SoCodec
1.0.0
يحتوي هذا المستودع على البرامج النصية للاستدلال لـ SOCODEC ، وهو برنامج ترميز خطاب في النطاقات منخفضة النطق ، مخصص لنماذج لغة الكلام ، التي تم تقديمها في الورقة بعنوان SOCODEC: ترميز الكلام متعدد الكلام من الدرجة الدلالية لتوليف النص إلى النموذج القائم على اللغة الكفاءة .
ورق
؟ الموقع التجريبي
⚙ الأوزان النموذجية
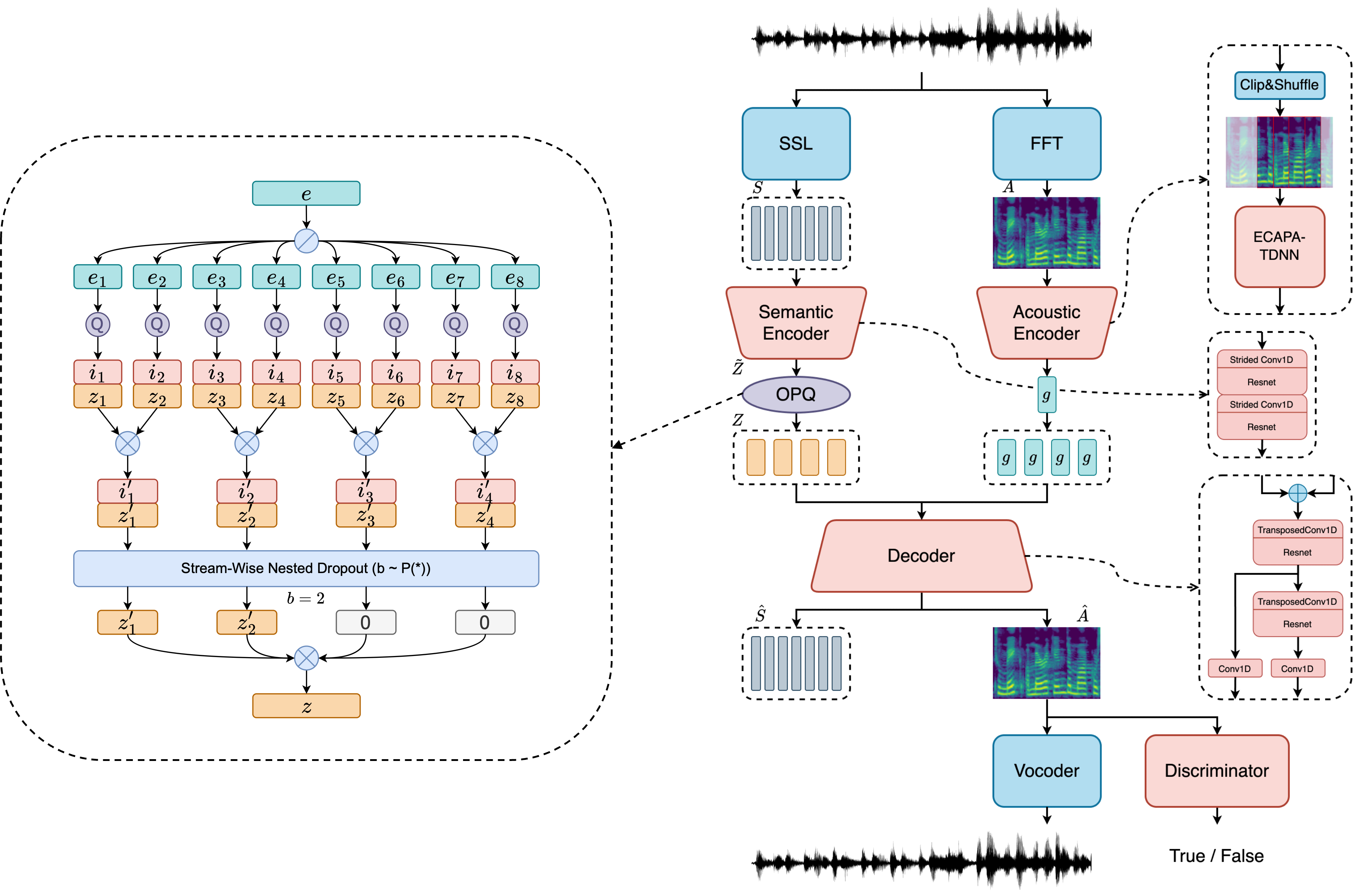
مع SOCODEC ، يمكنك ضغط الصوت في رموز منفصلة عند معدل بتات منخفضة 0.47 كيلو بايت في الثانية و 120 مللي ثانية .
؟ يمكن استخدامه كبديل إسقاط لـ ENCODEC أو برامج الترميز المتعددة البث الأخرى لتطبيقات نمذجة لغة الكلام.
نقطة التفتيش التي تم إصدارها تدعم الصينية فقط الآن. تدريب النسخة متعددة اللغات قيد التقدم.
استنساخ المستودع وتثبيت التبعيات:
git clone https://github.com/hhguo/SoCodec
cd SoCodec
mkdir ckpts && cd ckpts
wget https://huggingface.co/TencentGameMate/chinese-hubert-large/resolve/main/chinese-hubert-large-fairseq-ckpt.pt
wget https://huggingface.co/hhguo/SoCodec/resolve/main/socodec_16384x4_120ms_16khz_chinese.safetensors
wget https://huggingface.co/hhguo/SoCodec/resolve/main/mel_vocoder_80dim_10ms_16khz.safetensors # For analysis-synthesis
python example.py -i ground_truth.wav -o synthesis.wav
# For speech analysis
python example.py -i ground_truth.wav -o features.pt
# For token-to-audio synthesis
python example.py -i features.pt -o synthesis.wavنحن نقدم النماذج المسبقة على معانقة مجموعات الوجه.
| اسم النموذج | تحول الإطار | حجم دفتر الكود | عدد التدفقات | مجموعة البيانات |
|---|---|---|---|---|
| SOCODEC_16384X4_120MS_16KHZ_CHINESE | 120ms | 16384 | 4 | wenetspech4tts |
نحن نقدم أيضًا صوتيات مسبق لتحويل طيف MEL من SOCODEC إلى شكل الموجة.
| اسم النموذج | تحول الإطار | Mel Bins | fmax | نسبة upsampling | مجموعة البيانات |
|---|---|---|---|---|---|
| MEL_VOCODER_80DIM_10MS_16KHz | 16 كيلو هرتز | 80 | 8000 | 160 | wenetspech4tts |


