realtime vector embeddings
1.0.0
 โครงการนี้ถูกสร้างขึ้นเพื่อทำความเข้าใจว่าข้อความที่แตกต่างกันนั้นมีความแตกต่างกันอย่างไรในพื้นที่หลายมิติ นี่เป็นแนวคิดที่สำคัญในงานการประมวลผลภาษาธรรมชาติ (NLP) เช่นการจำแนกประเภทข้อความการจัดกลุ่มและระบบการแนะนำ
โครงการนี้ถูกสร้างขึ้นเพื่อทำความเข้าใจว่าข้อความที่แตกต่างกันนั้นมีความแตกต่างกันอย่างไรในพื้นที่หลายมิติ นี่เป็นแนวคิดที่สำคัญในงานการประมวลผลภาษาธรรมชาติ (NLP) เช่นการจำแนกประเภทข้อความการจัดกลุ่มและระบบการแนะนำ
โครงการนี้เป็นส่วนหนึ่งของ llamapp
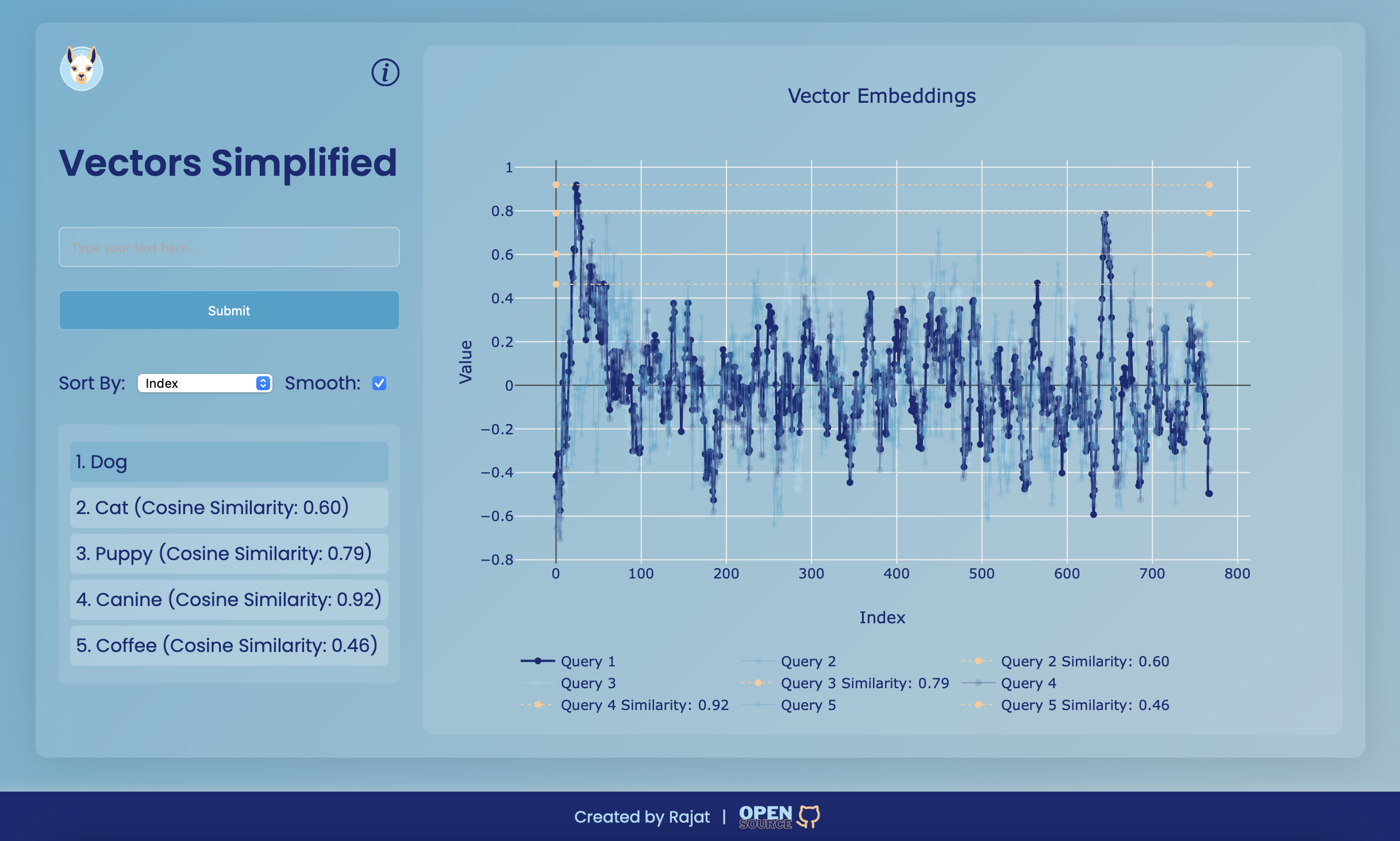
Vectors Simplified เป็นเว็บแอปพลิเคชันที่ออกแบบมาเพื่อแสดงภาพการฝังตัวของเวกเตอร์ โครงการนี้ให้อินเทอร์เฟซที่ใช้งานง่ายเพื่อป้อนข้อความสร้างการฝังเวกเตอร์และแสดงภาพความคล้ายคลึงกันโดยใช้พล็อตแบบโต้ตอบ แกนกลางของแอปพลิเคชันแสดงให้เห็นถึงแนวคิดของความคล้ายคลึงกันของโคไซน์ระหว่างเวกเตอร์ทำให้ง่ายต่อการเข้าใจว่าข้อความที่แตกต่างกันนั้นมีความแตกต่างกันอย่างไรในพื้นที่หลายมิติ
การฝังเวกเตอร์เป็นตัวแทนเชิงตัวเลขของข้อความที่จับความหมายทางความหมายในพื้นที่มิติสูง พวกเขาใช้ในงานการประมวลผลภาษาธรรมชาติ (NLP) ต่างๆเช่นการจำแนกประเภทข้อความการจัดกลุ่มและระบบแนะนำ แต่ละเวกเตอร์ประกอบด้วยส่วนประกอบหลายอย่างที่เข้ารหัสข้อมูลเกี่ยวกับคุณสมบัติของข้อความ
ความคล้ายคลึงกันของโคไซน์เป็นตัวชี้วัดที่ใช้ในการวัดว่าเวกเตอร์สองตัวที่คล้ายกันนั้นขึ้นอยู่กับโคไซน์ของมุมระหว่างพวกเขา มันมีตั้งแต่ -1 (แตกต่างกันอย่างสมบูรณ์) ถึง 1 (คล้ายกันอย่างสมบูรณ์) มีการใช้กันอย่างแพร่หลายในการวิเคราะห์ข้อความเพื่อพิจารณาว่าข้อความสองชิ้นที่คล้ายกันนั้นขึ้นอยู่กับการเป็นตัวแทนของเวกเตอร์
นี่คือตัวอย่างง่ายๆของความคล้ายคลึงกันของโคไซน์ทำงานกับเวกเตอร์พื้นฐาน:
function calculateCosineSimilarity ( vec1 , vec2 ) {
const dotProduct = vec1 . reduce ( ( acc , val , idx ) => acc + val * vec2 [ idx ] , 0 ) ;
const magnitude1 = Math . sqrt ( vec1 . reduce ( ( acc , val ) => acc + val * val , 0 ) ) ;
const magnitude2 = Math . sqrt ( vec2 . reduce ( ( acc , val ) => acc + val * val , 0 ) ) ;
return dotProduct / ( magnitude1 * magnitude2 ) ;
}
// Example vectors
const vectorA = [ 1 , 2 , 3 ] ;
const vectorB = [ 4 , 5 , 6 ] ;
const similarity = calculateCosineSimilarity ( vectorA , vectorB ) ;
console . log ( `Cosine Similarity: ${ similarity . toFixed ( 2 ) } ` ) ; // Output: Cosine Similarity: 0.9746 เมื่อเห็นภาพเวกเตอร์ฝังตัวโดยเฉพาะอย่างยิ่งเมื่อมีรายการจำนวนมากกราฟสามารถกลายเป็นกลุ่มและตีความได้ยากเกินไป เพื่อแก้ไขปัญหานี้จะใช้ฟังก์ชั่นการปรับให้เรียบ
ฟังก์ชั่นการปรับให้เรียบช่วยในการลดเสียงรบกวนในข้อมูลโดยเฉลี่ยค่ามากกว่าขนาดหน้าต่างที่ระบุ สิ่งนี้ทำให้กราฟอ่านได้มากขึ้นและช่วยให้การสร้างภาพแนวโน้มโดยรวมของข้อมูลได้ดีขึ้น
นี่คือวิธีการใช้ฟังก์ชันการปรับให้เรียบในแอปพลิเคชัน:
const smoothData = ( data , windowSize ) => {
const smoothed = [ ] ;
for ( let i = 0 ; i < data . length ; i ++ ) {
const start = Math . max ( 0 , i - Math . floor ( windowSize / 2 ) ) ;
const end = Math . min ( data . length , i + Math . floor ( windowSize / 2 ) + 1 ) ;
const window = data . slice ( start , end ) ;
const average = window . reduce ( ( sum , val ) => sum + val , 0 ) / window . length ;
smoothed . push ( average ) ;
}
return smoothed ;
} ;การปรับให้เรียบสามารถสลับหรือปิดโดยใช้ช่องทำเครื่องหมายใน UI ซึ่งให้ความยืดหยุ่นแก่ผู้ใช้
โมเดล Ollama และ Nomic-Text-Embed
http://localhost:11434nomic-embed-text ในเทอร์มินัลโดยการโทร ollama pull nomic-embed-text
Ollama ช่วยในการใช้แบบจำลองภาษาในพื้นที่ขนาดใหญ่และเล็ก Nomic-embed-embed isa โมเดลการฝังแบบเปิดที่มีประสิทธิภาพสูงพร้อมหน้าต่างบริบทโทเค็นขนาดใหญ่
ติดตั้ง node.js และ npm
โคลนที่เก็บ:
git clone www.github.com/rajatasusual/realtime-vector-embeddings.git
cd realtime-vector-embeddingsติดตั้งการพึ่งพา:
npm installเรียกใช้เซิร์ฟเวอร์:
npm run cli เริ่มพิมพ์ในเทอร์มินัลเพื่อป้อนข้อความและรับการฝังเวกเตอร์ ผลลัพธ์และพล็อตจะถูกบันทึกเป็น embedding_plot.png ในไดเรกทอรีปัจจุบัน
ไฟล์ env สามารถพบได้ในไดเรกทอรีรูทของโครงการด้วยการตั้งค่าเริ่มต้น
PORT=3000
EMBEDDINGS_MODEL=nomic-embed-text
EMBEDDINGS_BASE_URL=http://localhost:11434
SMOOTH=TRUE
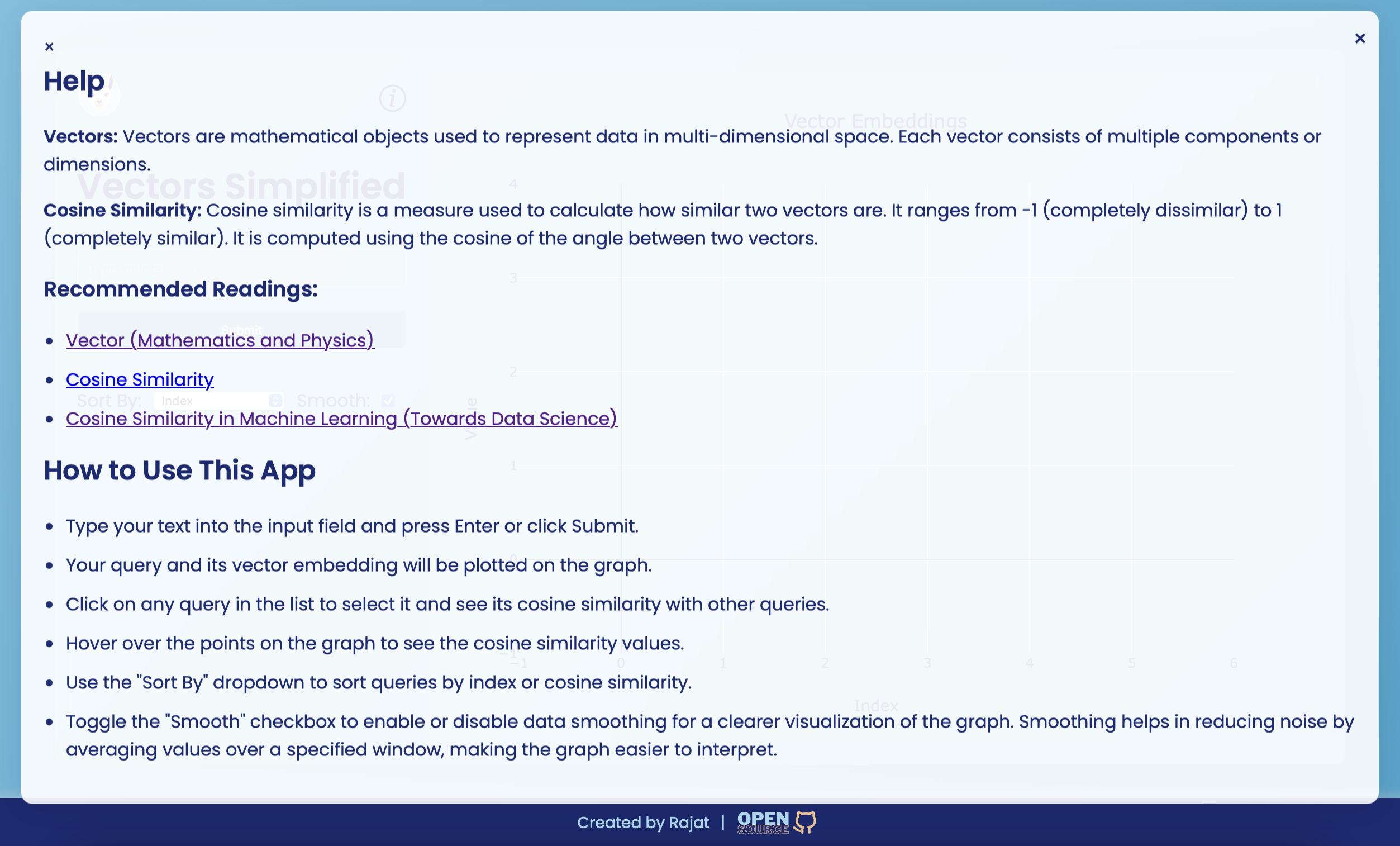
เริ่มต้นเว็บเซิร์ฟเวอร์ :
npm startสิ่งนี้จะเริ่มต้นเซิร์ฟเวอร์ด้วยพอร์ตเริ่มต้น 3000
Open index.html
ใช้ฟิลด์อินพุตเพื่อพิมพ์ข้อความและคลิก "ส่ง" เพื่อสร้างการฝังเวกเตอร์ ผลลัพธ์จะปรากฏบนกราฟและคุณสามารถโต้ตอบกับมันเพื่อดูความคล้ายคลึงกัน
ตัวเลือกการปรับให้เรียบ : ใช้ช่องทำเครื่องหมาย "เรียบ" เพื่อสลับการเปิดหรือปิดให้เรียบเพื่อให้เห็นภาพกราฟที่ดีขึ้น
โครงการนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต MIT ดูไฟล์ใบอนุญาตสำหรับรายละเอียดเพิ่มเติม


