sane tts
1.0.0
Autoren: Hyunjae Cho, Wonbin Jung, Junhyeok Lee, Sang Hoon Woo @mindslab Inc.
Zusammenfassung: In diesem Artikel präsentieren wir Sane-TTs, ein stabiles und natürliches End-to-End-mehrsprachiger TTS-Modell. Durch die Schwierigkeit, mehrsprachige Korpus für einen bestimmten Sprecher zu erhalten, ist das Training mehrsprachiger TTS -Modell mit einsprachigen Korpora unvermeidlich. Wir führen den Lautsprecher-Regularisierungsverlust ein, der die Sprachnatürlichkeit während der interlingualen Synthese sowie das domänengegnerische Training verbessert, das in anderen mehrsprachigen TTS-Modellen angewendet wird. Darüber hinaus stabilisiert der Ersetzen von Lautsprechern durch Zugabe von Lautsprecher-Regularisierungsverlust durch die Einbettung des Lautsprechers durch den Nullvektor in Dauer-Prädiktor die Kreuzungsinferenz. Mit diesem Ersatz erzeugt unser Modell Reden mit moderatem Rhythmus, unabhängig vom Quellsprecher in der Kreuzungssynthese. Bei der MOS-Bewertung erreicht Sane-TTS sowohl bei der Kreuzungs- als auch bei intralingualer Synthese, wobei der Grundwahrheitswert 3,99 beträgt. Auch Sane-TTS behält die Ähnlichkeit der Sprecher, die der der Bodenwahrheit nahe stand, selbst in bringlicher Schlussfolgerung nahe. Audio -Samples sind auf unserer Webseite verfügbar.
| Schulungsverfahren | Inferenzverfahren |
|---|---|
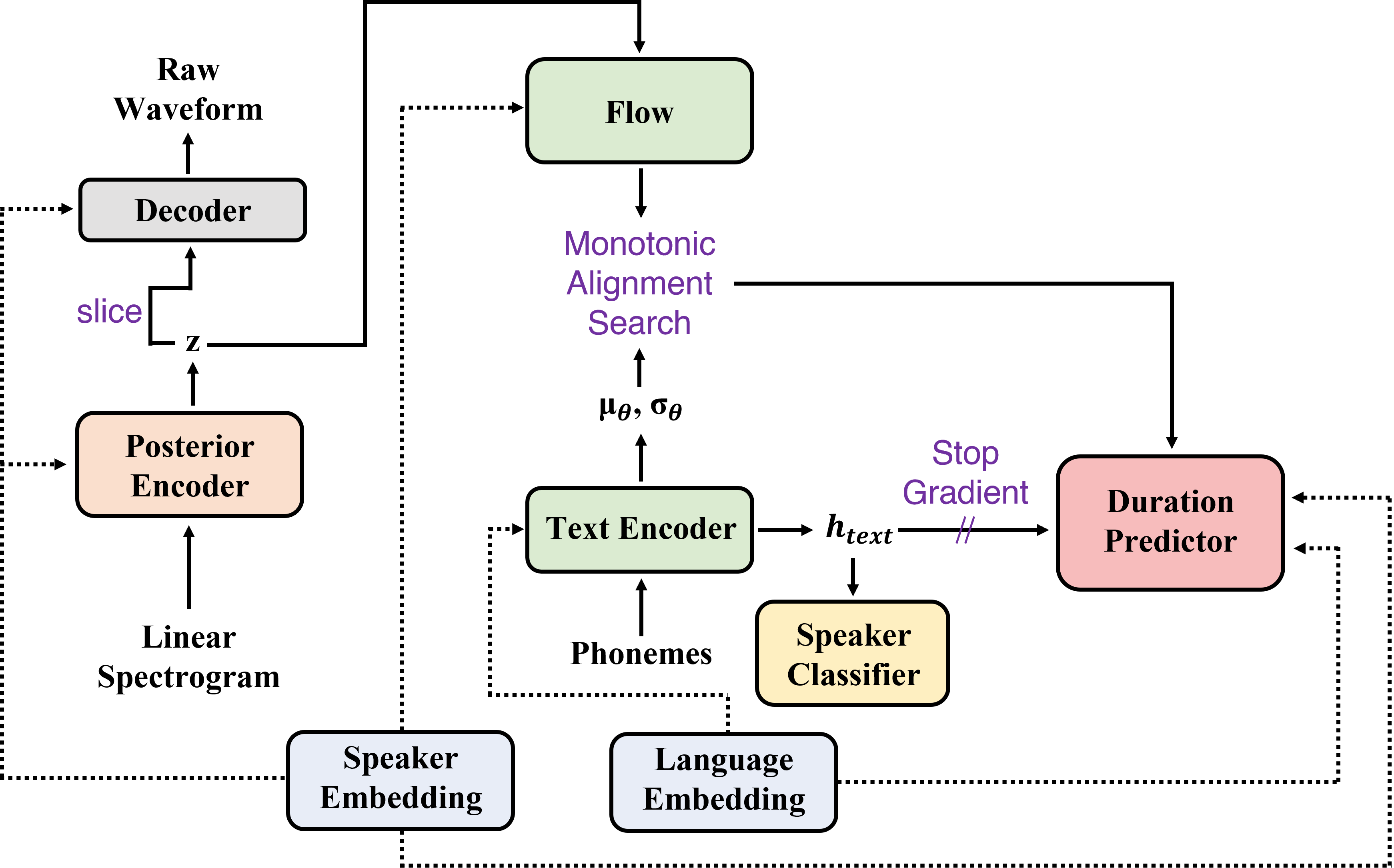 | 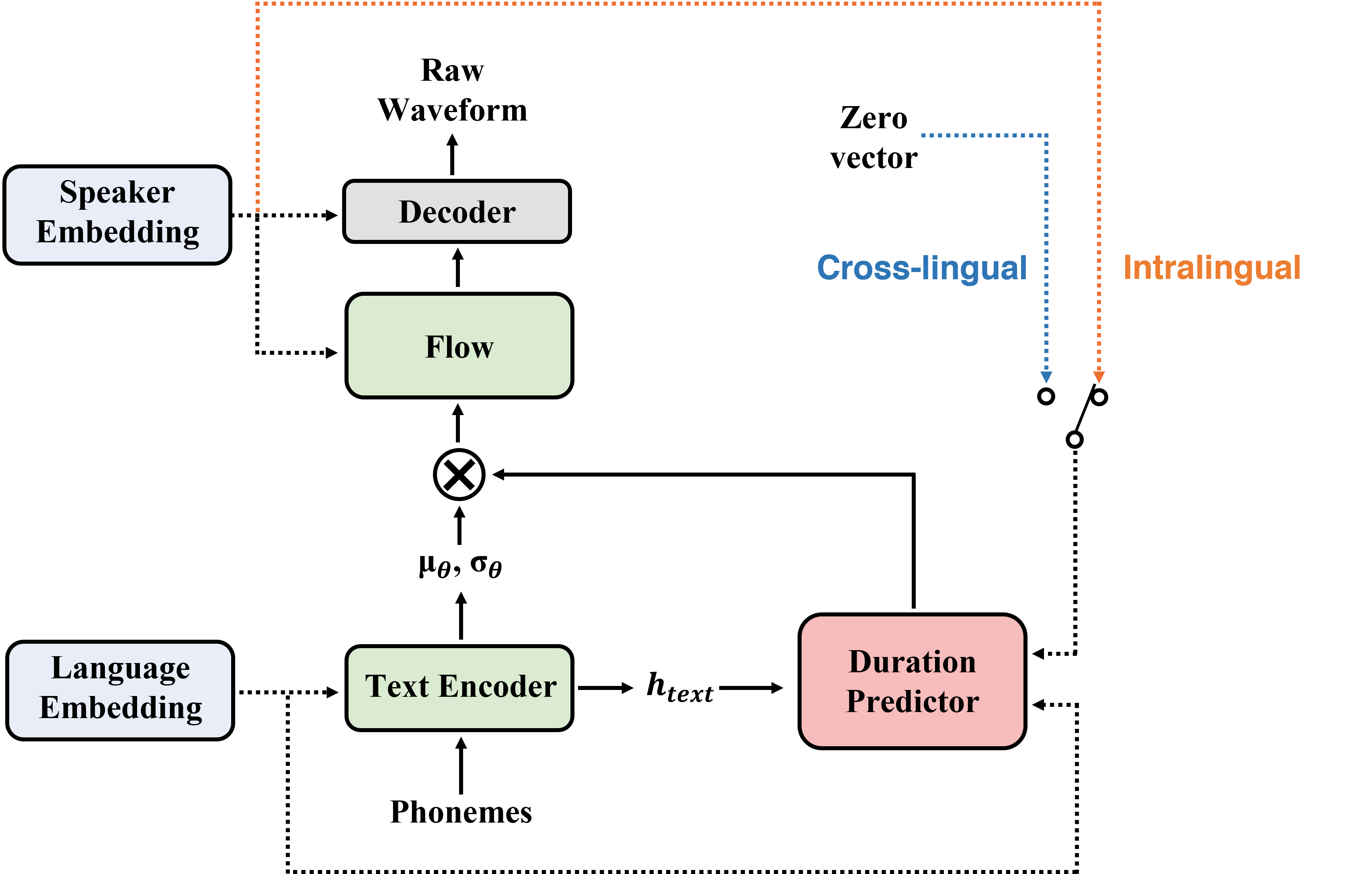 |


