rlcard
RLCard 1.0.7
中文文档
RLCardは、カードゲームのRehnection Learning(RL)のためのツールキットです。さまざまな強化学習と検索アルゴリズムを実装するための使いやすいインターフェイスを備えた複数のカード環境をサポートしています。 RLCardの目標は、補強学習と不完全な情報ゲームを橋渡しすることです。 RLCardは、RiceおよびTexas A&M UniversityのData Labによって開発され、コミュニティの貢献者が開発されています。
コミュニティ:
ニュース:
次のゲームは、主にコミュニティの貢献者によって開発および維持されています。ありがとう!
すべての貢献者に感謝します!




























このリポジトリが便利だと思う場合は、引用することができます。
Zha、Daochen、他「RLCARD:カードゲームでの強化学習のためのプラットフォーム。」 ijcai。 2020。
@inproceedings { zha2020rlcard ,
title = { RLCard: A Platform for Reinforcement Learning in Card Games } ,
author = { Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia } ,
booktitle = { IJCAI } ,
year = { 2020 }
}Python 3.6+とPIPがインストールされていることを確認してください。 rlcardの安定したバージョンをpipでインストールすることをお勧めします。
pip3 install rlcard
デフォルトのインストールには、カード環境のみが含まれます。トレーニングアルゴリズムのPytorch実装を使用するには、実行します
pip3 install rlcard[torch]
あなたが中国にいて、上記の命令が遅すぎる場合、Tsinghua Universityが提供する鏡を使用できます。
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
または、最新のバージョンをクローンでクローンすることができます(中国にいて、Githubが遅い場合は、Giteeでミラーを使用できます):
git clone https://github.com/datamllab/rlcard.git
または、1つのブランチのみをクローンして高速にします。
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
次に、インストールします
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
また、 Condaのインストール方法も提供しています。
conda install -c toubun rlcard
Condaのインストールはカード環境のみを提供するため、Pytorchを手動で要求に合わせてインストールする必要があります。
簡単な例は以下のとおりです。
import rlcard
from rlcard . agents import RandomAgent
env = rlcard . make ( 'blackjack' )
env . set_agents ([ RandomAgent ( num_actions = env . num_actions )])
print ( env . num_actions ) # 2
print ( env . num_players ) # 1
print ( env . state_shape ) # [[2]]
print ( env . action_shape ) # [None]
trajectories , payoffs = env . run ()RLCardは、さまざまなアルゴリズムに柔軟に接続できます。次の例を参照してください。
examples/human/leduc_holdem_human.py事前に訓練されたLeduchold'emモデルで遊ぶ。 Leduc Hold'emは、Texas Hold'emの簡素化されたバージョンです。ルールはここにあります。
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
また、簡単にデバッグするためのGUIを提供します。ここで確認してください。いくつかのデモ:
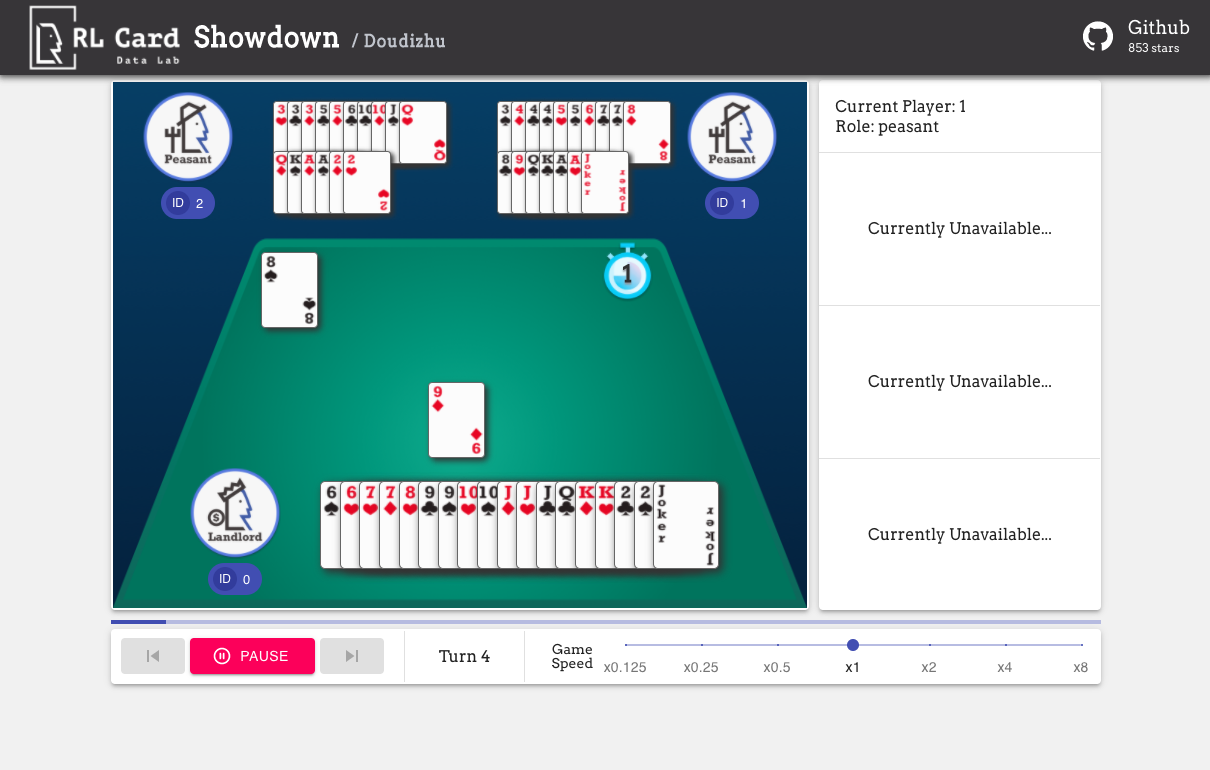
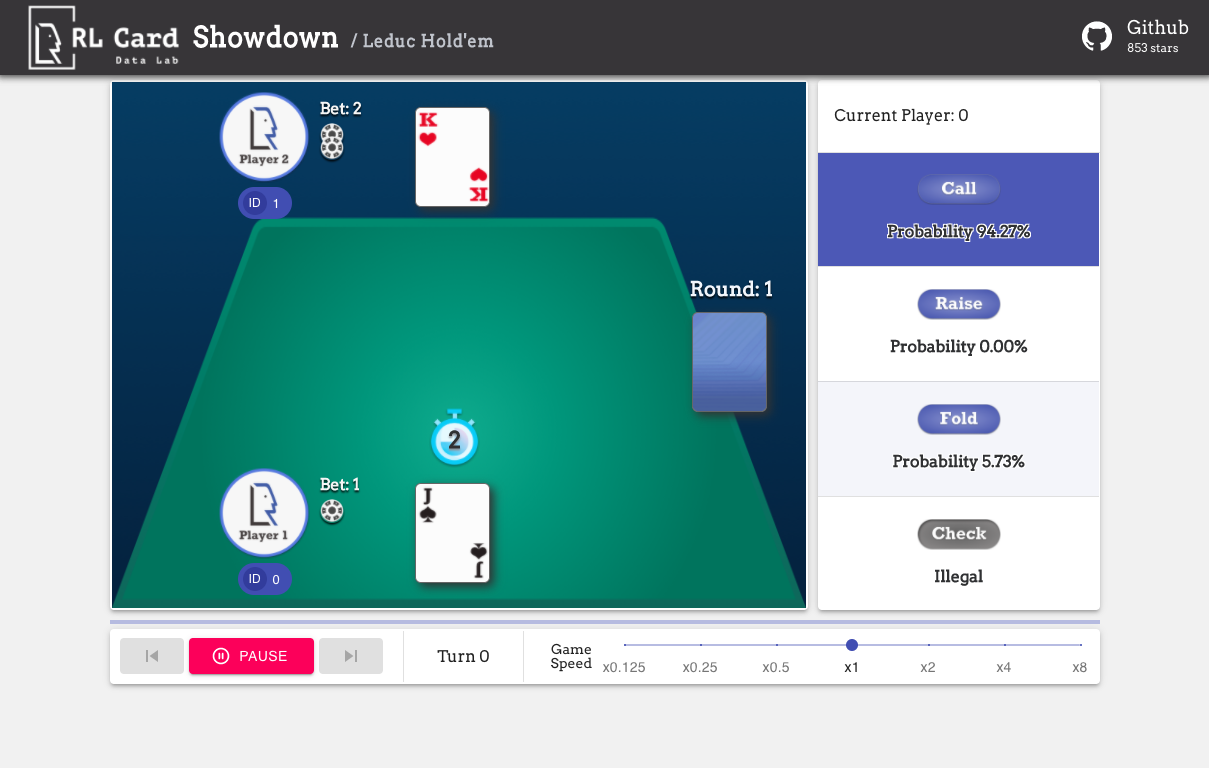
いくつかの側面でゲームの複雑さの推定を提供します。 INFOSET番号:情報セットの数。 INFOSETサイズ:単一の情報セット内の状態の平均数。アクションサイズ:アクションスペースのサイズ。名前: rlcard.makeに渡す必要がある名前は、ゲーム環境を作成します。また、ドキュメントへのリンクとランダムな例を提供します。
| ゲーム | インフォセット番号 | インフォセットサイズ | アクションサイズ | 名前 | 使用法 |
|---|---|---|---|---|---|
| ブラックジャック(ウィキ、バイク) | 10^3 | 10^1 | 10^0 | ブラックジャック | ドキュメント、例 |
| Leduc Hold'em(紙) | 10^2 | 10^2 | 10^0 | leduc-holdem | ドキュメント、例 |
| テキサスホールデムを制限する(ウィキ、バイク) | 10^14 | 10^3 | 10^0 | Limit-Holdem | ドキュメント、例 |
| Dou Dizhu(Wiki、Baike) | 10^53〜10^83 | 10^23 | 10^4 | Doudizhu | ドキュメント、例 |
| マジョン(ウィキ、バイク) | 10^121 | 10^48 | 10^2 | マジョン | ドキュメント、例 |
| 無線テキサスHold'em(Wiki、Baike) | 10^162 | 10^3 | 10^4 | limit-holdem | ドキュメント、例 |
| uno(wiki、baike) | 10^163 | 10^10 | 10^1 | uno | ドキュメント、例 |
| ジン・ラミー(ウィキ、バイク) | 10^52 | - | - | ジン・ラミー | ドキュメント、例 |
| ブリッジ(ウィキ、バイケ) | - | - | 橋 | ドキュメント、例 |
| アルゴリズム | 例 | 参照 |
|---|---|---|
| ディープモンテカルロ(DMC) | 例/run_dmc.py | [紙] |
| ディープQラーニング(DQN) | 例/run_rl.py | [紙] |
| 神経架空の自己プレイ(NFSP) | 例/run_rl.py | [紙] |
| 反事実的後悔の最小化(CFR) | 例/run_cfr.py | [紙] |
ベースラインとして機能するモデル動物園を提供します。
| モデル | 説明 |
|---|---|
| leduc-holdem-cfr | Leduc Hold'emの事前訓練を受けたCFR(チャンスサンプリング)モデル |
| leduc-holdem-rule-v1 | Leduc Hold'emのルールベースのモデル、v1 |
| leduc-holdem-rule-v2 | Leduc Hold'emのルールベースのモデル、v2 |
| UNO-RULE-V1 | UNOのルールベースのモデル、V1 |
| Limit-holdem-rule-v1 | Limit Texas Hold'em、v1のルールベースのモデル |
| Doudizhu-rule-V1 | Dou Dizhuのルールベースのモデル、v1 |
| Gin-Rummy-Novice-rule | ジンラミー初心者ルールモデル |
次のインターフェイスを使用して、環境を作成できます。オプションで、辞書でいくつかの構成を指定できます。
env_idは環境の文字列です。 config 、次のような環境構成を指定する辞書です。seed :デフォルトNone 。結果を再現するための環境ローカルランダムシードを設定します。allow_step_back :デフォルトのFalse 。 True step_back関数がツリー内で後方に移動できるようにする場合。game_で始まります。現在、BlackJackでgame_num_playersのみをサポートしています。Environemntが作成されたら、ゲームの情報にアクセスできます。
状態はPython辞書です。観察state['obs'] 、法的措置state['legal_actions'] 、生の観察state['raw_obs'] 、および生の法的措置state['raw_legal_actions']で構成されています。
次のインターフェイスは、基本的な使用法を提供します。使いやすいですが、エージェントに仮定があります。エージェントはエージェントテンプレートに従う必要があります。
agents Agentオブジェクトのリストです。リストの長さは、ゲーム内のプレイヤーの数に等しくなければなりません。set_agentsが呼び出された後に使用できます。 is_trainingがTrue場合、エージェントのstep関数を使用してゲームを再生します。 is_trainingがFalseの場合、 eval_stepが代わりに呼び出されます。高度な使用のために、次のインターフェイスにより、ゲームツリーの柔軟な操作が可能になります。これらのインターフェイスは、エージェントに仮定を作成しません。
action 、生のアクションまたは整数です。アクションがrawアクション(string)の場合、 raw_action Trueなければなりません。allow_step_back Trueの場合にのみ利用可能です。一歩後退します。これは、CFR(チャンスサンプリング)などのゲームツリーで動作するアルゴリズムに使用できます。Trueを返します。まず、 Falseを返します。player_idに対応する状態を返します。メインモジュールの目的を以下にリストします。
詳細については、一般的な紹介についてはドキュメントを参照してください。 APIドキュメントは当社のWebサイトで入手できます。
このプロジェクトへの貢献は大歓迎です!フィードバック/バグについては問題を作成してください。コードを寄付したい場合は、寄稿ガイドを参照してください。ご質問がある場合は、[email protected]でDaochen Zhaに連絡してください。
JJ World Network Technology Co.、Ltd、寛大なサポートとコミュニティの貢献者からのすべての貢献について感謝します。


