SoCodec
1.0.0
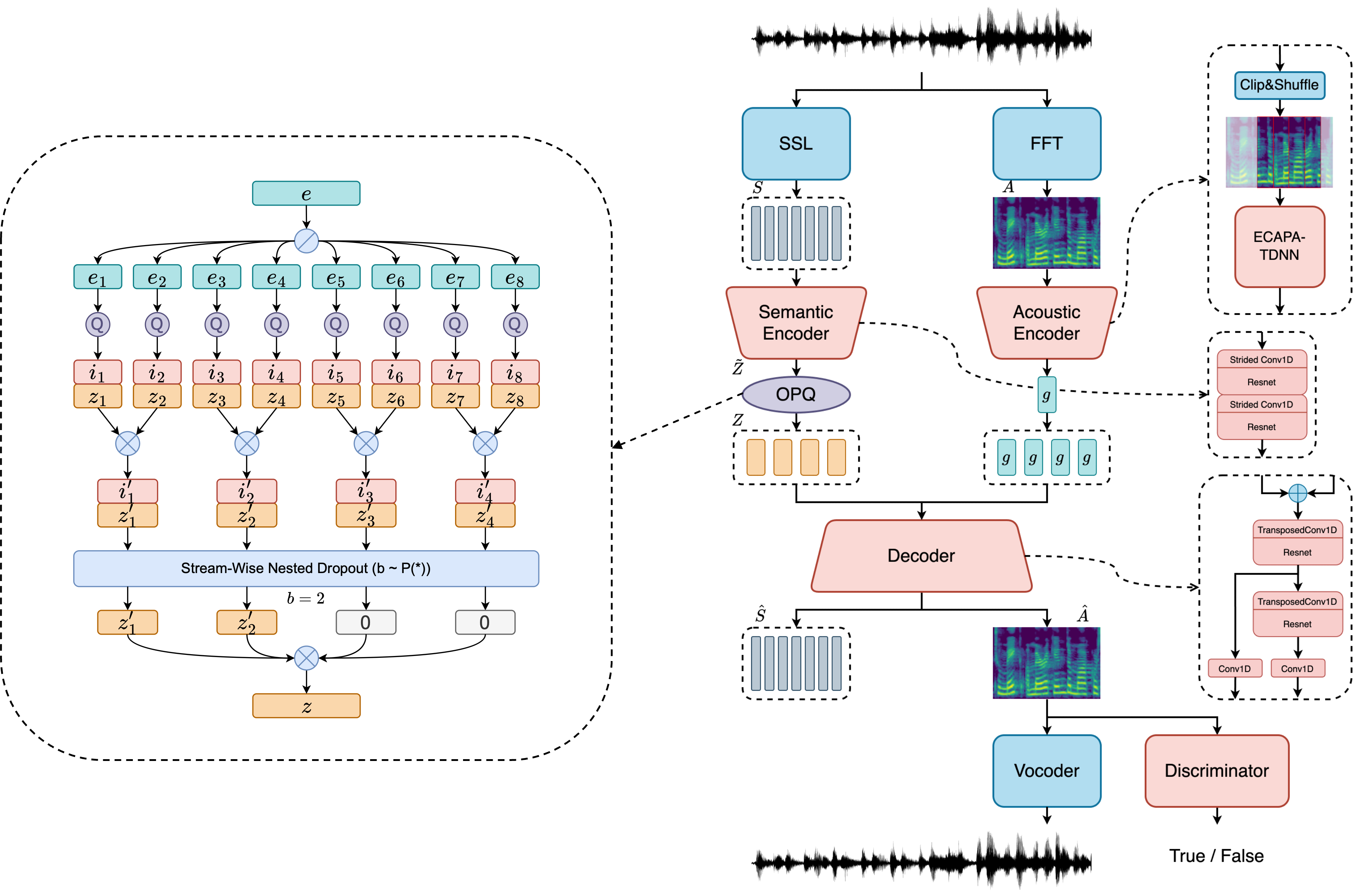
Dieses Repository enthält Inferenzskripte für SOCODEC, einen ultra-niedrigen Sprachcodec, der sich Sprachmodellen widmet, der in dem Papier mit dem Titel SoCodec vorgestellt wurde: eine semantisch angeordnete Multi-Stream-Sprachcodec für eine effiziente Sprachmodellbasis-Synthese .
Papier
? Demo -Site
⚙ Modellgewichte
Mit SOCODEC können Sie Audio in diskreten Codes in einem ultra niedrigen Bitrate von 0,47 kbit / s und einem kurzen 120 -ms -Frameshift komprimieren.
? Es kann als Drop-In-Ersatz für CCODEC oder andere Multi-Stream-Codecs für Sprachsprachenmodellierungsanwendungen verwendet werden.
Der freigegebene Checkpoint unterstützt jetzt nur Chinesen . Das Training der mehrsprachigen Version ist im Gange.
Klonen Sie das Repository und installieren Sie Abhängigkeiten:
git clone https://github.com/hhguo/SoCodec
cd SoCodec
mkdir ckpts && cd ckpts
wget https://huggingface.co/TencentGameMate/chinese-hubert-large/resolve/main/chinese-hubert-large-fairseq-ckpt.pt
wget https://huggingface.co/hhguo/SoCodec/resolve/main/socodec_16384x4_120ms_16khz_chinese.safetensors
wget https://huggingface.co/hhguo/SoCodec/resolve/main/mel_vocoder_80dim_10ms_16khz.safetensors # For analysis-synthesis
python example.py -i ground_truth.wav -o synthesis.wav
# For speech analysis
python example.py -i ground_truth.wav -o features.pt
# For token-to-audio synthesis
python example.py -i features.pt -o synthesis.wavWir stellen die vorbereiteten Modelle für umarmende Gesichtssammlungen zur Verfügung.
| Modellname | Rahmenverschiebung | Codebuchgröße | Anzahl der Streams | Datensatz |
|---|---|---|---|---|
| SOCODEC_16384X4_120MS_16KHZ_CHINESES | 120 ms | 16384 | 4 | Wenetspeech4tts |
Wir stellen auch die vorbereiteten Vocoder zur Verfügung, um das MEL -Spektrogramm aus SoCodec in die Wellenform umzuwandeln.
| Modellname | Rahmenverschiebung | Mel Mülleimer | fmax | Upsampling -Verhältnis | Datensatz |
|---|---|---|---|---|---|
| mel_vocoder_80dim_10ms_16kHz | 16 kHz | 80 | 8000 | 160 | Wenetspeech4tts |


