sane tts
1.0.0
Autores: Hyunjae Cho, Wonbin Jung, Junhyeok Lee, Sang Hoon Woo @mindslab Inc.
Resumen: En este artículo, presentamos Sane-TTS, un modelo TTS multilingüe estable y natural de extremo a extremo. Mediante la dificultad de obtener un corpus multilingüe para el altavoz dado, la capacitación del modelo multilingüe TTS con corpus monolingües es inevitable. Introducimos la pérdida de regularización de los oradores que mejora la naturalidad del habla durante la síntesis interlingüística, así como el entrenamiento adversario de dominio, que se aplica en otros modelos multilingües TTS. Además, al agregar pérdida de regularización del altavoz, reemplazando la incrustación de altavoces con vector cero en el predictor de duración estabiliza la inferencia interlingüística. Con este reemplazo, nuestro modelo genera discursos con ritmo moderado independientemente del hablante de origen en la síntesis interlingüística. En la evaluación de MOS, Sane-TTS logra la puntuación de naturalidad por encima de 3.80 tanto en síntesis interlingüística como intralingual, donde la puntuación de la verdad del suelo es 3.99. Además, Sane-TTS mantiene la similitud de los hablantes cerca de la de la verdad terrestre incluso en la inferencia interlingüística. Las muestras de audio están disponibles en nuestra página web.
| Procedimiento de capacitación | Procedimiento de inferencia |
|---|---|
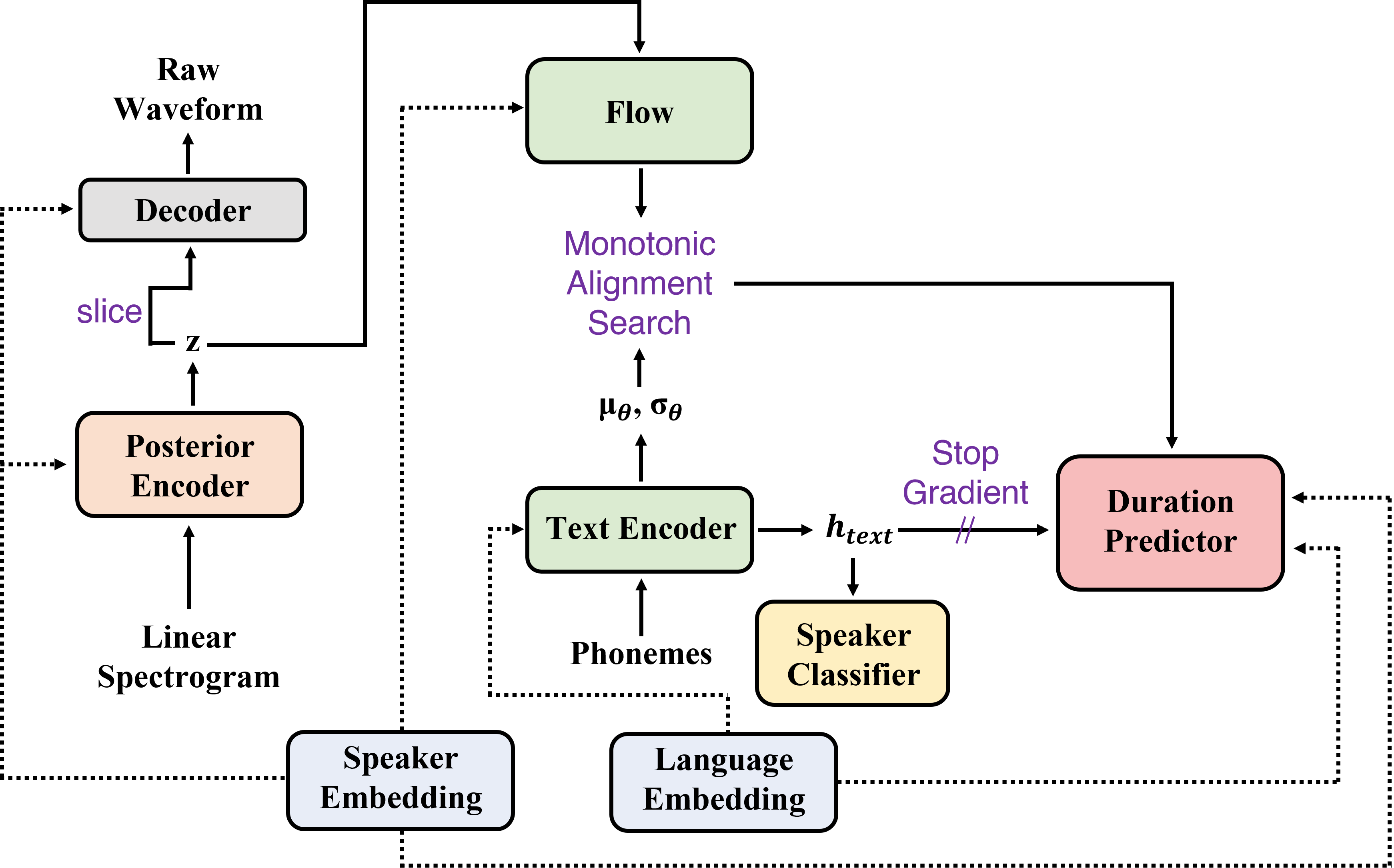 | 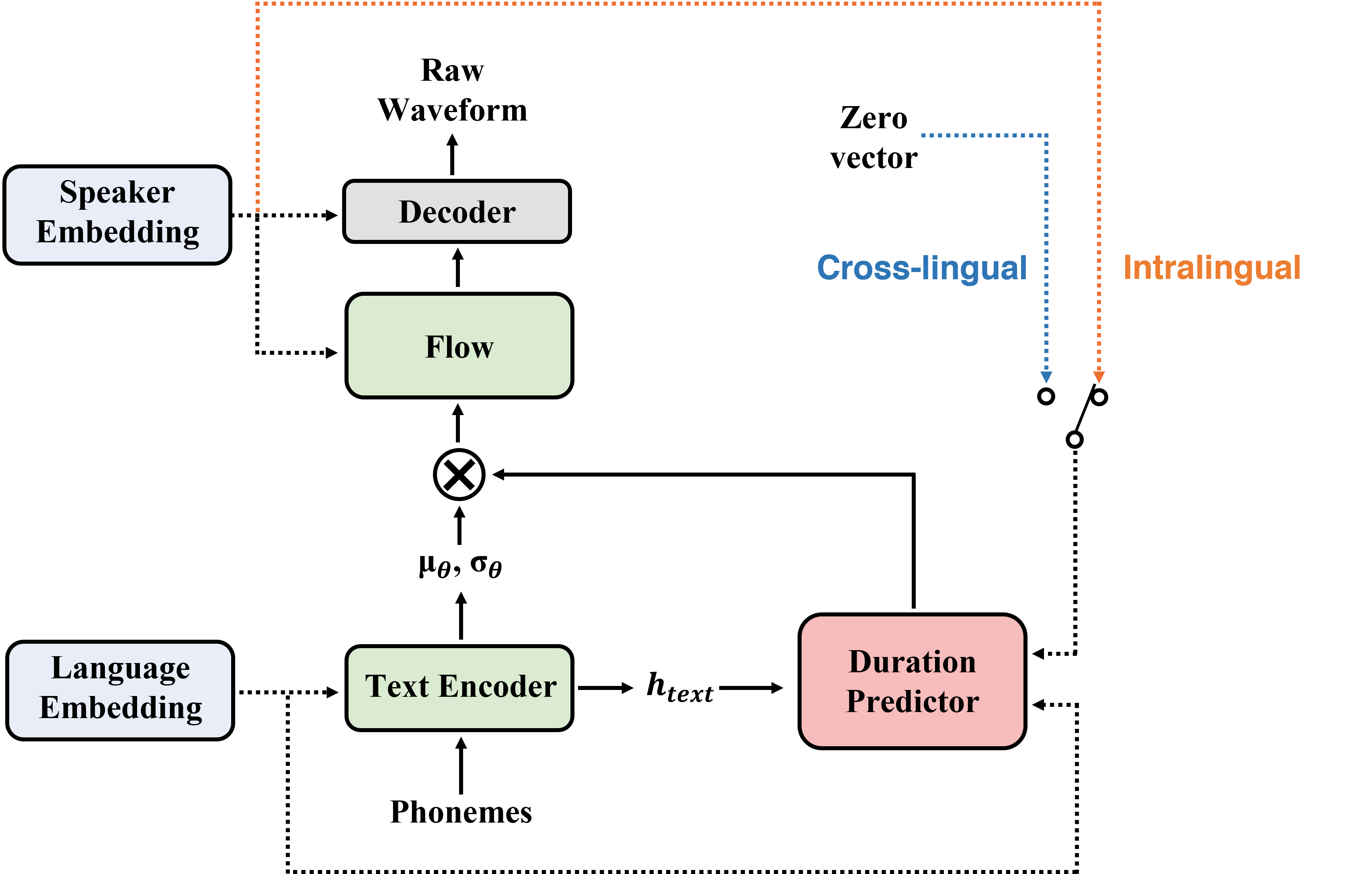 |


