mychatGPT
1.0.0
Этот проект превратился из простого чат-бота в PDF до сложного агента тряпичной тряпичной тряпичной тряпки (поиск-аугированное поколение), способного получить доступ к истории разговоров, получение контекста, суммирование документов и ответа на последующие вопросы, основанные на запросах пользователей и обнаружении намерений.
Попробуйте сами в агентском раг
Скриншот: 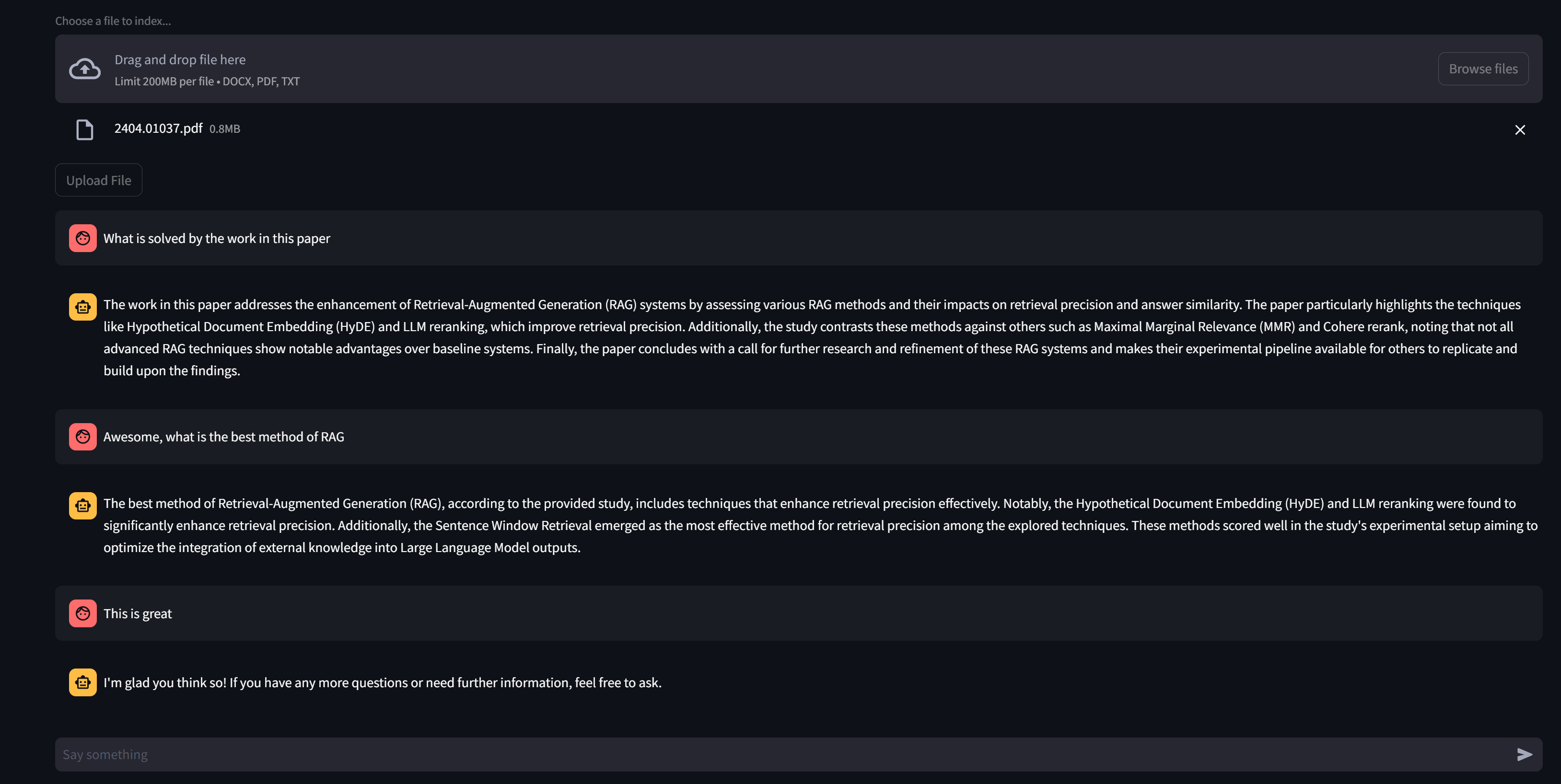
Чтобы настроить этот проект, вам сначала понадобится ваш ключ OpenAI_API. Затем убедитесь, что у вас установлены необходимые зависимости. Вы можете установить их через:
pip install -r requirements.txt
Чтобы запустить агент RAG, запустите команду:
python -m streamlit run agentic_rag.py
Это запустит приложение Streamlit в вашем браузере. После запуска вы можете загрузить свои документы .pdf, .txt, .docx и начать запрашивать естественным образом для резюме, подробные запросы и последующие вопросы!
.pdf, .txt, .docx документы непосредственно в интерфейсе приложения. Этот проект является постоянной попыткой расширить возможности агента RAG. Хотя функциональность в настоящее время демонстрируется в предоставленном файле .py, дальнейшие события продолжаются. Следите за обновлениями, когда я перехожу этот проект в полностью функциональное приложение, которое позволяет локально выполнять и выбор PDF через удобный интерфейс.
С уважением ?
Apache2.0
Наслаждайтесь взаимодействием с вашими документами через этого интеллектуального агента Rag!


