sane tts
1.0.0
Auteurs: Hyunjae Cho, Wonbin Jung, Junhyeok Lee, a chanté Hoon Woo @Mindslab Inc.
Résumé: Dans cet article, nous présentons SANE-TTS, un modèle TTS multilingue de bout en bout stable et naturel. Par la difficulté d'obtenir un corpus multilingue pour un haut-parleur donné, la formation du modèle TTS multilingue avec des corpus monolingues est inévitable. Nous introduisons la perte de régularisation des locuteurs qui améliore le naturel de la parole pendant la synthèse inter-greatrice ainsi que la formation adversaire du domaine, qui est appliquée dans d'autres modèles TTS multilingues. En outre, en ajoutant une perte de régularisation du haut-parleur, le remplacement de l'incorporation du haut-parleur par un vecteur zéro de durée prédicteur stabilise l'inférence cross-linguale. Avec ce remplacement, notre modèle génère des discours avec un rythme modéré, quel que soit le haut-parleur source dans la synthèse inter-linguale. Dans l'évaluation du MOS, SANE-TTS réalise le score de naturel supérieur à 3,80 à la fois en synthèse inter-lingue et intralinguée, où le score de vérité au sol est de 3,99. En outre, SANE-TTS maintient la similitude des orateurs à proximité de celle de la vérité du sol même dans l'inférence croisée. Des échantillons audio sont disponibles sur notre page Web.
| Procédure de formation | Procédure d'inférence |
|---|---|
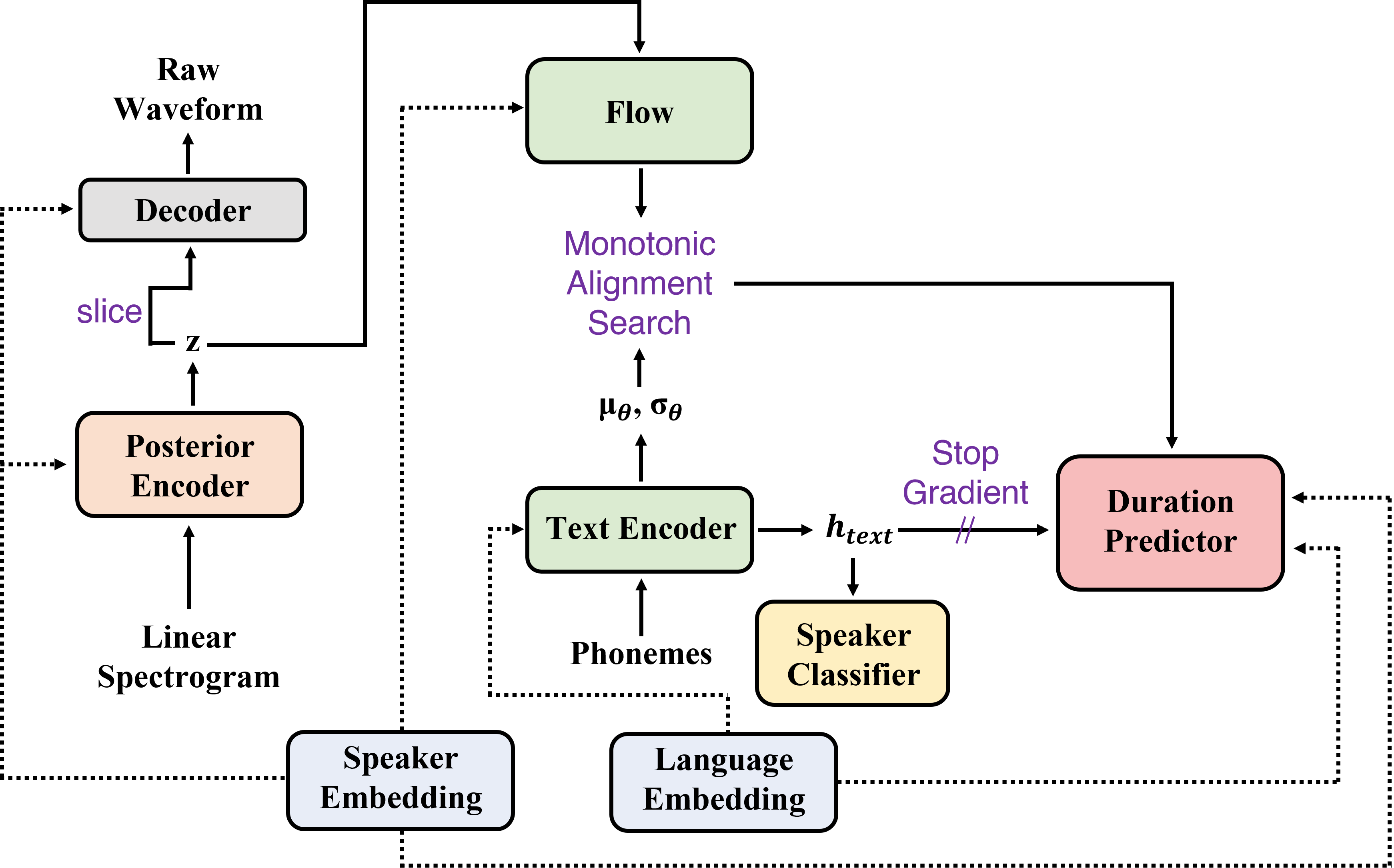 | 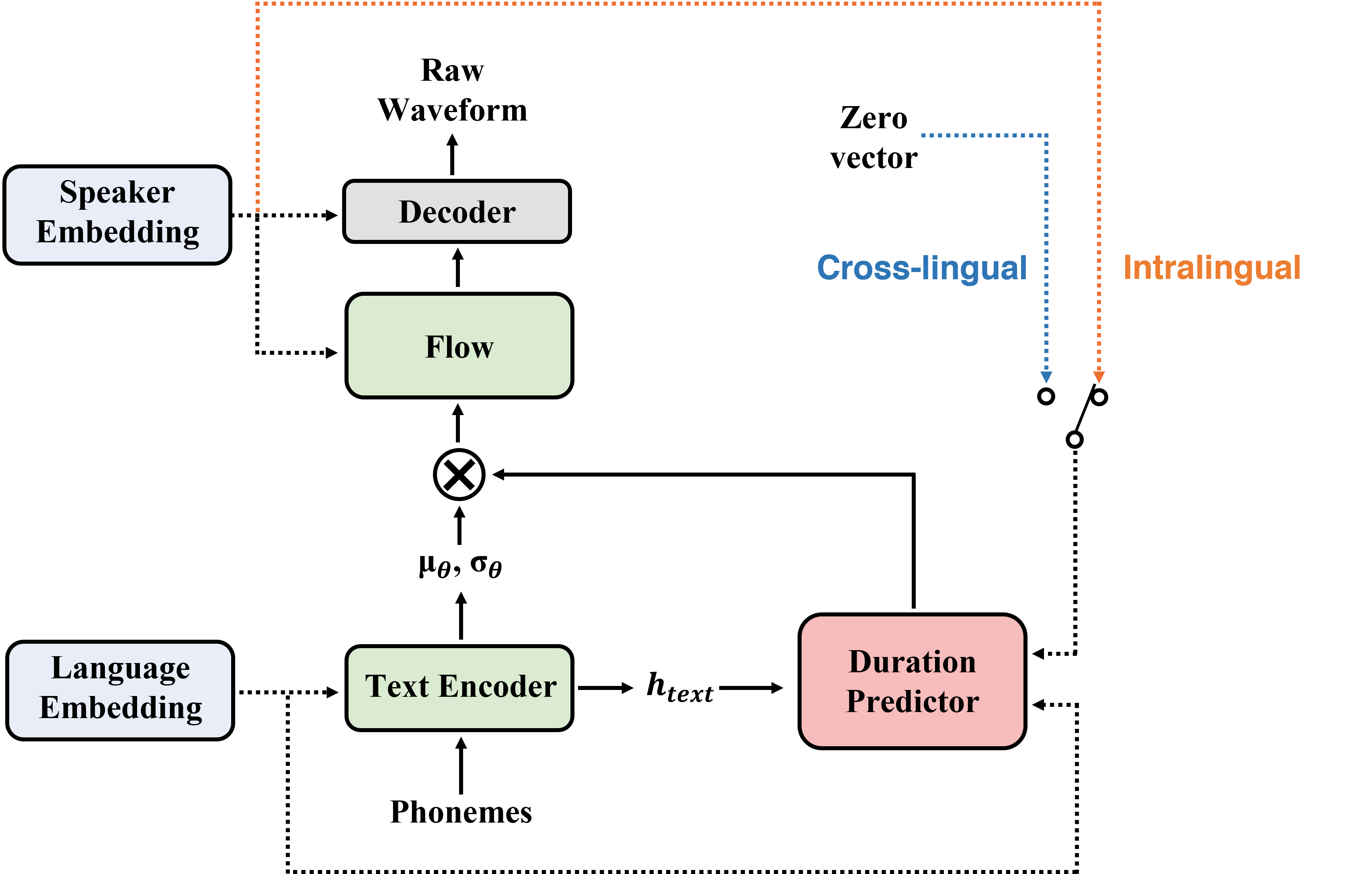 |


