rlcard
RLCard 1.0.7
中文文档
RLCard es un kit de herramientas para el aprendizaje de refuerzo (RL) en los juegos de cartas. Admite múltiples entornos de tarjetas con interfaces fáciles de usar para implementar varios algoritmos de aprendizaje y búsqueda de refuerzo. El objetivo de RLCARD es unir el aprendizaje de refuerzo y los juegos de información imperfectos. RLCARD es desarrollado por Data Lab en la Universidad Rice y Texas A&M, y colaboradores comunitarios.
Comunidad:
Noticias:
Los siguientes juegos son desarrollados y mantenidos principalmente por contribuyentes de la comunidad. ¡Gracias!
¡Gracias a todos los contribuyentes!




























Si encuentra útil este repositorio, puede citar:
Zha, Daochen, et al. "Rlcard: una plataforma para el aprendizaje de refuerzo en los juegos de cartas". Ijcai. 2020.
@inproceedings { zha2020rlcard ,
title = { RLCard: A Platform for Reinforcement Learning in Card Games } ,
author = { Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia } ,
booktitle = { IJCAI } ,
year = { 2020 }
} Asegúrese de tener Python 3.6+ y PIP instalados. Recomendamos instalar la versión estable de rlcard con pip :
pip3 install rlcard
La instalación predeterminada solo incluirá los entornos de tarjetas. Para usar la implementación de Pytorch de los algoritmos de capacitación, ejecute
pip3 install rlcard[torch]
Si está en China y el comando anterior es demasiado lento, puede usar el espejo proporcionado por la Universidad de Tsinghua:
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
Alternativamente, puede clonar la última versión con (si está en China y GitHub es lento, puede usar el espejo en Gitee):
git clone https://github.com/datamllab/rlcard.git
o solo clone una rama para hacerlo más rápido:
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
Luego instalar con
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
También proporcionamos el método de instalación de Conda :
conda install -c toubun rlcard
La instalación de Conda solo proporciona los entornos de tarjetas, debe instalar manualmente Pytorch en sus demandas.
Un breve ejemplo es el siguiente.
import rlcard
from rlcard . agents import RandomAgent
env = rlcard . make ( 'blackjack' )
env . set_agents ([ RandomAgent ( num_actions = env . num_actions )])
print ( env . num_actions ) # 2
print ( env . num_players ) # 1
print ( env . state_shape ) # [[2]]
print ( env . action_shape ) # [None]
trajectories , payoffs = env . run ()Rlcard se puede conectar flexiblemente a varios algoritmos. Vea los siguientes ejemplos:
Ejecutar examples/human/leduc_holdem_human.py para jugar con el modelo Leduc Hold'em previamente capacitado. Leduc Hold'em es una versión simplificada de Texas Hold'em. Las reglas se pueden encontrar aquí.
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
También proporcionamos una GUI para una fácil depuración. Por favor consulte aquí. Algunas demostraciones:
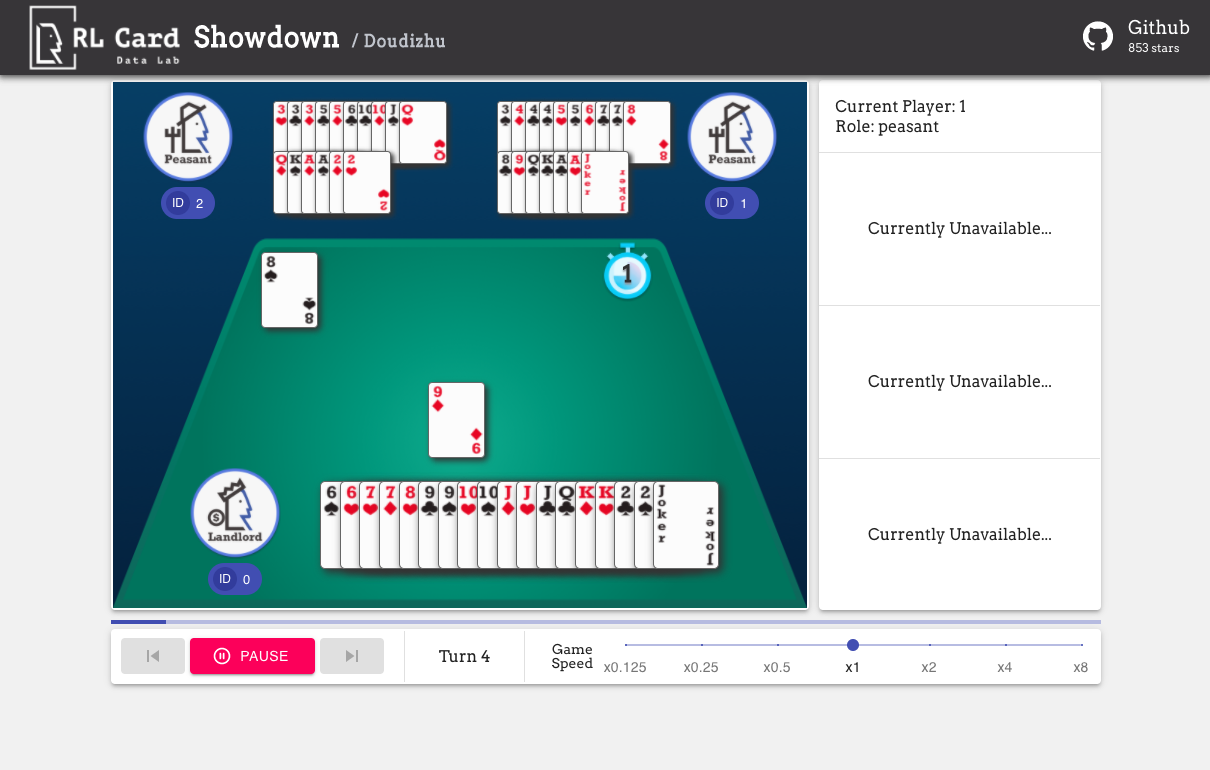
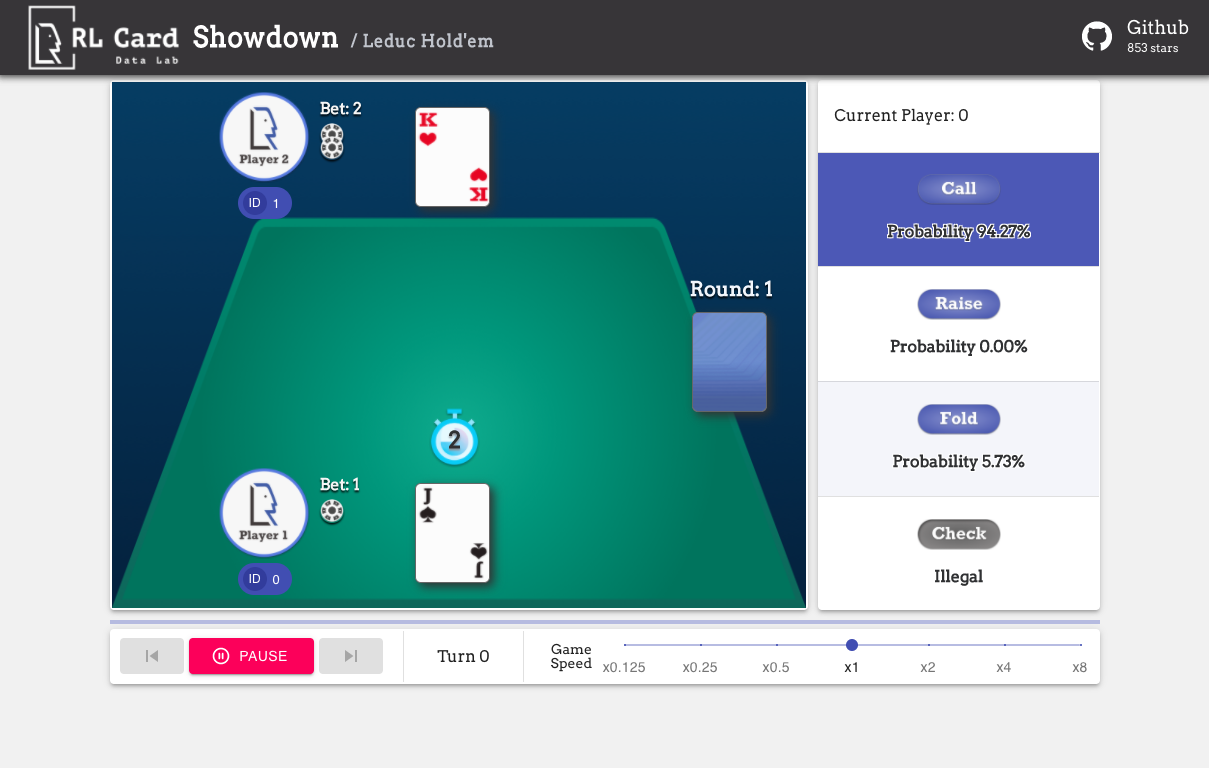
Proporcionamos una estimación de complejidad para los juegos en varios aspectos. Número de Infoset: el número de conjuntos de información; Tamaño de Infoset: el número promedio de estados en un solo conjunto de información; Tamaño de acción: el tamaño del espacio de acción. Nombre: El nombre que debe pasar a rlcard.make para crear el entorno del juego. También proporcionamos el enlace a la documentación y al ejemplo aleatorio.
| Juego | Número de infoset | Tamaño de infoset | Tamaño de acción | Nombre | Uso |
|---|---|---|---|---|---|
| Blackjack (wiki, baike) | 10^3 | 10^1 | 10^0 | veintiuna | doc, ejemplo |
| Leduc Hold'em (papel) | 10^2 | 10^2 | 10^0 | Leduc-Holdem | doc, ejemplo |
| Límite de Texas Hold'em (Wiki, Baike) | 10^14 | 10^3 | 10^0 | Límite-Holdem | doc, ejemplo |
| Dou Dizhu (Wiki, Baike) | 10^53 ~ 10^83 | 10^23 | 10^4 | doudizhu | doc, ejemplo |
| Mahjong (Wiki, Baike) | 10^121 | 10^48 | 10^2 | dominó chino | doc, ejemplo |
| No-Limit Texas Hold'em (Wiki, Baike) | 10^162 | 10^3 | 10^4 | sin límite | doc, ejemplo |
| Uno (wiki, baike) | 10^163 | 10^10 | 10^1 | desatado | doc, ejemplo |
| Gin Rummy (Wiki, Baike) | 10^52 | - | - | gin-rummy | doc, ejemplo |
| Puente (Wiki, Baike) | - | - | puente | doc, ejemplo |
| Algoritmo | ejemplo | referencia |
|---|---|---|
| Deep Monte-Carlo (DMC) | ejemplos/run_dmc.py | [papel] |
| Profundo Q-learning (DQN) | ejemplos/run_rl.py | [papel] |
| NEUNURA FICTIGO FICTUSTO (NFSP) | ejemplos/run_rl.py | [papel] |
| Minimización de arrepentimiento contrafáctico (CFR) | ejemplos/run_cfr.py | [papel] |
Proporcionamos un zoológico modelo para servir como líneas de base.
| Modelo | Explicación |
|---|---|
| Leduc-Holdem-CFR | Modelo de CFR previamente capacitado (muestreo casual) en Leduc Hold'em |
| Leduc-Holdem-Rule-V1 | Modelo basado en reglas para Leduc Hold'em, V1 |
| Leduc-Holdem-Rule-V2 | Modelo basado en reglas para Leduc Hold'em, V2 |
| uno-reglul-v1 | Modelo basado en reglas para UNO, V1 |
| límite-holdem-reghul-v1 | Modelo basado en reglas para Limit Texas Hold'em, V1 |
| doudizhu-rule-v1 | Modelo basado en reglas para Dou Dizhu, V1 |
| Gin-Rummy-Novice-Regla | Modelo de reglas de novato gin rummy |
Puede usar la siguiente interfaz para hacer un entorno. Opcionalmente, puede especificar algunas configuraciones con un diccionario.
env_id es una cadena de un entorno; config es un diccionario que especifica algunas configuraciones de entorno, que son las siguientes.seed : predeterminado None . Establezca una semilla aleatoria local de entorno para reproducir los resultados.allow_step_back : predeterminado False . True si permite que la función step_back atraviese hacia atrás en el árbol.game_ . Actualmente, solo apoyamos game_num_players en Blackjack ,.Una vez que se realiza el entorno, podemos acceder a alguna información del juego.
El estado es un diccionario de Python. Consiste en state['obs'] , state['legal_actions'] , state['raw_obs'] y state['raw_legal_actions'] .
Las siguientes interfaces proporcionan un uso básico. Es fácil de usar, pero tiene asumencias en el agente. El agente debe seguir la plantilla del agente.
agents es una lista de objeto de Agent . La longitud de la lista debe ser igual al número de jugadores en el juego.set_agents . Si is_training es True , usará la función step en el agente para jugar el juego. Si is_training es False , se llamará eval_step .Para el uso avanzado, las siguientes interfaces permiten operaciones flexibles en el árbol de juegos. Estas interfaces no hacen ninguna suposición en el agente.
action puede ser acción o entero en bruto; raw_action debe ser True si la acción es Acción Raw (String).allow_step_back es True . Da un paso hacia atrás. Esto se puede utilizar para algoritmos que funcionan en el árbol de juego, como CFR (muestreo de Chance).True si el juego actual ha terminado. Otro, devuelve False .player_id .Los propósitos de los módulos principales se enumeran como a continuación:
Para obtener más documentación, consulte los documentos para las presentaciones generales. Los documentos API están disponibles en nuestro sitio web.
¡La contribución a este proyecto es muy apreciada! Cree un problema para comentarios/errores. Si desea contribuir con códigos, consulte la guía de contribución. Si tiene alguna pregunta, comuníquese con Daochen Zha con [email protected].
Nos gustaría agradecer a JJ World Network Technology Co., Ltd por el generoso apoyo y todas las contribuciones de los contribuyentes de la comunidad.


