SoCodec
1.0.0
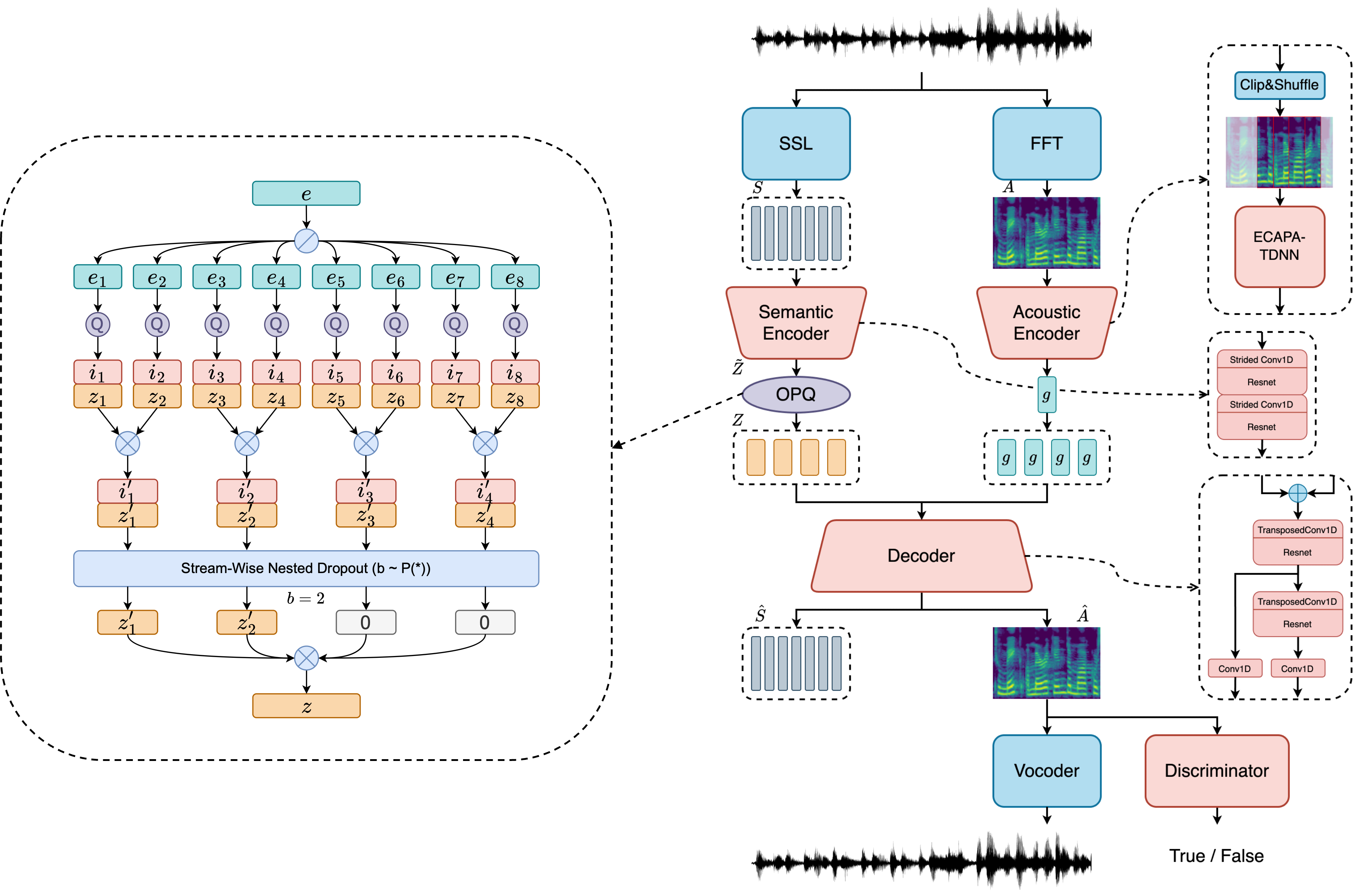
Repositori ini berisi skrip inferensi untuk SOCODEC, codec ucapan ultra-rendah-bitrat, yang didedikasikan untuk model bahasa ucapan, yang diperkenalkan dalam makalah berjudul Socodec: Codec Pidato Multi-Stream yang dipesan semantik untuk sintesis teks-ke-speech berbasis bahasa yang efisien .
Kertas
? Situs demo
⚙ Bobot model
Dengan SOCODEC, Anda dapat mengompres audio ke dalam kode diskrit pada bitrate sangat rendah 0,47 kbps dan frameshift 120ms pendek .
? Ini dapat digunakan sebagai pengganti drop-in untuk EncodeC atau codec multi-stream lainnya untuk aplikasi pemodelan bahasa bicara.
Pos pemeriksaan yang dirilis hanya mendukung Cina sekarang. Pelatihan versi multi-bahasa sedang berlangsung.
Kloning repositori dan instal dependensi:
git clone https://github.com/hhguo/SoCodec
cd SoCodec
mkdir ckpts && cd ckpts
wget https://huggingface.co/TencentGameMate/chinese-hubert-large/resolve/main/chinese-hubert-large-fairseq-ckpt.pt
wget https://huggingface.co/hhguo/SoCodec/resolve/main/socodec_16384x4_120ms_16khz_chinese.safetensors
wget https://huggingface.co/hhguo/SoCodec/resolve/main/mel_vocoder_80dim_10ms_16khz.safetensors # For analysis-synthesis
python example.py -i ground_truth.wav -o synthesis.wav
# For speech analysis
python example.py -i ground_truth.wav -o features.pt
# For token-to-audio synthesis
python example.py -i features.pt -o synthesis.wavKami menyediakan model pretrained pada koleksi wajah memeluk.
| Nama model | Shift bingkai | Ukuran CodeBook | Jumlah aliran | Dataset |
|---|---|---|---|---|
| SOCODEC_16384X4_120MS_16KHZ_CHINESE | 120ms | 16384 | 4 | Wenetspeech4tts |
Kami juga menyediakan vokoder pretrained untuk mengonversi spektrogram MEL dari SOCODEC ke bentuk gelombang.
| Nama model | Shift bingkai | Mel Bins | fmax | Rasio Upsampling | Dataset |
|---|---|---|---|---|---|
| Mel_vocoder_80dim_10ms_16khz | 16 kHz | 80 | 8000 | 160 | Wenetspeech4tts |


