fast_gicp
1.0.0
Lanzamos Small_Gicp que es dos veces más rápido que Fast_Gicp y con dependencias mínimas e interfaces limpias.
Este paquete es una colección de algoritmos de registro de nubes de puntos rápidos basados en GICP. Consta un GICP multiproceso, así como implementaciones de múltiples subprocesos y GPU de nuestro algoritmo GICP voxelizado (VGICP). Todos los algoritmos implementados tienen la interfaz de registro de PCL para que puedan usarse como un reemplazo injunto para GICP en PCL.
Hemos probado este paquete en Ubuntu 18.04/20.04 y CUDA 11.1.
En macOS Al usar brew , es posible que deba configurar sus depenencias como esta
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
Para habilitar las implementaciones con cDUA, establezca la opción BUILD_VGICP_CUDA CMake en ON .
cd ~ /catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ONgit clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8 cd fast_gicp
python3 setup.py install --user NOTA: Si está en un entorno habilitado para Catkin y la instalación no funciona bien, comente find_package(catkin) en cmakelists.txt y ejecute el comando de instalación anterior nuevamente.
import pygicp
target = # Nx3 numpy array
source = # Mx3 numpy array
# 1. function interface
matrix = pygicp . align_points ( target , source )
# optional arguments
# initial_guess : Initial guess of the relative pose (4x4 matrix)
# method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
# downsample_resolution : Downsampling resolution (used only if positive)
# k_correspondences : Number of points used for covariance estimation
# max_correspondence_distance : Maximum distance for corresponding point search
# voxel_resolution : Resolution of voxel-based algorithms
# neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
# neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
# num_threads : Number of threads
# 2. class interface
# you may want to downsample the input clouds before registration
target = pygicp . downsample ( target , 0.25 )
source = pygicp . downsample ( source , 0.25 )
# pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp . FastGICP ()
gicp . set_input_target ( target )
gicp . set_input_source ( source )
matrix = gicp . align ()
# optional
gicp . set_num_threads ( 4 )
gicp . set_max_correspondence_distance ( 1.0 )
gicp . get_final_transformation ()
gicp . get_final_hessian ()CPU: Core i9-9900K GPU: GeForce RTX2080TI
roscd fast_gicp/data
rosrun fast_gicp gicp_align 251370668.pcd 251371071.pcd target:17249[pts] source:17518[pts]
--- pcl_gicp ---
single:127.508[msec] 100times:12549.4[msec] fitness_score:0.204892
--- pcl_ndt ---
single:53.5904[msec] 100times:5467.16[msec] fitness_score:0.229616
--- fgicp_st ---
single:111.324[msec] 100times:10662.7[msec] 100times_reuse:6794.59[msec] fitness_score:0.204379
--- fgicp_mt ---
single:20.1602[msec] 100times:1585[msec] 100times_reuse:1017.74[msec] fitness_score:0.204412
--- vgicp_st ---
single:112.001[msec] 100times:7959.9[msec] 100times_reuse:4408.22[msec] fitness_score:0.204067
--- vgicp_mt ---
single:18.1106[msec] 100times:1381[msec] 100times_reuse:806.53[msec] fitness_score:0.204067
--- vgicp_cuda (parallel_kdtree) ---
single:15.9587[msec] 100times:1451.85[msec] 100times_reuse:695.48[msec] fitness_score:0.204061
--- vgicp_cuda (gpu_bruteforce) ---
single:53.9113[msec] 100times:3463.5[msec] 100times_reuse:1703.41[msec] fitness_score:0.204049
--- vgicp_cuda (gpu_rbf_kernel) ---
single:5.91508[msec] 100times:590.725[msec] 100times_reuse:226.787[msec] fitness_score:0.20557
Consulte SRC/Align.cpp para el uso detallado.
# Perform frame-by-frame registration
rosrun fast_gicp gicp_kitti /your/kitti/path/sequences/00/velodyne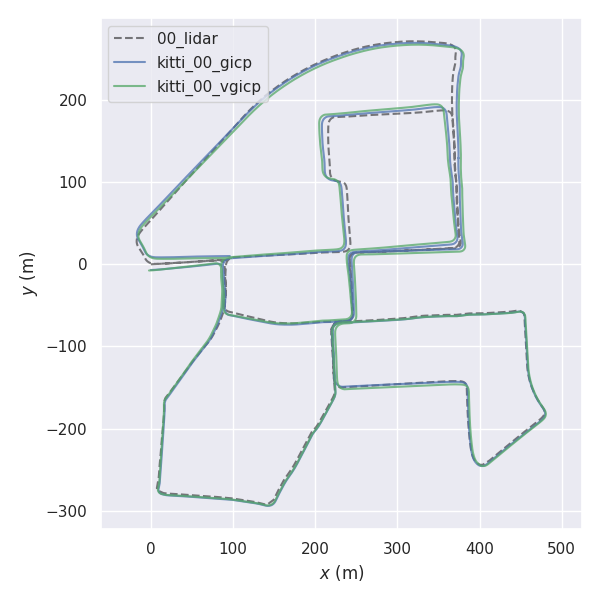
cd fast_gicp/src
python3 kitti.py /your/kitti/path/sequences/00/velodyneEn algunos entornos, establecer un número menos de subprocesos en lugar del número máximo (predeterminado) de subprocesos puede dar como resultado un procesamiento más rápido (ver #145 (comentario)).
Kenji Koide, [email protected]
Centro de investigación de movilidad centrada en humanos, Instituto Nacional de Ciencia y Tecnología Industrial Avanzada, Japón [URL]


