realtime vector embeddings
1.0.0
 このプロジェクトは、多次元空間で同様の異なるテキストがどれほど重要であるかを理解するために作成されています。これは、テキスト分類、クラスタリング、推奨システムなどの自然言語処理(NLP)タスクの重要な概念です。
このプロジェクトは、多次元空間で同様の異なるテキストがどれほど重要であるかを理解するために作成されています。これは、テキスト分類、クラスタリング、推奨システムなどの自然言語処理(NLP)タスクの重要な概念です。
このプロジェクトはLlamappの一部です
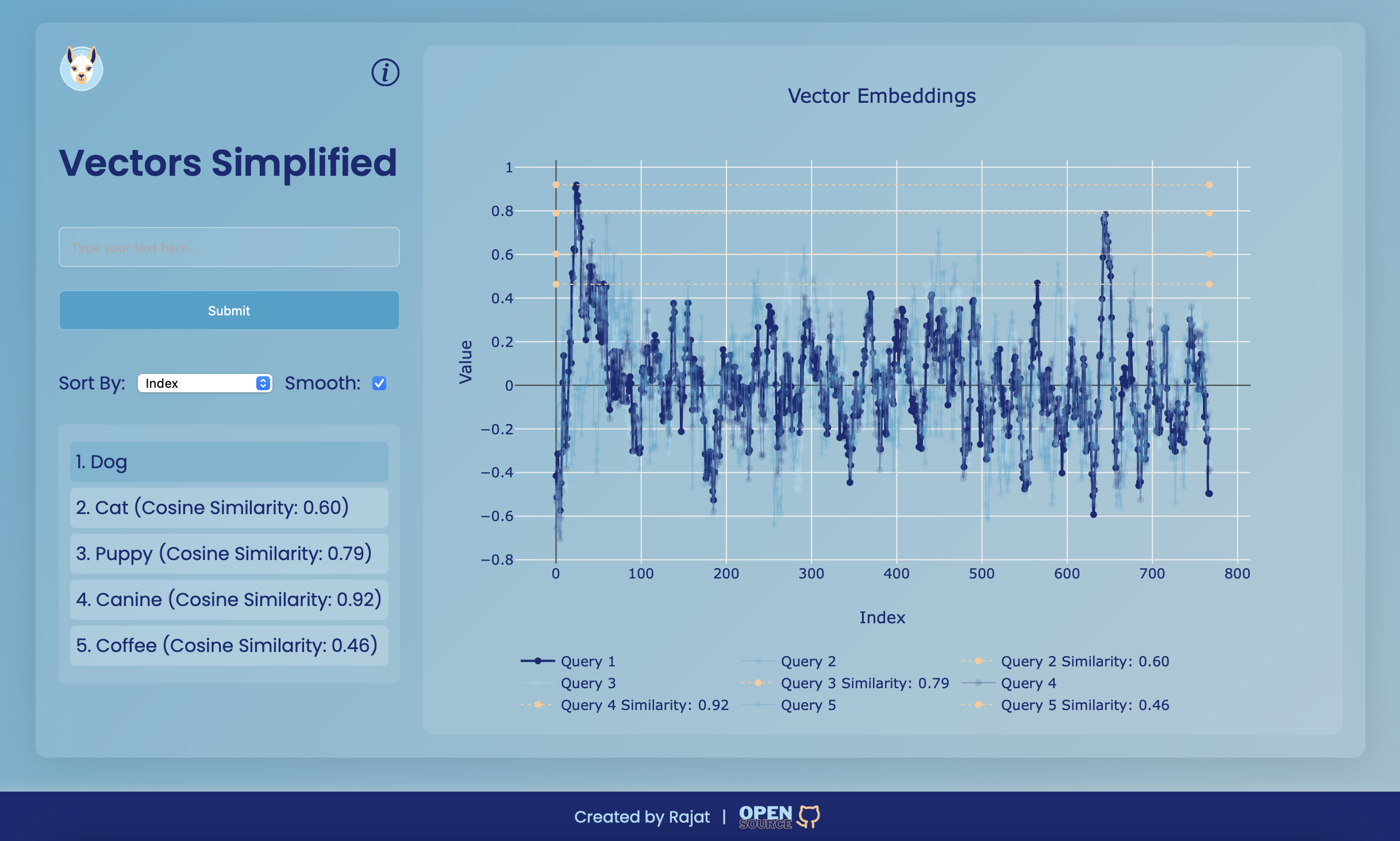
Vectors Simplifiedは、ベクトルの埋め込みを視覚化するように設計されたWebアプリケーションです。このプロジェクトは、入力テキストへのユーザーフレンドリーなインターフェイスを提供し、ベクトル埋め込みを生成し、インタラクティブプロットを使用して類似性を視覚化します。アプリケーションのコアは、ベクトル間のコサインの類似性の概念を示しており、多次元空間で類似の異なるテキストがどれほど類似しているかを理解しやすくします。
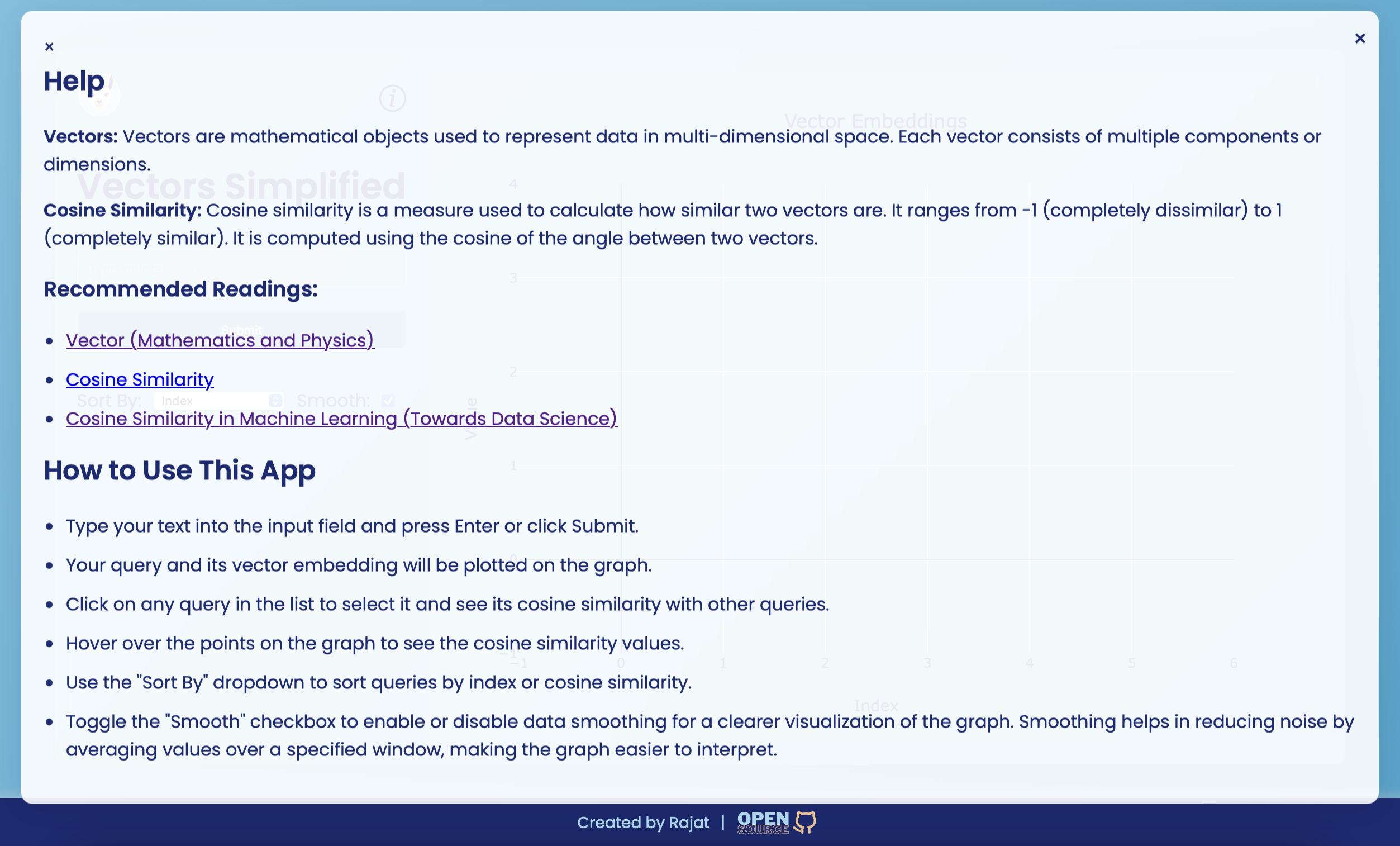
ベクトル埋め込みは、高次元空間で意味的な意味をキャプチャするテキストの数値表現です。これらは、テキスト分類、クラスタリング、推奨システムなどのさまざまな自然言語処理(NLP)タスクで使用されます。各ベクトルは、テキストの機能に関する情報をエンコードする複数のコンポーネントで構成されています。
コサインの類似性は、それらの間の角度のコサインに基づいて、2つのベクトルがどれほど類似しているかを測定するために使用されるメトリックです。 -1(完全に異なって)から1(完全に類似)の範囲です。テキスト分析で広く使用されており、ベクトル表現に基づいた2つのテキストの2つのテキストがどれほど類似しているかを判断します。
コサインの類似性が基本的なベクトルでどのように機能するかの簡単な例を次に示します。
function calculateCosineSimilarity ( vec1 , vec2 ) {
const dotProduct = vec1 . reduce ( ( acc , val , idx ) => acc + val * vec2 [ idx ] , 0 ) ;
const magnitude1 = Math . sqrt ( vec1 . reduce ( ( acc , val ) => acc + val * val , 0 ) ) ;
const magnitude2 = Math . sqrt ( vec2 . reduce ( ( acc , val ) => acc + val * val , 0 ) ) ;
return dotProduct / ( magnitude1 * magnitude2 ) ;
}
// Example vectors
const vectorA = [ 1 , 2 , 3 ] ;
const vectorB = [ 4 , 5 , 6 ] ;
const similarity = calculateCosineSimilarity ( vectorA , vectorB ) ;
console . log ( `Cosine Similarity: ${ similarity . toFixed ( 2 ) } ` ) ; // Output: Cosine Similarity: 0.9746 ベクトルの埋め込みを視覚化すると、特に多数のアイテムが含まれている場合、グラフはあまりにもクラスター化され、解釈が困難になる可能性があります。これに対処するために、平滑化関数が使用されます。
スムージング関数は、指定されたウィンドウサイズで値を平均化することにより、データのノイズを減らすのに役立ちます。これにより、グラフがより読みやすくなり、データの全体的な傾向をより視覚化できるようになります。
アプリケーションでスムージング機能がどのように実装されるかは次のとおりです。
const smoothData = ( data , windowSize ) => {
const smoothed = [ ] ;
for ( let i = 0 ; i < data . length ; i ++ ) {
const start = Math . max ( 0 , i - Math . floor ( windowSize / 2 ) ) ;
const end = Math . min ( data . length , i + Math . floor ( windowSize / 2 ) + 1 ) ;
const window = data . slice ( start , end ) ;
const average = window . reduce ( ( sum , val ) => sum + val , 0 ) / window . length ;
smoothed . push ( average ) ;
}
return smoothed ;
} ;UIのチェックボックスを使用して、スムージングをオンまたはオフに切り替えることができ、ユーザーに柔軟性を提供します。
OllamaおよびNomic-Text-埋め込みモデル
http://localhost:11434で実行され、アクセス可能であることを確認してください。nomic-embed-textコマンドを実行します ollama pull nomic-embed-text
Ollamaは、ローカル、大小の言語モデルを実行するのに役立ちます。大きなトークンコンテキストウィンドウを備えたNOMIC-membed-Text ISA高性能オープン埋め込みモデル。
node.jsとnpmをインストールします
リポジトリをクローンします:
git clone www.github.com/rajatasusual/realtime-vector-embeddings.git
cd realtime-vector-embeddings依存関係をインストールします:
npm installサーバーを実行します:
npm run cliテキストを入力し、ベクトル埋め込みを取得するために端子の入力を開始します。結果とプロットは、現在のディレクトリにembedding_plot.pngとして保存されます。
envファイルは、デフォルトの設定を備えたプロジェクトルートディレクトリにあります
PORT=3000
EMBEDDINGS_MODEL=nomic-embed-text
EMBEDDINGS_BASE_URL=http://localhost:11434
SMOOTH=TRUE
Webサーバーを開始します。
npm startこれにより、デフォルトのポート3000でサーバーが開始されます。
index.htmlをオープンします。
入力フィールドを使用してテキストを入力し、[送信]をクリックしてベクトル埋め込みを生成します。結果はグラフに表示され、類似点を表示するために対話できます。
スムージングオプション:「滑らかな」チェックボックスを使用して、グラフのより良い視覚化のためにスムージングをオンまたはオフに切り替えます。
このプロジェクトは、MITライセンスの下でライセンスされています。詳細については、ライセンスファイルを参照してください。


