rlcard
RLCard 1.0.7
中文文档
RLCARD - это инструментарий для обучения подкреплению (RL) в карточных играх. Он поддерживает несколько карт среды с простыми в использовании интерфейсов для реализации различных алгоритмов обучения и поиска подкрепления. Целью RLCARD является преодоление подкрепления обучения и несовершенных информационных игр. RLCARD разрабатывается Data Lab в Университете Rice и Texas A & M и участниками сообщества.
Сообщество:
Новости:
Следующие игры в основном разрабатываются и поддерживаются участниками сообщества. Спасибо!
Спасибо всем участникам!




























Если вы найдете это репо полезным, вы можете процитировать:
Zha, Daochen, et al. «Rlcard: платформа для обучения подкреплению в карточных играх». Ijcai. 2020.
@inproceedings { zha2020rlcard ,
title = { RLCard: A Platform for Reinforcement Learning in Card Games } ,
author = { Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia } ,
booktitle = { IJCAI } ,
year = { 2020 }
} Убедитесь, что у вас установлен Python 3.6+ и PIP . Мы рекомендуем установить стабильную версию rlcard с pip :
pip3 install rlcard
Установка по умолчанию будет включать только среды карт. Чтобы использовать внедрение алгоритмов обучения, запустить
pip3 install rlcard[torch]
Если вы находитесь в Китае и вышеупомянутое команда слишком медленная, вы можете использовать зеркало, предоставленное Университетом Цинхуа:
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
В качестве альтернативы, вы можете клонировать последнюю версию (если вы находитесь в Китае, а GitHub медленно, вы можете использовать зеркало в Gitee):
git clone https://github.com/datamllab/rlcard.git
или только клонировать одну ветвь, чтобы сделать его быстрее:
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
Затем установите с
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
Мы также предоставляем метод установки Conda :
conda install -c toubun rlcard
Установка Conda предоставляет только среду карт, вам необходимо вручную установить Pytorch по вашим требованиям.
Краткий пример , как показано ниже.
import rlcard
from rlcard . agents import RandomAgent
env = rlcard . make ( 'blackjack' )
env . set_agents ([ RandomAgent ( num_actions = env . num_actions )])
print ( env . num_actions ) # 2
print ( env . num_players ) # 1
print ( env . state_shape ) # [[2]]
print ( env . action_shape ) # [None]
trajectories , payoffs = env . run ()RLCard может быть гибко подключен к различным алгоритмам. Смотрите следующие примеры:
Запустите examples/human/leduc_holdem_human.py чтобы играть с предварительно обученной моделью LEDUC HOLD'EM. Leduc Hold'em - упрощенная версия Texas Hold'em. Правила можно найти здесь.
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
Мы также предоставляем графический интерфейс для легкой отладки. Пожалуйста, проверьте здесь. Некоторые демонстрации:
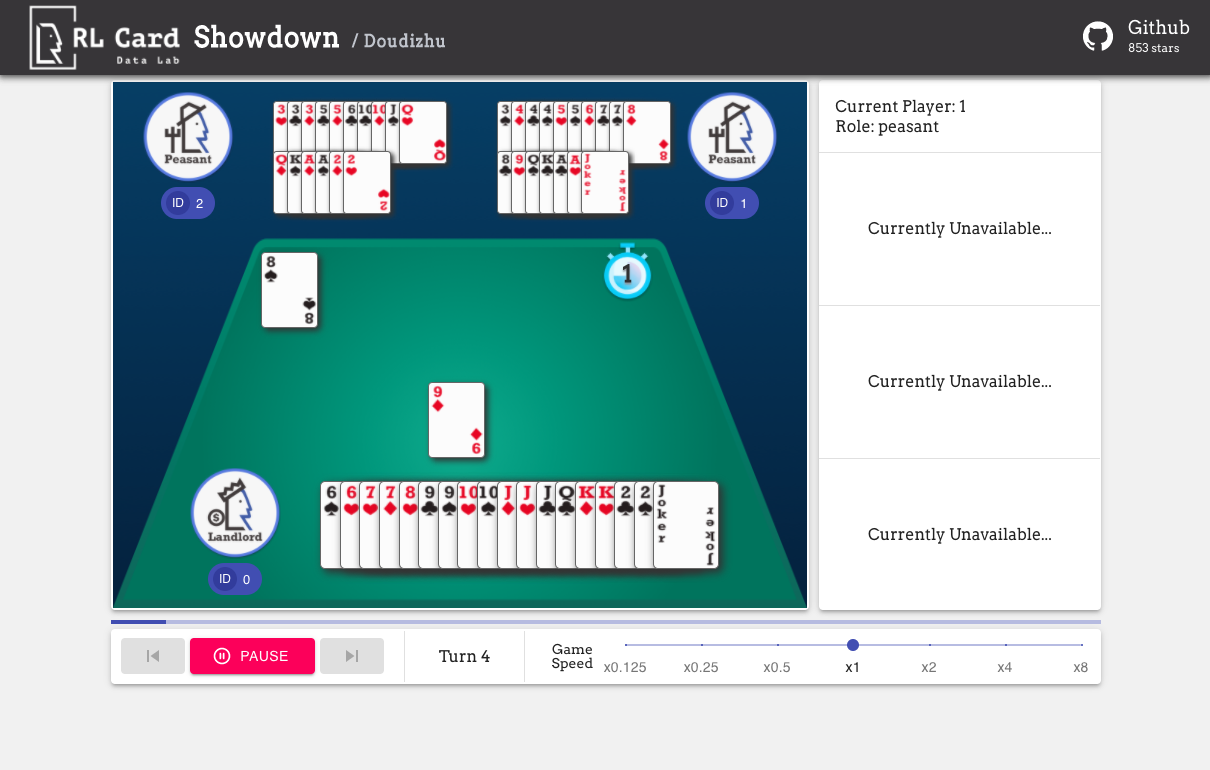
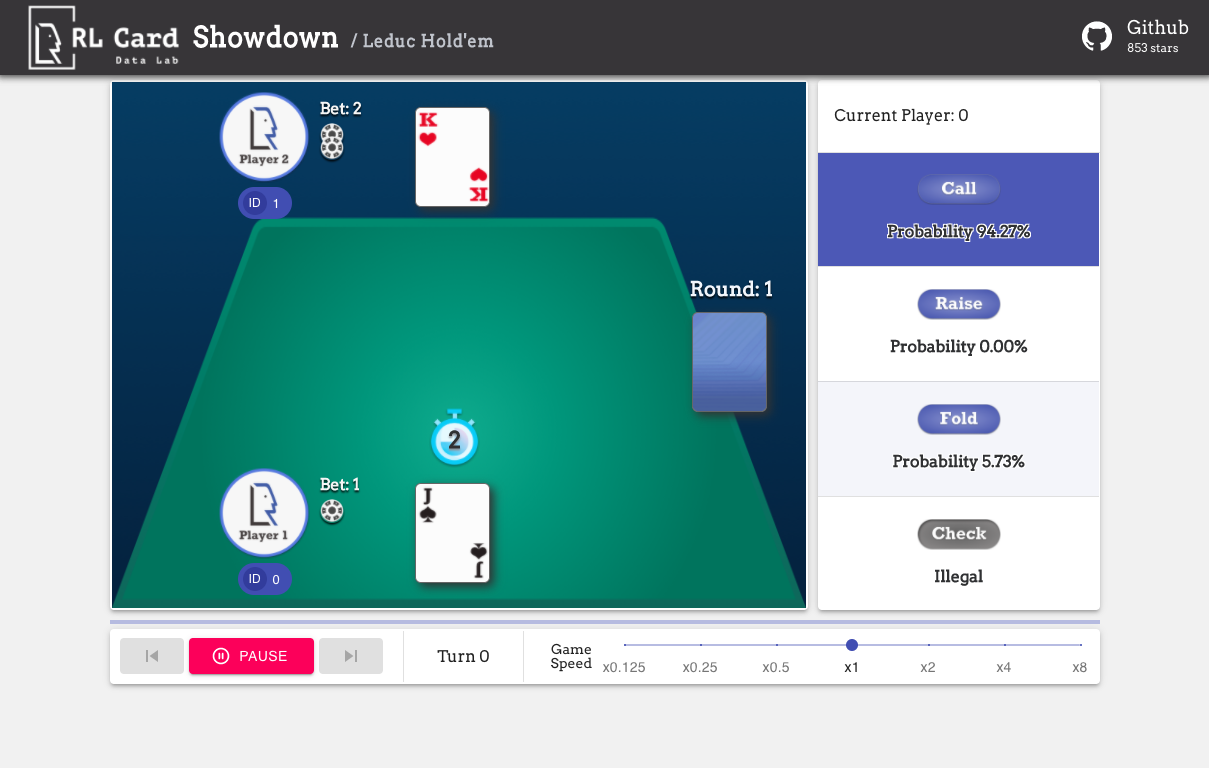
Мы предоставляем оценку сложности для игр по нескольким аспектам. НОМЕР INFOSET: количество информационных наборов; Размер Infoset: среднее количество состояний в одном наборе информации; Размер действия: размер пространства действия. Имя: Имя, которое должно быть передано в rlcard.make , чтобы создать игровую среду. Мы также предоставляем ссылку на документацию и случайный пример.
| Игра | Infoset номер | Размер Infoset | Размер действия | Имя | Использование |
|---|---|---|---|---|---|
| Блэкджек (Wiki, Baike) | 10^3 | 10^1 | 10^0 | блэкджек | Док, пример |
| Leduc hold'em (бумага) | 10^2 | 10^2 | 10^0 | Leduc-Holdem | Док, пример |
| Ограничьте Texas hold'em (Wiki, Baike) | 10^14 | 10^3 | 10^0 | лимитный-холм | Док, пример |
| Доу Дицху (Вики, Байк) | 10^53 ~ 10^83 | 10^23 | 10^4 | Дудижу | Док, пример |
| Маджонг (Вики, Байк) | 10^121 | 10^48 | 10^2 | маджонг | Док, пример |
| No-Limit Texas hold'em (Wiki, Baike) | 10^162 | 10^3 | 10^4 | без ограничений | Док, пример |
| Uno (Wiki, Baike) | 10^163 | 10^10 | 10^1 | ун | Док, пример |
| Джин Рамми (Вики, Байк) | 10^52 | - | - | Джин-Руми | Док, пример |
| Мост (Вики, Байк) | - | - | мост | Док, пример |
| Алгоритм | пример | ссылка |
|---|---|---|
| Глубокий Монте-Карло (DMC) | Примеры/run_dmc.py | [бумага] |
| Глубокое Q-обучение (DQN) | Примеры/run_rl.py | [бумага] |
| Нейронная вымышленная самостоятельная игра (NFSP) | Примеры/run_rl.py | [бумага] |
| Минимизация контрфактивного сожаления (CFR) | Примеры/run_cfr.py | [бумага] |
Мы предоставляем модельный зоопарк, чтобы служить базовым показателям.
| Модель | Объяснение |
|---|---|
| Leduc-Holdem-Cfr | Предварительно обученная модель CFR (случайная выборка) на LEDUC HOLD'EM |
| Leduc-Holdem-Rule-V1 | Модель на основе правил для LeDuc Hold'em, V1 |
| Leduc-Holdem-Rule-V2 | Модель на основе правил для LeDuc Hold'em, V2 |
| UNO-RULE-V1 | Модель на основе правил для Uno, v1 |
| предел-холд-руле-V1 | Модель на основе правил для ограничения Texas hold'em, v1 |
| Doudizhu-Rule-V1 | Модель на основе правил для Dou Dizhu, V1 |
| Джин-рамми-нович-руле | Модель правил новичка Джин Рамми |
Вы можете использовать следующий интерфейс для создания среды. Вы можете при желании указать некоторые конфигурации с помощью словаря.
env_id - это строка среды; config - это словарь, который определяет некоторые конфигурации среды, которые следующие.seed : по умолчанию None . Установите окружающую среду локальное случайное семя для воспроизведения результатов.allow_step_back : по умолчанию False . True , если разрешение функции step_back пройти назад в дереве.game_ . В настоящее время мы поддерживаем только game_num_players в Блэкджеке.Как только окружающая среда сделана, мы можем получить доступ к некоторой информации об игре.
Государство - это словарь Python. Он состоит из state['obs'] , юридических действий, state['legal_actions'] , необработанного state['raw_obs'] и state['raw_legal_actions'] .
Следующие интерфейсы обеспечивают базовое использование. Это прост в использовании, но у него есть предположения на агенте. Агент должен следовать шаблону агента.
agents - это список объекта Agent . Продолжительность списка должна быть равна количеству игроков в игре.set_agents . Если is_training True , он будет использовать функцию step в агенте для игры в игру. Если is_training является False , вместо этого будет вызван eval_step .Для расширенного использования следующие интерфейсы позволяют гибкие операции на дереве игры. Эти интерфейсы не делают никаких предположений на агенте.
action может быть необработанным действием или целым числом; raw_action должен быть True , если действие является необработанным действием (строка).allow_step_back True . Сделайте один шаг назад. Это может быть использовано для алгоритмов, которые работают на дереве игры, таких как CFR (случайная выборка).True если текущая игра закончилась. Вдали, верните False .player_id .Цели основных модулей перечислены, как показано ниже:
Для получения дополнительной документации, пожалуйста, обратитесь к документам для общих вступлений. Документы API доступны на нашем сайте.
Вклад в этот проект очень ценится! Пожалуйста, создайте проблему для отзывов/ошибок. Если вы хотите внести коды, пожалуйста, обратитесь к руководству. Если у вас есть какие -либо вопросы, пожалуйста, свяжитесь с Daochen Zha с [email protected].
Мы хотели бы поблагодарить JJ World Network Technology Co., Ltd за щедрую поддержку и все вклады со стороны участников сообщества.


