sane tts
1.0.0
Авторы: Hyunjae Cho, Wonbin Jung, Junhyeok Lee, Sang Hoon woo @mindslab Inc.
Аннотация: В этой статье мы представляем Sane-TTS, стабильную и естественную сквозную многоязычную модель TTS. Благодаря сложности получения многоязычного корпуса для данного докладчика, обучение многоязычной модели TTS с одноязычными корпусами неизбежно. Мы вводим потерю регуляризации динамиков, которая улучшает естественность речи во время кросс-лингального синтеза, а также доменное состязательное обучение, которое применяется в других многоязычных моделях TTS. Кроме того, добавив потерю регуляризации динамиков, заменив встраивание динамиков с нулевым вектором в продолжительность предиктора стабилизирует междингальные выводы. С этой заменой наша модель генерирует речи с умеренным ритмом независимо от динамика источника в кросс-лингальном синтезе. При оценке MOS SANE-TTS достигает естественной оценки выше 3,80 как в кросс-лингальном, так и внутри интралингального синтеза, где балл основной истины составляет 3,99. Кроме того, SANE-TTS поддерживает сходство ораторов, близкое к сходной истине, даже в межсочевированном выводе. Образцы аудио доступны на нашей веб -странице.
| Процедура обучения | Процедура вывода |
|---|---|
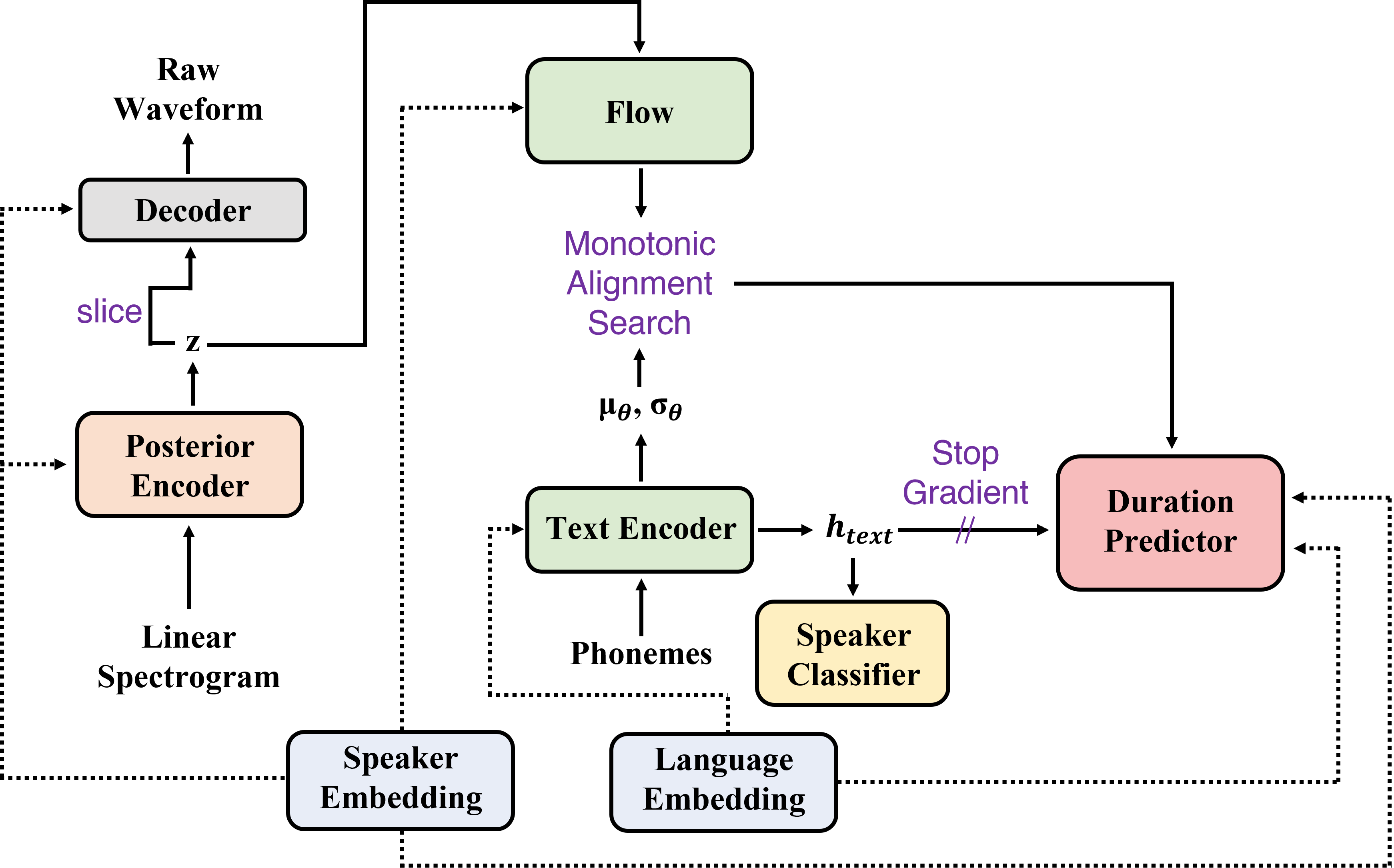 | 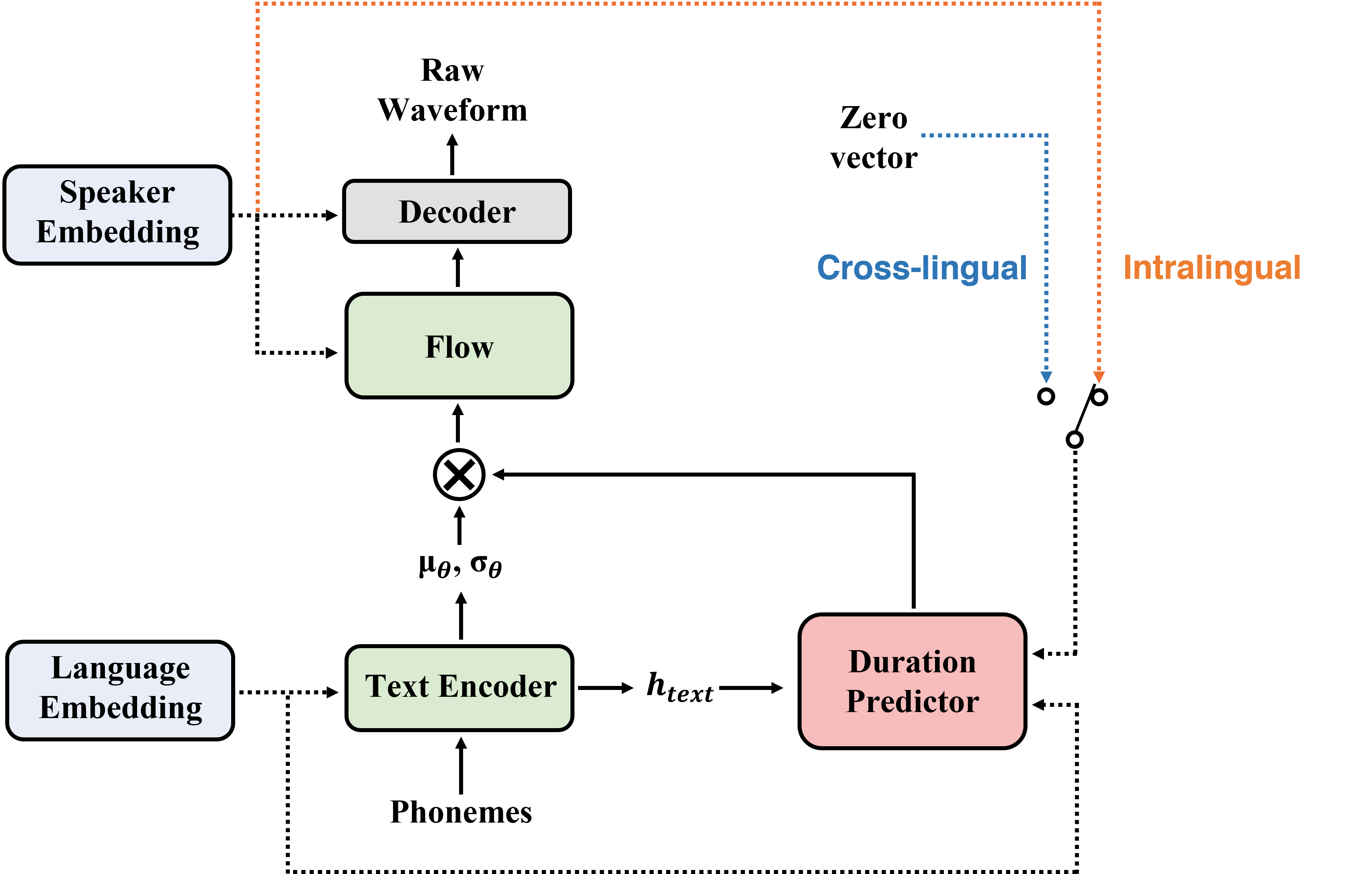 |


