rlcard
RLCard 1.0.7
中文文档
RLCARD เป็นชุดเครื่องมือสำหรับการเรียนรู้การเสริมแรง (RL) ในเกมไพ่ รองรับสภาพแวดล้อมการ์ดหลายเครื่องด้วยอินเทอร์เฟซที่ใช้งานง่ายสำหรับการใช้อัลกอริทึมการเสริมแรงและการค้นหาที่หลากหลาย เป้าหมายของ RLCARD คือการเชื่อมโยงการเรียนรู้การเสริมแรงและเกมข้อมูลที่ไม่สมบูรณ์ RLCARD ได้รับการพัฒนาโดย Data Lab ที่ Rice และ Texas A&M University และผู้สนับสนุนชุมชน
ชุมชน:
ข่าว:
เกมต่อไปนี้ส่วนใหญ่ได้รับการพัฒนาและดูแลโดยผู้สนับสนุนชุมชน ขอบคุณ!
ขอบคุณผู้มีส่วนร่วมทุกคน!




























หากคุณพบว่า repo นี้มีประโยชน์คุณอาจอ้างถึง:
Zha, Daochen, et al. "RLCARD: แพลตฟอร์มสำหรับการเรียนรู้การเสริมแรงในเกมไพ่" ijcai 2020.
@inproceedings { zha2020rlcard ,
title = { RLCard: A Platform for Reinforcement Learning in Card Games } ,
author = { Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia } ,
booktitle = { IJCAI } ,
year = { 2020 }
} ตรวจสอบให้แน่ใจว่าคุณติดตั้ง Python 3.6+ และ PIP เราขอแนะนำให้ติดตั้ง rlcard เวอร์ชันที่เสถียรด้วย pip :
pip3 install rlcard
การติดตั้งเริ่มต้นจะรวมถึงสภาพแวดล้อมของการ์ดเท่านั้น หากต้องการใช้การใช้งาน Pytorch ของอัลกอริทึมการฝึกอบรมให้เรียกใช้
pip3 install rlcard[torch]
หากคุณอยู่ในประเทศจีนและคำสั่งข้างต้นช้าเกินไปคุณสามารถใช้กระจกที่ได้รับจากมหาวิทยาลัย Tsinghua:
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
หรือคุณสามารถโคลนเวอร์ชันล่าสุดด้วย (ถ้าคุณอยู่ในประเทศจีนและ GitHub ช้าคุณสามารถใช้กระจกใน Gitee):
git clone https://github.com/datamllab/rlcard.git
หรือเฉพาะสาขาหนึ่งสาขาที่จะทำให้เร็วขึ้น:
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
จากนั้นติดตั้งด้วย
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
นอกจากนี้เรายังมีวิธีการติดตั้ง conda :
conda install -c toubun rlcard
การติดตั้ง Conda มีสภาพแวดล้อมการ์ดเท่านั้นคุณต้องติดตั้ง pytorch ด้วยตนเองตามความต้องการของคุณ
ตัวอย่างสั้น ๆ คือด้านล่าง
import rlcard
from rlcard . agents import RandomAgent
env = rlcard . make ( 'blackjack' )
env . set_agents ([ RandomAgent ( num_actions = env . num_actions )])
print ( env . num_actions ) # 2
print ( env . num_players ) # 1
print ( env . state_shape ) # [[2]]
print ( env . action_shape ) # [None]
trajectories , payoffs = env . run ()RLCARD สามารถเชื่อมต่อได้อย่างยืดหยุ่นกับอัลกอริทึมต่างๆ ดูตัวอย่างต่อไปนี้:
รัน examples/human/leduc_holdem_human.py เพื่อเล่นกับโมเดล LEDUCED ที่ผ่านการฝึกอบรมมาก่อน Leduc Hold'em เป็นรุ่นที่ง่ายของ Texas Hold'em สามารถพบกฎได้ที่นี่
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
นอกจากนี้เรายังมี GUI สำหรับการดีบักง่ายๆ โปรดตรวจสอบที่นี่ การสาธิตบางอย่าง:
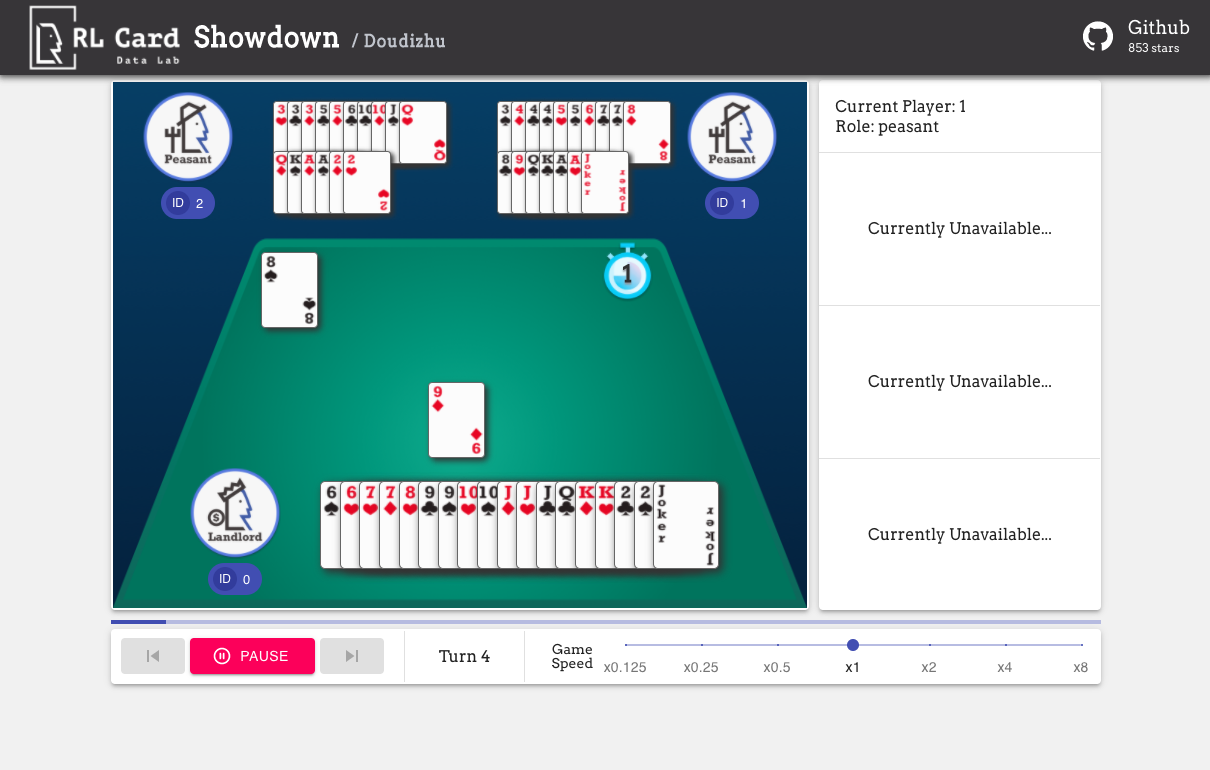
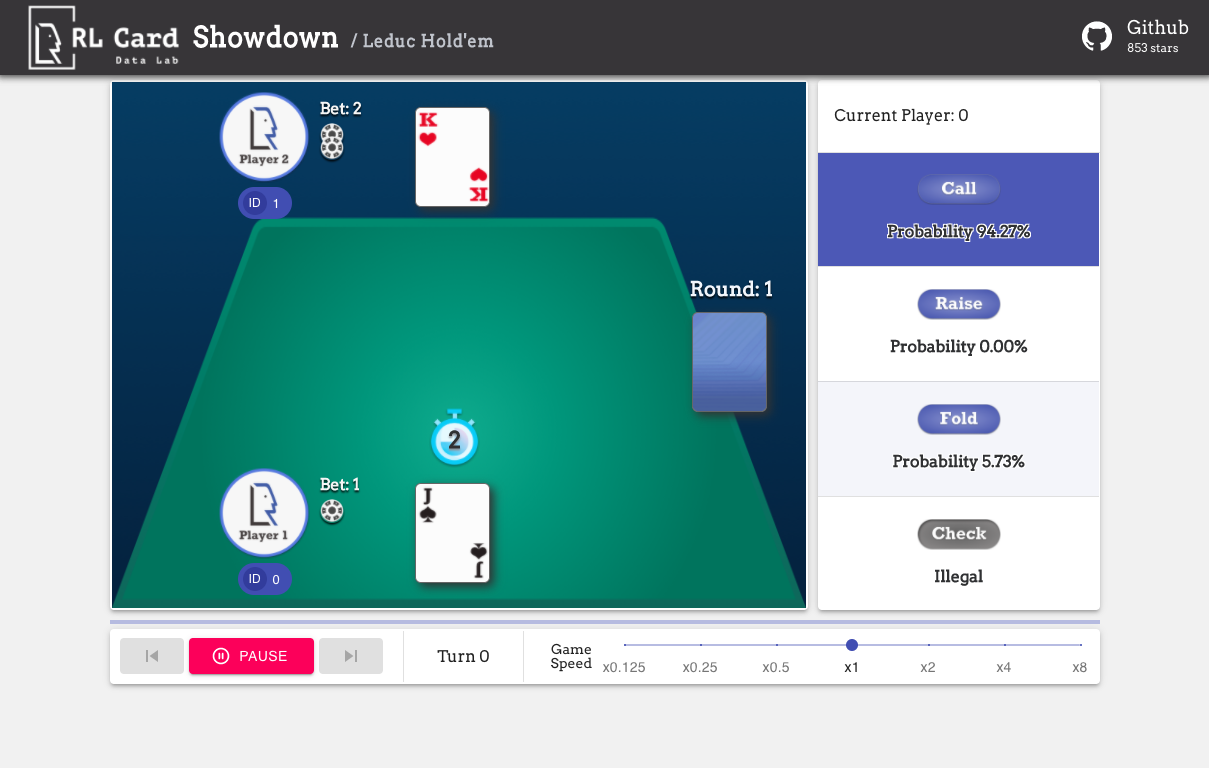
เราให้การประเมินความซับซ้อนสำหรับเกมในหลาย ๆ ด้าน หมายเลข Infoset: จำนวนชุดข้อมูล; ขนาดอินโฟส: จำนวนรัฐเฉลี่ยในชุดข้อมูลเดียว; ขนาดการกระทำ: ขนาดของพื้นที่การกระทำ ชื่อ: ชื่อที่ควรส่งผ่านไปยัง rlcard.make เพื่อสร้างสภาพแวดล้อมของเกม นอกจากนี้เรายังให้ลิงก์ไปยังเอกสารและตัวอย่างแบบสุ่ม
| เกม | หมายเลข Infoset | ขนาดอินฟอส | ขนาดการกระทำ | ชื่อ | การใช้งาน |
|---|---|---|---|---|---|
| แบล็คแจ็ค (วิกิ, baike) | 10^3 | 10^1 | 10^0 | กระบอง | เอกสารตัวอย่าง |
| leduc hold'em (กระดาษ) | 10^2 | 10^2 | 10^0 | Leduc-holdem | เอกสารตัวอย่าง |
| จำกัด Texas Hold'em (Wiki, Baike) | 10^14 | 10^3 | 10^0 | ขีด จำกัด | เอกสารตัวอย่าง |
| Dou Dizhu (Wiki, Baike) | 10^53 ~ 10^83 | 10^23 | 10^4 | Doudizhu | เอกสารตัวอย่าง |
| Mahjong (Wiki, Baike) | 10^121 | 10^48 | 10^2 | มงกุฎ | เอกสารตัวอย่าง |
| No-Limit Texas Hold'em (Wiki, Baike) | 10^162 | 10^3 | 10^4 | ไม่มีข้อ จำกัด | เอกสารตัวอย่าง |
| UNO (Wiki, Baike) | 10^163 | 10^10 | 10^1 | uno | เอกสารตัวอย่าง |
| Gin Rummy (Wiki, Baike) | 10^52 | - | - | จินรัมมี่ | เอกสารตัวอย่าง |
| Bridge (Wiki, Baike) | - | - | สะพาน | เอกสารตัวอย่าง |
| อัลกอริทึม | ตัวอย่าง | อ้างอิง |
|---|---|---|
| Deep Monte-Carlo (DMC) | ตัวอย่าง/run_dmc.py | [กระดาษ] |
| Q-Learning ลึก (DQN) | ตัวอย่าง/run_rl.py | [กระดาษ] |
| การเล่นด้วยตนเองของระบบประสาท (NFSP) | ตัวอย่าง/run_rl.py | [กระดาษ] |
| การลดความเสียใจในการต่อต้าน (CFR) | ตัวอย่าง/run_cfr.py | [กระดาษ] |
เราให้บริการสวนสัตว์แบบจำลองเพื่อใช้เป็นเส้นเขตแดน
| แบบอย่าง | คำอธิบาย |
|---|---|
| LEDUC-HOLDEM-CFR | รุ่น CFR ที่ผ่านการฝึกอบรมมาก่อน (การสุ่มตัวอย่างโอกาส) บน leduc hold'em |
| LEDUC-HOLDEM-RULE-V1 | แบบจำลองตามกฎสำหรับ leduc hold'em, v1 |
| LEDUC-HOLDEM-RULE-V2 | แบบจำลองตามกฎสำหรับ Leduc Hold'em, v2 |
| uno-rule-v1 | แบบจำลองตามกฎสำหรับ UNO, v1 |
| Limit Holdem-Rule-V1 | แบบจำลองตามกฎสำหรับ Limit Texas Hold'em, v1 |
| Doudizhu-Rule-V1 | แบบจำลองตามกฎสำหรับ Dou Dizhu, v1 |
| Gin-Rummy-Novice-Rule | รูปแบบกฎสามเณร Gin Rummy |
คุณสามารถใช้อินเทอร์เฟซต่อไปนี้เพื่อสร้างสภาพแวดล้อม คุณอาจเลือกระบุการกำหนดค่าบางอย่างด้วยพจนานุกรม
env_id เป็นสตริงของสภาพแวดล้อม config เป็นพจนานุกรมที่ระบุการกำหนดค่าสภาพแวดล้อมบางอย่างซึ่งมีดังนี้seed : None เริ่มต้น ตั้งค่าเมล็ดพันธุ์แบบสุ่มในท้องถิ่นเพื่อสร้างผลลัพธ์ซ้ำallow_step_back : ค่าเริ่ม False True ถ้าอนุญาตให้ฟังก์ชั่น step_back ข้ามไปข้างหลังในต้นไม้game_ ปัจจุบันเราสนับสนุนเฉพาะ game_num_players ในแบล็คแจ็ค,เมื่อสร้างสภาพแวดล้อมแล้วเราสามารถเข้าถึงข้อมูลบางอย่างของเกมได้
รัฐเป็นพจนานุกรม Python มันประกอบด้วย state['obs'] , การดำเนินการทางกฎหมาย state['legal_actions'] , state['raw_obs'] และการดำเนินการทางกฎหมายดิบ state['raw_legal_actions']
อินเทอร์เฟซต่อไปนี้ให้การใช้งานพื้นฐาน มันใช้งานง่าย แต่มีการสันนิษฐานในตัวแทน เอเจนต์จะต้องติดตามเทมเพลตเอเจนต์
agents เป็นรายการของวัตถุ Agent ความยาวของรายการควรเท่ากับจำนวนผู้เล่นในเกมset_agents หาก is_training เป็น True มันจะใช้ฟังก์ชั่น step ในเอเจนต์เพื่อเล่นเกม หาก is_training เป็น False eval_step จะถูกเรียกแทนสำหรับการใช้งานขั้นสูงอินเทอร์เฟซต่อไปนี้จะช่วยให้การทำงานที่ยืดหยุ่นบนแผนผังเกม อินเทอร์เฟซเหล่านี้ไม่ได้ทำการสันนิษฐานใด ๆ ในเอเจนต์
action อาจเป็นการกระทำที่ดิบหรือจำนวนเต็ม raw_action ควรเป็น True หากการกระทำคือการกระทำ RAW (สตริง)allow_step_back เป็น True ย้อนกลับไปหนึ่งก้าว สิ่งนี้สามารถใช้สำหรับอัลกอริทึมที่ทำงานบนต้นไม้เกมเช่น CFR (การสุ่มตัวอย่างโอกาส)True ถ้าเกมปัจจุบันจบลง otherewise กลับมา Falseplayer_idวัตถุประสงค์ของโมดูลหลักมีการระบุไว้ด้านล่าง:
สำหรับเอกสารเพิ่มเติมโปรดดูเอกสารสำหรับการแนะนำทั่วไป เอกสาร API มีอยู่ที่เว็บไซต์ของเรา
การมีส่วนร่วมในโครงการนี้ได้รับการชื่นชมอย่างมาก! โปรดสร้างปัญหาสำหรับข้อเสนอแนะ/ข้อบกพร่อง หากคุณต้องการมีส่วนร่วมในรหัสโปรดดูคู่มือการสนับสนุน หากคุณมีคำถามใด ๆ โปรดติดต่อ Daochen Zha ด้วย [email protected]
เราขอขอบคุณ JJ World Network Technology Co. , Ltd สำหรับการสนับสนุนที่ใจกว้างและการมีส่วนร่วมทั้งหมดจากผู้สนับสนุนชุมชน


