fast_gicp
1.0.0
우리는 FAST_GICP의 두 배나 빠른 Small_GICP와 최소 의존성과 깨끗한 인터페이스를 출시했습니다.
이 패키지는 GICP 기반 Fast Point Cloud 등록 알고리즘 모음입니다. VGICP (Voxelized GICP) 알고리즘의 멀티 스레드 및 GPU 구현뿐만 아니라 멀티 스레드 GICP를 구성합니다. 구현 된 모든 알고리즘에는 PCL 등록 인터페이스가있어 PCL에서 GICP를 대체 할 수 있습니다.
우리는 Ubuntu 18.04/20.04 및 Cuda 11.1 에서이 패키지를 테스트했습니다.
MacOS에서 brew 사용할 때는 이와 같은 Depenence를 설정해야 할 수도 있습니다.
cmake .. "-DCMAKE_PREFIX_PATH=$(brew --prefix libomp)[;other-custom-prefixes]" -DQt5_DIR=$(brew --prefix qt@5)lib/cmake/Qt5
CUDA 구동 구현을 활성화하려면 BUILD_VGICP_CUDA CMAKE 옵션을 ON 하십시오.
cd ~ /catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ONgit clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8 cd fast_gicp
python3 setup.py install --user 참고 : Catkin 지원 환경에 있고 설치가 잘 작동하지 않으면 CMakelists.txt에서 find_package(catkin) 주석하고 위의 설치 명령을 다시 실행하십시오.
import pygicp
target = # Nx3 numpy array
source = # Mx3 numpy array
# 1. function interface
matrix = pygicp . align_points ( target , source )
# optional arguments
# initial_guess : Initial guess of the relative pose (4x4 matrix)
# method : GICP, VGICP, VGICP_CUDA, or NDT_CUDA
# downsample_resolution : Downsampling resolution (used only if positive)
# k_correspondences : Number of points used for covariance estimation
# max_correspondence_distance : Maximum distance for corresponding point search
# voxel_resolution : Resolution of voxel-based algorithms
# neighbor_search_method : DIRECT1, DIRECT7, DIRECT27, or DIRECT_RADIUS
# neighbor_search_radius : Neighbor voxel search radius (for GPU-based methods)
# num_threads : Number of threads
# 2. class interface
# you may want to downsample the input clouds before registration
target = pygicp . downsample ( target , 0.25 )
source = pygicp . downsample ( source , 0.25 )
# pygicp.FastGICP has more or less the same interfaces as the C++ version
gicp = pygicp . FastGICP ()
gicp . set_input_target ( target )
gicp . set_input_source ( source )
matrix = gicp . align ()
# optional
gicp . set_num_threads ( 4 )
gicp . set_max_correspondence_distance ( 1.0 )
gicp . get_final_transformation ()
gicp . get_final_hessian ()CPU : 코어 i9-9900K GPU : Geforce RTX2080TI
roscd fast_gicp/data
rosrun fast_gicp gicp_align 251370668.pcd 251371071.pcd target:17249[pts] source:17518[pts]
--- pcl_gicp ---
single:127.508[msec] 100times:12549.4[msec] fitness_score:0.204892
--- pcl_ndt ---
single:53.5904[msec] 100times:5467.16[msec] fitness_score:0.229616
--- fgicp_st ---
single:111.324[msec] 100times:10662.7[msec] 100times_reuse:6794.59[msec] fitness_score:0.204379
--- fgicp_mt ---
single:20.1602[msec] 100times:1585[msec] 100times_reuse:1017.74[msec] fitness_score:0.204412
--- vgicp_st ---
single:112.001[msec] 100times:7959.9[msec] 100times_reuse:4408.22[msec] fitness_score:0.204067
--- vgicp_mt ---
single:18.1106[msec] 100times:1381[msec] 100times_reuse:806.53[msec] fitness_score:0.204067
--- vgicp_cuda (parallel_kdtree) ---
single:15.9587[msec] 100times:1451.85[msec] 100times_reuse:695.48[msec] fitness_score:0.204061
--- vgicp_cuda (gpu_bruteforce) ---
single:53.9113[msec] 100times:3463.5[msec] 100times_reuse:1703.41[msec] fitness_score:0.204049
--- vgicp_cuda (gpu_rbf_kernel) ---
single:5.91508[msec] 100times:590.725[msec] 100times_reuse:226.787[msec] fitness_score:0.20557
자세한 사용량은 SRC/Align.cpp를 참조하십시오.
# Perform frame-by-frame registration
rosrun fast_gicp gicp_kitti /your/kitti/path/sequences/00/velodyne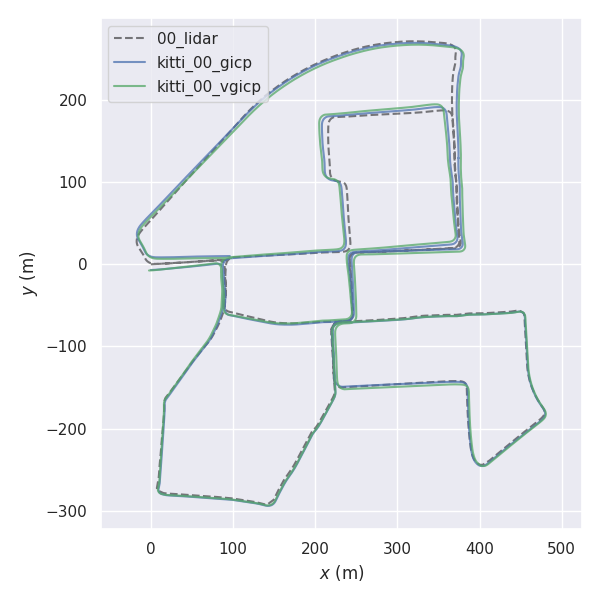
cd fast_gicp/src
python3 kitti.py /your/kitti/path/sequences/00/velodyne일부 환경에서는 (기본값) 최대 스레드 수가 아닌 더 많은 수의 스레드를 설정하면 처리가 더 빨라질 수 있습니다 ( #145 (댓글) 참조).
Kenji Koide, [email protected]
일본 선진 산업 과학 기술 연구소, 인간 중심 이동성 연구 센터 [URL]


