SoCodec
1.0.0
Esse repositório contém scripts de inferência para o Socodec, um codec de fala ultra-baixo-bitrato, dedicado aos modelos de linguagem de fala, introduzido no artigo intitulado Socodec: um codec de fala multi-stream ordenado semântico para síntese de texto em expressão baseada em linguagem eficiente .
Papel
? Site de demonstração
⚙ Pesos do modelo
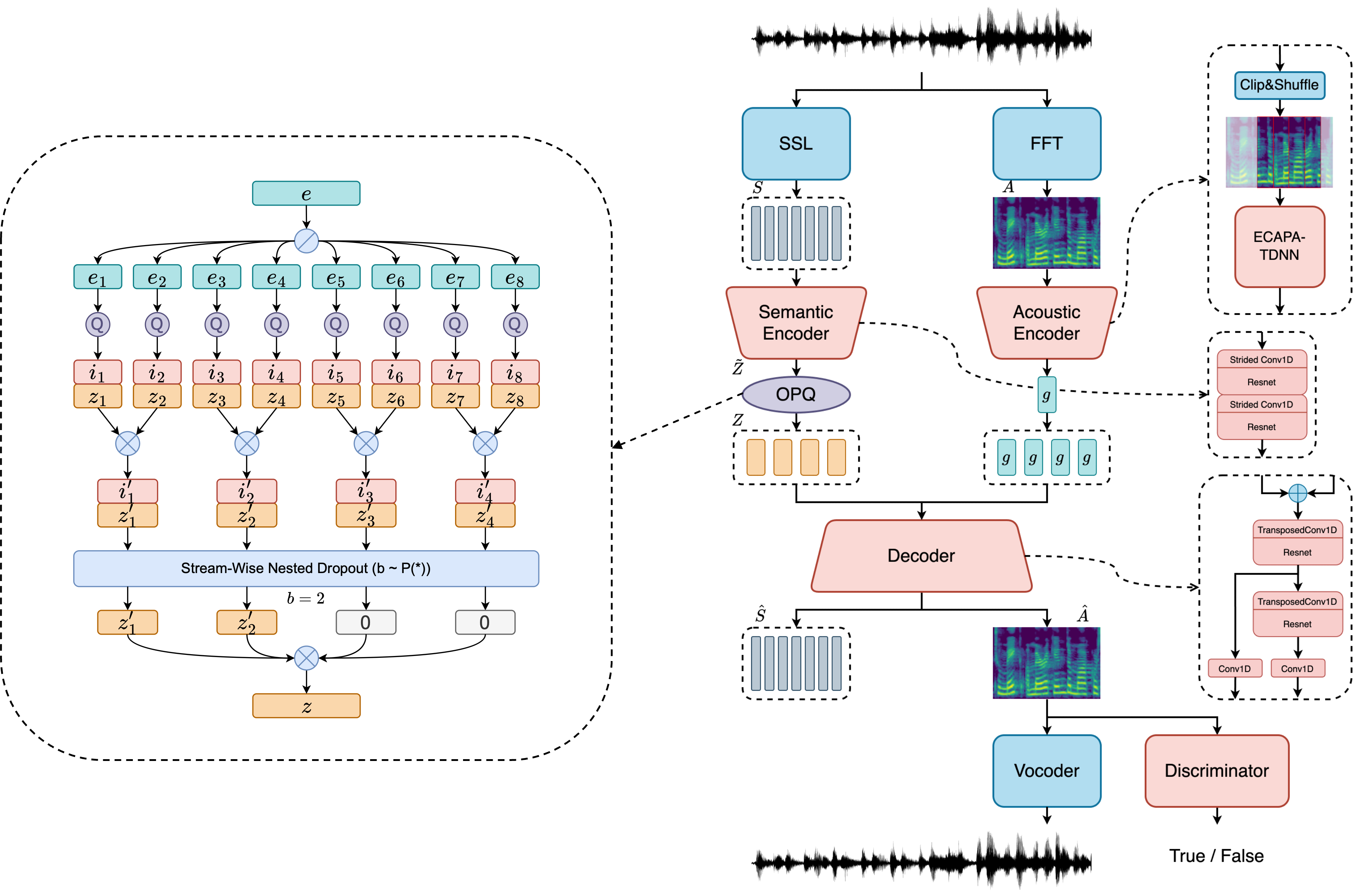
Com o Socodec, você pode compactar áudio em códigos discretos em uma taxa de bits ultra baixa 0,47 kbps e uma curta margem de quadro de 120ms .
? Ele pode ser usado como substituição do CODEC ou outros codecs de vários fluxo para aplicativos de modelagem de linguagem de fala.
O ponto de verificação lançado só suporta chinês agora. O treinamento da versão multilíngue está em andamento.
Clone o repositório e instale dependências:
git clone https://github.com/hhguo/SoCodec
cd SoCodec
mkdir ckpts && cd ckpts
wget https://huggingface.co/TencentGameMate/chinese-hubert-large/resolve/main/chinese-hubert-large-fairseq-ckpt.pt
wget https://huggingface.co/hhguo/SoCodec/resolve/main/socodec_16384x4_120ms_16khz_chinese.safetensors
wget https://huggingface.co/hhguo/SoCodec/resolve/main/mel_vocoder_80dim_10ms_16khz.safetensors # For analysis-synthesis
python example.py -i ground_truth.wav -o synthesis.wav
# For speech analysis
python example.py -i ground_truth.wav -o features.pt
# For token-to-audio synthesis
python example.py -i features.pt -o synthesis.wavFornecemos os modelos pré -rastreados para abraçar as coleções de rosto.
| Nome do modelo | Mudança de quadro | Tamanho do livro de código | Número de fluxos | Conjunto de dados |
|---|---|---|---|---|
| SOCODEC_16384X4_120MS_16KHZ_CHINESE | 120ms | 16384 | 4 | Wenetspeech4tts |
Também fornecemos aos vocoders pré -treinados para converter o espectrograma MEL do Socodec para a forma de onda.
| Nome do modelo | Mudança de quadro | Mel Bins | fmax | Taxa de amostragem | Conjunto de dados |
|---|---|---|---|---|---|
| MEL_VOCODER_80DIM_10MS_16KHZ | 16 kHz | 80 | 8000 | 160 | Wenetspeech4tts |


