realtime vector embeddings
1.0.0
 이 프로젝트는 다차원 공간에 다른 텍스트 조각이 얼마나 유사한 지 이해하기 위해 만들어졌습니다. 이것은 텍스트 분류, 클러스터링 및 권장 시스템과 같은 자연어 처리 (NLP) 작업의 중요한 개념입니다.
이 프로젝트는 다차원 공간에 다른 텍스트 조각이 얼마나 유사한 지 이해하기 위해 만들어졌습니다. 이것은 텍스트 분류, 클러스터링 및 권장 시스템과 같은 자연어 처리 (NLP) 작업의 중요한 개념입니다.
이 프로젝트는 Llamapp의 일부입니다
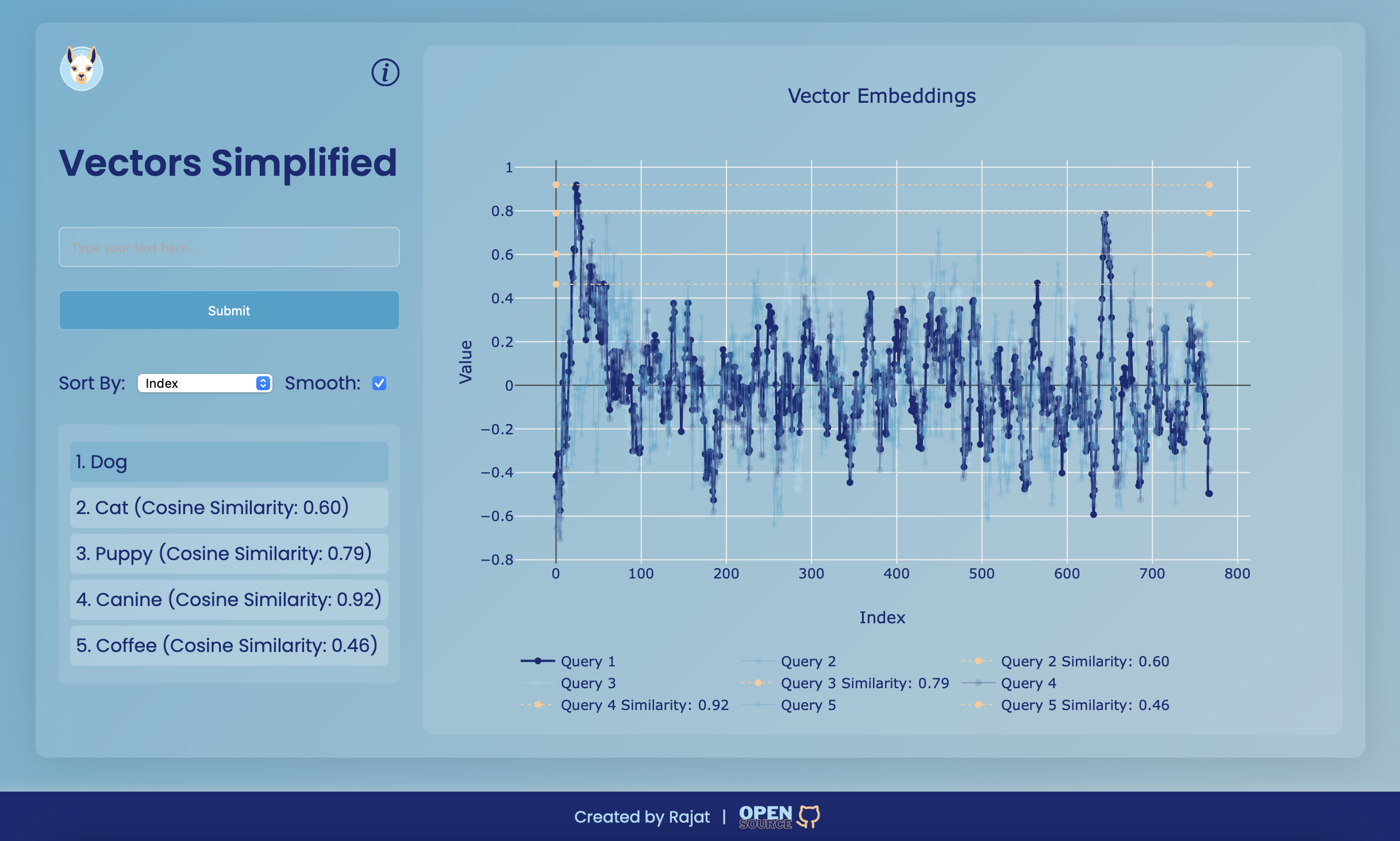
단순화 된 벡터는 벡터 임베딩을 시각화하도록 설계된 웹 응용 프로그램입니다. 이 프로젝트는 사용자 친화적 인 인터페이스를 제공하여 텍스트를 입력하고 벡터 임베딩을 생성하며 대화식 플롯을 사용하여 유사성을 시각화합니다. 응용 프로그램의 핵심은 벡터 간의 코사인 유사성의 개념을 보여 주므로 다차원 공간에 다른 텍스트가 얼마나 유사한 지 이해하는 것이 더 쉽습니다.
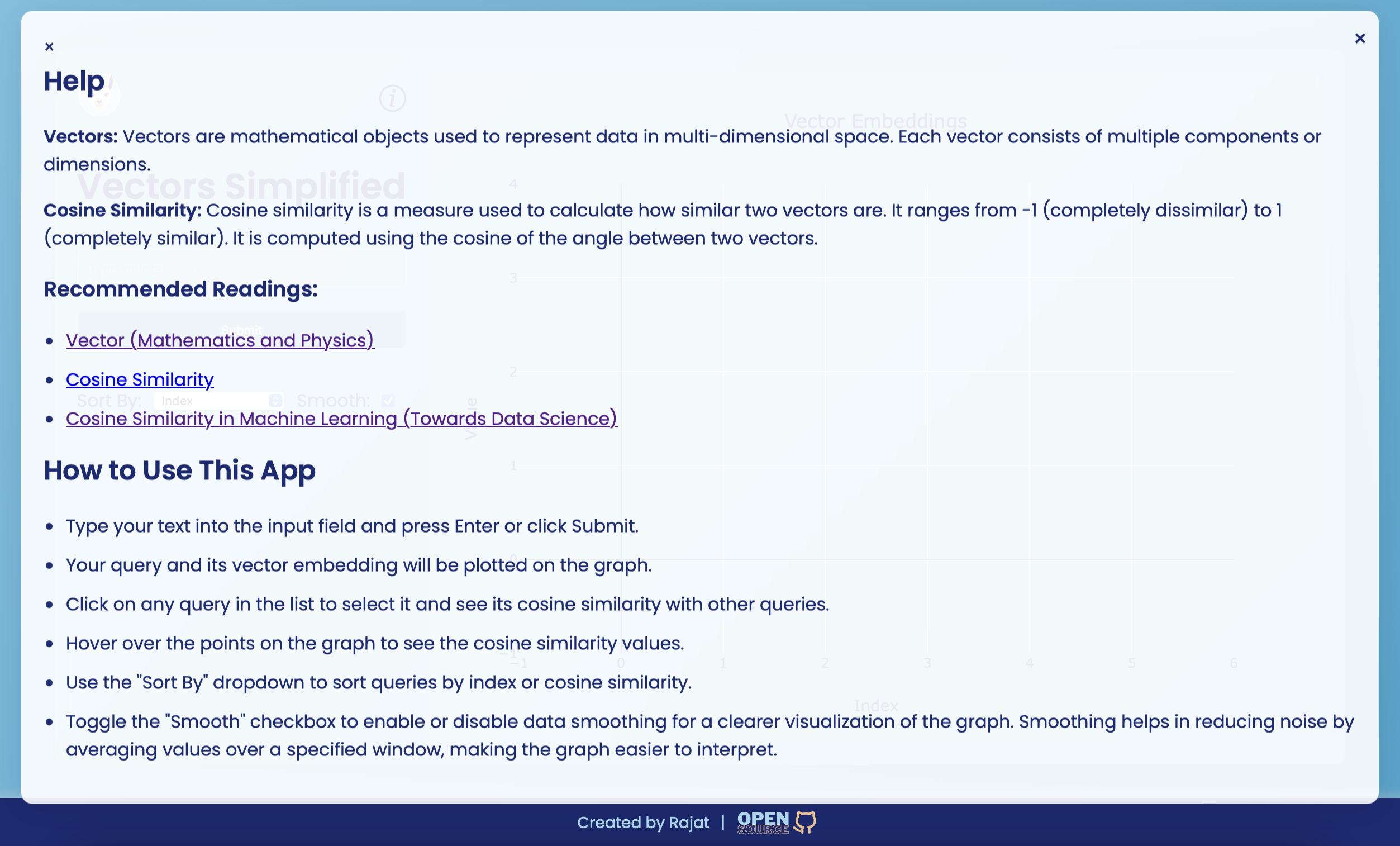
벡터 임베딩은 고차원 공간에서 의미 론적 의미를 포착하는 텍스트의 수치 표현입니다. 텍스트 분류, 클러스터링 및 권장 시스템과 같은 다양한 자연어 처리 (NLP) 작업에 사용됩니다. 각 벡터는 텍스트 기능에 대한 정보를 인코딩하는 여러 구성 요소로 구성됩니다.
코사인 유사성은 그들 사이의 각도의 코사인을 기반으로 두 벡터가 얼마나 유사한지를 측정하는 데 사용되는 메트릭입니다. -1 (완전히 다른 것)에서 1 (완전히 유사)까지 다양합니다. 텍스트 분석에 널리 사용되어 벡터 표현을 기반으로 비슷한 두 텍스트가 얼마나 유사한지를 결정합니다.
코사인 유사성이 기본 벡터와 어떻게 작동하는지에 대한 간단한 예는 다음과 같습니다.
function calculateCosineSimilarity ( vec1 , vec2 ) {
const dotProduct = vec1 . reduce ( ( acc , val , idx ) => acc + val * vec2 [ idx ] , 0 ) ;
const magnitude1 = Math . sqrt ( vec1 . reduce ( ( acc , val ) => acc + val * val , 0 ) ) ;
const magnitude2 = Math . sqrt ( vec2 . reduce ( ( acc , val ) => acc + val * val , 0 ) ) ;
return dotProduct / ( magnitude1 * magnitude2 ) ;
}
// Example vectors
const vectorA = [ 1 , 2 , 3 ] ;
const vectorB = [ 4 , 5 , 6 ] ;
const similarity = calculateCosineSimilarity ( vectorA , vectorB ) ;
console . log ( `Cosine Similarity: ${ similarity . toFixed ( 2 ) } ` ) ; // Output: Cosine Similarity: 0.9746 벡터 임베딩을 시각화 할 때 특히 많은 항목이 포함되어있을 때 그래프가 너무 클러스터되어 해석하기가 어려워 질 수 있습니다. 이를 해결하기 위해 스무딩 기능이 사용됩니다.
스무딩 기능은 지정된 창 크기에 대한 값을 평균하여 데이터의 노이즈를 줄이는 데 도움이됩니다. 이로 인해 그래프를 더 읽기 쉽고 데이터의 전반적인 트렌드를 더 잘 시각화 할 수 있습니다.
스무딩 기능이 응용 프로그램에서 구현되는 방법은 다음과 같습니다.
const smoothData = ( data , windowSize ) => {
const smoothed = [ ] ;
for ( let i = 0 ; i < data . length ; i ++ ) {
const start = Math . max ( 0 , i - Math . floor ( windowSize / 2 ) ) ;
const end = Math . min ( data . length , i + Math . floor ( windowSize / 2 ) + 1 ) ;
const window = data . slice ( start , end ) ;
const average = window . reduce ( ( sum , val ) => sum + val , 0 ) / window . length ;
smoothed . push ( average ) ;
}
return smoothed ;
} ;스무딩은 UI의 확인란을 사용하여 켜거나 끄는 것으로 사용자에게 유연성을 제공합니다.
Ollama 및 Nomic-Text-embed 모델
http://localhost:11434 에서 Ollama가 실행되고 액세스 할 수 있는지 확인하십시오.nomic-embed-text 명령을 실행하십시오 ollama pull nomic-embed-text
Ollama는 언어 모델을 현지에서 크고 작은 실행하는 데 도움이됩니다. Nomic-embed-Text ISA 대형 토큰 컨텍스트 창이있는 고성능 개방형 임베딩 모델.
Node.js 및 NPM을 설치하십시오
저장소 복제 :
git clone www.github.com/rajatasusual/realtime-vector-embeddings.git
cd realtime-vector-embeddings종속성 설치 :
npm install서버 실행 :
npm run cli 터미널에서 입력을 시작하여 텍스트를 입력하고 벡터 임베딩을 얻습니다. 결과와 플롯은 현재 디렉토리에서 embedding_plot.png 로 저장됩니다.
ENV 파일은 기본 설정이있는 Project Root 디렉토리에서 찾을 수 있습니다.
PORT=3000
EMBEDDINGS_MODEL=nomic-embed-text
EMBEDDINGS_BASE_URL=http://localhost:11434
SMOOTH=TRUE
웹 서버 시작 :
npm start이것은 기본 포트 3000으로 서버를 시작합니다.
Open index.html .
입력 필드를 사용하여 텍스트를 입력하고 "제출"을 클릭하여 벡터 임베딩을 생성하십시오. 결과는 그래프에 표시되며 유사성을 볼 수 있도록 이와 상호 작용할 수 있습니다.
스무딩 옵션 : "스무딩"확인란을 사용하여 스무딩을 켜거나 끄는 데 그래프를 더 잘 시각화하십시오.
이 프로젝트는 MIT 라이센스에 따라 라이센스가 부여됩니다. 자세한 내용은 라이센스 파일을 참조하십시오.


