fast_gicp
1.0.0
เราเปิดตัว Small_GICP ที่เร็วเป็นสองเท่าของ FAST_GICP และมีการพึ่งพาขั้นต่ำและอินเทอร์เฟซที่สะอาด
แพ็คเกจนี้เป็นชุดของอัลกอริทึมการลงทะเบียนคลาวด์ Fast Point ที่ใช้ GICP มันมี GICP แบบมัลติเธรดรวมถึงการใช้งานแบบมัลติเธรดและ GPU ของอัลกอริทึม GICP (VGICP) ของเรา อัลกอริทึมที่นำไปใช้ทั้งหมดมีส่วนต่อประสานการลงทะเบียน PCL เพื่อให้สามารถใช้เป็นการทดแทนในสถานที่สำหรับ GICP ใน PCL
เราได้ทดสอบแพ็คเกจนี้บน Ubuntu 18.04/20.04 และ Cuda 11.1
บน macOS เมื่อใช้ brew คุณอาจต้องตั้งค่า depenencies ของคุณเช่นนี้
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
ในการเปิดใช้งานการใช้งาน CUDA-powered ให้ตั้งค่าตัวเลือก BUILD_VGICP_CUDA cmake เป็น ON
cd ~ /catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ONgit clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8 cd fast_gicp
python3 setup.py install --user หมายเหตุ: หากคุณอยู่ในสภาพแวดล้อมที่เปิดใช้งาน Catkin และการติดตั้งใช้งานไม่ได้ให้แสดงความคิดเห็น find_package(catkin) ใน cmakelists.txt และเรียกใช้คำสั่งการติดตั้งด้านบนอีกครั้ง
import pygicp
target = # Nx3 numpy array
source = # Mx3 numpy array
# 1. function interface
matrix = pygicp . align_points ( target , source )
# optional arguments
# initial_guess : Initial guess of the relative pose (4x4 matrix)
# method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
# downsample_resolution : Downsampling resolution (used only if positive)
# k_correspondences : Number of points used for covariance estimation
# max_correspondence_distance : Maximum distance for corresponding point search
# voxel_resolution : Resolution of voxel-based algorithms
# neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
# neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
# num_threads : Number of threads
# 2. class interface
# you may want to downsample the input clouds before registration
target = pygicp . downsample ( target , 0.25 )
source = pygicp . downsample ( source , 0.25 )
# pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp . FastGICP ()
gicp . set_input_target ( target )
gicp . set_input_source ( source )
matrix = gicp . align ()
# optional
gicp . set_num_threads ( 4 )
gicp . set_max_correspondence_distance ( 1.0 )
gicp . get_final_transformation ()
gicp . get_final_hessian ()CPU: CORE I9-9900K GPU: GeForce RTX2080TI
roscd fast_gicp/data
rosrun fast_gicp gicp_align 251370668.pcd 251371071.pcd target:17249[pts] source:17518[pts]
--- pcl_gicp ---
single:127.508[msec] 100times:12549.4[msec] fitness_score:0.204892
--- pcl_ndt ---
single:53.5904[msec] 100times:5467.16[msec] fitness_score:0.229616
--- fgicp_st ---
single:111.324[msec] 100times:10662.7[msec] 100times_reuse:6794.59[msec] fitness_score:0.204379
--- fgicp_mt ---
single:20.1602[msec] 100times:1585[msec] 100times_reuse:1017.74[msec] fitness_score:0.204412
--- vgicp_st ---
single:112.001[msec] 100times:7959.9[msec] 100times_reuse:4408.22[msec] fitness_score:0.204067
--- vgicp_mt ---
single:18.1106[msec] 100times:1381[msec] 100times_reuse:806.53[msec] fitness_score:0.204067
--- vgicp_cuda (parallel_kdtree) ---
single:15.9587[msec] 100times:1451.85[msec] 100times_reuse:695.48[msec] fitness_score:0.204061
--- vgicp_cuda (gpu_bruteforce) ---
single:53.9113[msec] 100times:3463.5[msec] 100times_reuse:1703.41[msec] fitness_score:0.204049
--- vgicp_cuda (gpu_rbf_kernel) ---
single:5.91508[msec] 100times:590.725[msec] 100times_reuse:226.787[msec] fitness_score:0.20557
ดู src/allign.cpp สำหรับการใช้อย่างละเอียด
# Perform frame-by-frame registration
rosrun fast_gicp gicp_kitti /your/kitti/path/sequences/00/velodyne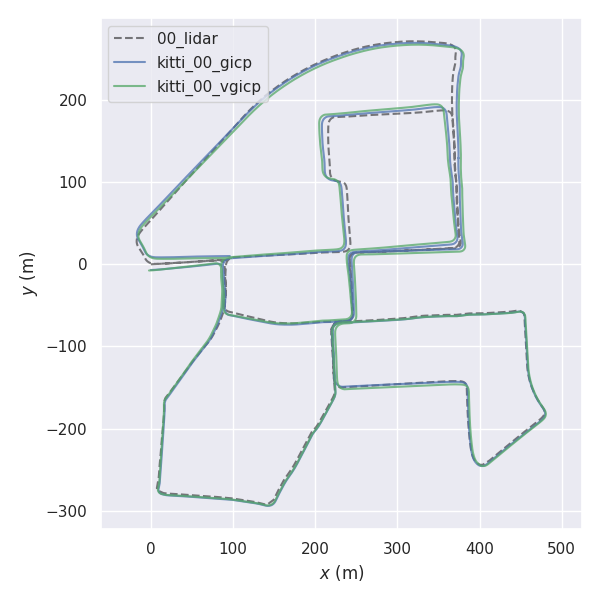
cd fast_gicp/src
python3 kitti.py /your/kitti/path/sequences/00/velodyneในบางสภาพแวดล้อมการตั้งค่าเธรดจำนวนน้อยกว่าจำนวนเธรดสูงสุด (ค่าเริ่มต้น) อาจส่งผลให้การประมวลผลเร็วขึ้น (ดู #145 (ความคิดเห็น))
kenji koide, [email protected]
ศูนย์วิจัยการเคลื่อนย้ายมนุษย์เป็นศูนย์กลางสถาบันวิทยาศาสตร์และเทคโนโลยีอุตสาหกรรมขั้นสูงแห่งชาติญี่ปุ่น [URL]


