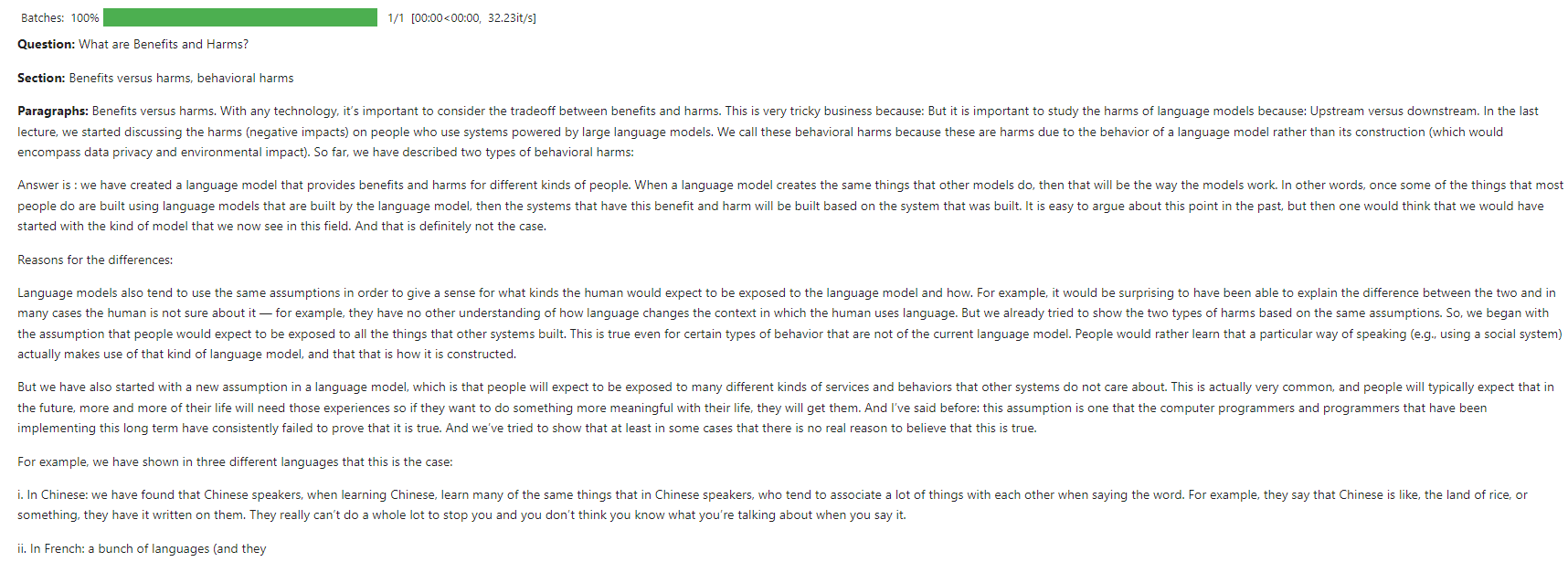
Esta captura de tela mostra um exemplo de interação em que o chatbot responde a uma consulta de usuário sobre o básico do LLMS.
O modelo foi treinado em Kaggle usando recursos da CPU.
As contribuições são bem -vindas! Abra um problema ou envie uma solicitação de tração para obter melhorias ou novos recursos.
Este projeto está licenciado sob a licença do MIT. Consulte o arquivo de licença para obter detalhes.


