BlahST
Multilingual BlahST
O peech-to ton Blah permite que você tenha um texto de entrada de bla (h) st da Speech no Linux, com atalhos de teclado e sussurro.cpp. Inicie seu microfone e execute o reconhecimento de fala multilíngue de alta qualidade. Estendido com LLMs locais, torna -se uma ferramenta potente para conversar com o seu computador Linux.
Blahst é provavelmente a ferramenta de entrada de fala para texto mais enxuta para Linux, sentada em cima do sussurro.cpp.
wsiml dedicadoUsando ferramentas de linha de comando com baixo resistência e compensação, a entrada de texto falada acontece muito rápido. Aqui está um vídeo de demonstração (por favor, somente o áudio) com alguns recursos locais do LLM (assistente de AI, tradutor, agendamento, guia da CLI em estágio de teste):
No vídeo acima, o áudio começa com o sistema que anula a screencasting (minha extensão Gnome "volúvel" fala em voz alta todas as notificações da área de trabalho do Gnome), seguidas de várias voltas de entrada/reconhecimento de fala. Demonstrado no final é uma das "funções de IA" de concurso que usa o texto transcrito por Blahst (sussurro.cpp), formata -o em um prompt de LLM e o envia para um LLM multilíngue local (llama.cpp ou llamafile) que retorna a tradução chinesa como texto e também fala usando um neural. Orquestrar isso na linha de comando com os executáveis enxuta deixa o sistema surpreendentemente ágil (no vídeo, você pode ver que o PC mal quebra qualquer suor - as temperaturas permanecem baixas.)
O vídeo acima (somente por favor) demonstra o uso de Blooper, modificado do WSI para transcrever em um loop, até que o usuário encerre a entrada de fala com uma pausa mais longa (~ 3seg conforme predefinido). Com o uso do XDOTOOL (ou YDOTOOL para usuários de Wayland), o texto é colado automaticamente em qualquer pausa (ou na interrupção da tecla de atalho). Para o vídeo acima, o discurso é gerado com uma voz sintético e coletado pelo microfone. Isso me permite editar o texto simultaneamente (multitarefa, não tente isso em casa :). No final, o ícone do microfone de barra superior deve desaparecer, indicando a saída do programa. Isso não acontece no vídeo porque o utilitário Screencast também tem uma reclamação no ícone.
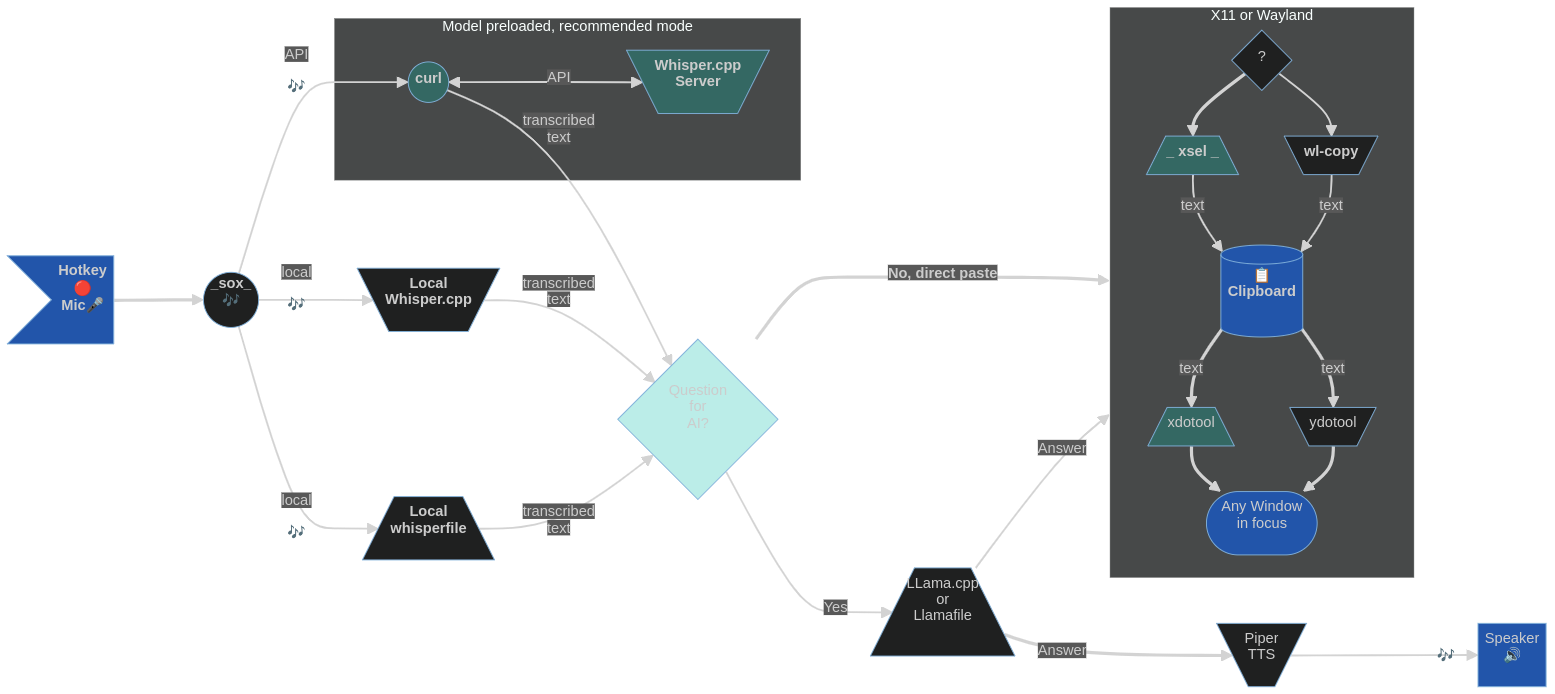
A idéia com Blahst é ser o software livre de interface do usuário equivalente a um ataque mongol; A explosão curta e poderosa da ação da CPU/GPU e, em seguida, desapareceu completamente, com apenas traços textuais na área de transferência e na paz relativa da área de trabalho. Basta usar um par de teclas de atalho para iniciar e parar de gravar no microfone e enviar o discurso gravado para sussurrar.cpp [servidor] que despeja o texto transcrito para a área de transferência (a menos que você o passe por um LLM local antes disso). Uma abordagem universal que deve funcionar na maioria dos ambientes e distribuições do Linux Desktop.
O trabalho é feito por um dos scripts:
O reconhecimento de fala é realizado pelo Whisper.cpp, que deve ser pré -compilado no seu sistema Linux ou disponível como uma instância do servidor na sua LAN ou localhost. Alternindively, você pode optar por simplesmente baixar e usar um executável portátil (com um modelo de sussurro incorporado) WhisperFile, agora parte do repositório do Llamafile.
Quando a entrada da fala é iniciada com uma tecla de atalho, um indicador de microfone aparece na barra superior (pelo menos no GNOME) e é mostrado durante a duração da gravação (pode ser interrompido com outra tecla de atalho). O desaparecimento do ícone do microfone da barra superior indica a conclusão e o texto transcrito pode ser colado na área de transferência. Em sistemas mais lentos, pode haver um pequeno atraso após o ícone do microfone desaparecer e antes que o texto atinja a prancha devido ao tempo de transcrição mais longo. No meu computador, através da API do servidor Whisper.CPP, é menos de 150 ms (300 ms com Whisper.cpp local) para um parágrafo médio de texto falado.
Para operação somente para o teclado, com o CTRL+V padrão, por exemplo, a área de transferência padrão será usada em X11 e Wayland ( wsi ou wsiml ), enquanto wsi -p (ou wsiml -p ) usa a venda e o texto primário é colado com o botão do meio do mouse do meio). Para a pasta à esquerda, a gravação de fala pode ser relegada às teclas de calor acionadas com a mão direita. ** Por exemplo, eu configurei as teclas não utilizadas "+" (comece a gravar) e "inserir" (parar de gravar) no teclado numérico.
install-wsi lida com a maioria deles).Isenção de responsabilidade: o autor não recebe crédito nem assume nenhuma responsabilidade por qualquer resultado que possa ou não resultar da interação com o conteúdo deste documento. As ações e automações propostas (por exemplo, locais de instalação etc.) são apenas sugestões e são baseadas na escolha e opinião do autor. Como eles podem não se encaixar no sabor ou na situação específica de todos, por favor, ajuste conforme necessário.
Em uma pasta de sua escolha, clone o repositório Blahst e escolha um método de instalação abaixo:
git clone https://github.com/QuantiusBenignus/BlahST.git
cd ./BlahST
(Assumindo que o sussurro.cpp está instalado e o executável "principal" compilado com 'make' no sussurro clonado.cpp repo. Veja a seção Pré -requisitos)
cd $HOME/.local/bin; chmod +x wsi wsiAI wsiml
$HOME/.local/bin/ (parte do seu $ path) com ln -s /full/path/to/whisper.cpp/main $HOME/.local/bin/transcribe
Se a transcrição não estiver no seu $ PATH, edite a chamada no WSI para incluir o caminho absoluto ou adicione sua localização à variável $ PATH. Caso contrário, o script falhará. Se você preferir não compilar Whisper.cpp, ou além disso, faça o download e defina o sinalizador executável de um WhisperFile adequado, por exemplo:
cd $HOME/.local/bin
wget https://huggingface.co/Mozilla/whisperfile/resolve/main/whisper-tiny.en.llamafile
chmod +x whisper-tiny.en.llamafile
Dentro do script wsi , wsiAI , wsiml ou blooper , perto do início, há uma seção claramente marcada, chamada "Bloco de configuração do usuário" , onde todas as variáveis configuráveis pelo usuário foram coletadas. A maioria pode ser deixada como é, mas as importantes são a localização dos arquivos de modelo (Whisper, LLM, TTS) que você gostaria de usar durante a transcrição (ou o número IP e da porta para o servidor Whisper.cpp). Se estiver usando um WhisperFile, defina a variável WhisperFile como o nome do arquivo do WhisperFile executável baixado anteriormente, ou seja, WHISPERFILE=whisper-tiny.en.llamafile (deve estar no caminho $).
Para iniciar e interromper a entrada da fala, para instalação manual e automática
/home/yourusername/.local/bin/wsi -p para usar o botão do mouse do meio ou altere -o para .../wsi para usar a área de transferência.wsi acima pelo wsiml e, se estiver usando um shisperfile, adicione a bandeira -w , ou seja, /home/yourusername/.local/bin/wsi -w ). Finalmente, para provar as funções do LLM, substitua wsi por wsiAI .O script do orquestrador possui um filtro de detecção de silêncio na chamada para Sox (REC) e parou de gravar (na melhor das hipóteses) em 2 segundos de silêncio. Além disso, se não se quiser esperar ou tiver problemas com o limite de detecção de silêncio:
Para aqueles que desejam ser capazes de interromper a gravação manualmente com uma combinação de chave, no espírito de grandes hacks, usaremos os recursos internos do sistema:
pkill --signal 2 recTão simples. Apenas certifique-se de que a nova ligação de chaves ainda não tenha sido configurada para outra coisa. Agora, quando o script está gravando o discurso, ele pode ser interrompido com a nova combinação de chaves e a transcrição começará imediatamente.
/home/yourusername/.local/bin/wsi -p ou .../wsi para usar a prancha.wsi acima pelo wsiml e, se estiver usando um shisperfile, adicione a bandeira -w , ou seja, /home/yourusername/.local/bin/wsi -w ). Finalmente, para provar as funções do LLM, substitua wsi por wsiAI .pkill --signal 2 rec ./home/yourusername/.local/bin/wsi ou .../wsi -pwsi acima pelo wsiml e, se estiver usando um shisperfile, adicione a bandeira -w , ou seja, /home/yourusername/.local/bin/wsi -w ). Finalmente, para provar as funções do LLM, substitua wsi por wsiAI .pkill --signal 2 rec .Observe que pode haver pequenas variações nas etapas acima, dependendo da versão instalada no seu sistema. Para muitos outros ambientes, como Mate, Cinnamon, LXQT, Deepin , etc. As etapas devem ser um pouco semelhantes aos exemplos acima. Consulte a documentação para o seu ambiente de desktop de seus sistemas.
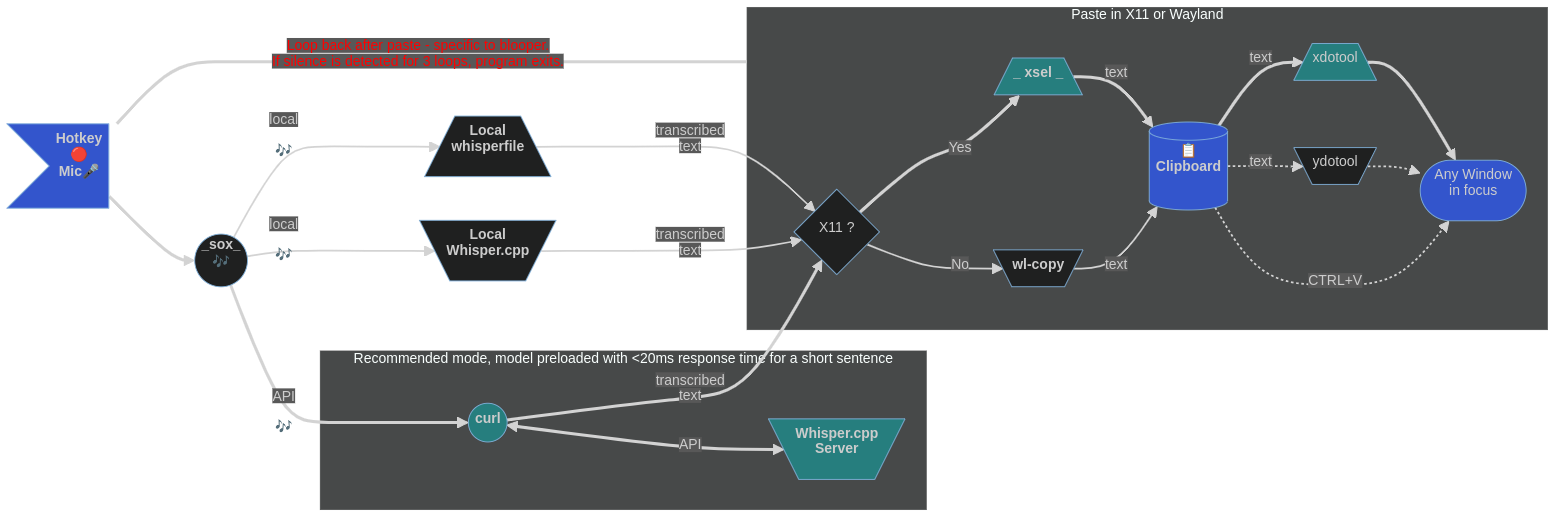
No pressionamento de uma combinação de teclas de atalho, o script wsi -p gravará a fala (parada com uma tecla de atalho ou por detecção de silêncio), use uma cópia local do sussurro.cpp e envie o texto transcrito para a seleção primária sob, X11 ou Wayland. Então tudo o que se tem que fazer é colá -lo com o botão do mouse do meio em qualquer lugar que desejar. (Para as pessoas que seguram o rato com a mão direita, a fala que registra teclas de atalho para a mão esquerda faria sentido.)
Se estiver usando wsi sem sinalizadores (as abordagens podem coexistir, basta configurar diferentes conjuntos de teclas de atalho), o texto transcrito é enviado para a área de transferência (não a seleção primária) em X11 ou Wayland. Em seguida, a coleta acontece com o CTRL+V ( CTRL+SHIFT+V para o terminal GNOME) ou as teclas de SHIFT+INSert como de costume. (Para a maioria das pessoas, as teclas de atalho da mão direita funcionariam bem.)
Se transcrever pela rede com wsi -n (selecionado com uma tecla de atalho própria), o script tentará enviar o áudio gravado para um servidor Whisper.cpp definido corretamente (na LAN ou localhost ). Em seguida, ele coletará a resposta textual e a formará para colar com as teclas CTRL+V ( CTRL+SHIFT+V para Terminal GNOME) ou SHIFT+INSert (para colar com o botão do mouse médio usar wsi -n -p ).
Se estiver usando um sussurro em vez de, ou além de um sussurro compilado.cpp, invocar com wsi -w ... e o script usará o predefinido executável portátil com o modelo de escolha de sussurro incorporado.
Para usuários multilíngues, além dos recursos do WSI, wsiml fornece a capacidade de especificar um idioma, por exemplo -l fr e a opção de traduzir para o inglês com -t . O usuário pode, em princípio, atribuir várias teclas de hot aos vários idiomas de que transcrevem ou traduzem. Por exemplo, duas teclas de atalho adicionais podem ser definidas, uma para transcrição e outra para traduzir do francês, atribuindo os comandos wsiml -l fr e wsiml -l fr -t correspondentemente.
Experimental: os usuários podem usar o Blooper de Scripts fornecido para obter entrada automática contínua de fala para texto (não há necessidade de pressionar Ctrl+V ou clicar no botão do mouse do meio.) Isso é demonstrado no segundo vídeo acima. Observe que a área de transferência é usada por padrão, o texto será ampliado automaticamente sob o teclado Carret, mas, em princípio, a seleção primária pode ser configurada, um clique do botão do mouse do meio será simulado e o texto colado na posição atual do ponteiro do mouse no (um pouco arbitrar) o tempo está disponível. Observe que isso se baseia na detecção de silêncio, que depende do seu ambiente físico. Em ambientes barulhentos, use a chave quente para parar de gravar.
Não podemos aumentar o limiar arbitrariamente porque, se alguém diminuir consistentemente sua voz (Fadeout) no final da fala, ela pode ser cortada se o limiar for alto. Abaixe nesse caso para alguns %.
É melhor tentar tornar a fala distinguível do ruído por amplitude (fale claramente, próximo ao microfone), minimizando o ruído externo (localização protegida do microfone, hardware de cancelamento de ruído etc.) com um bom nível de sinal de fala, o limiar pode ser mais eficaz, uma vez que SNR (discurso-noise :-) é efetivamente aumentado.
Depois que o discurso for capturado, ele será passado para transcribe (sussurro.cpp) para reconhecimento de fala. Isso acontecerá mais rápido que o tempo real (especialmente com uma CPU rápida ou se o seu sussurro.cpp a instalação usar CUDA). Pode -se ajustar o número de threads de processamento usados adicionando -tn aos parâmetros da linha de comando de transcrição (por favor, consulte a documentação do sussurro.cpp). O script analisará o texto para remover artefatos que não são de fala, formate-o e o enviarão para a seleção primária (quadro de transferência) usando as ferramentas X11 ou Wayland.
Em princípio, o sussurro (sussurro.cpp) é multilíngue e, com o arquivo de modelo correto, este aplicativo produzirá texto UTF-8 transcrito no idioma correto. O script wsiml é dedicado ao uso multilingual e, com ele, o usuário pode escolher o idioma para entrada de fala (usando o sinalizador -l LC onde LC é o código do idioma) e também pode traduzir o discurso no idioma de entrada escolhido para o inglês com o sinalizador -t . O usuário pode atribuir várias teclas de atalho aos vários idiomas dos quais desejam transcrever ou traduzir. Por exemplo, duas teclas de atalho adicionais podem ser definidas, uma para transcrição e outra para traduzir do francês, atribuindo os comandos wsiml -l fr e wsiml -l fr -t correspondentemente.
Observe que, ao usar o modo de servidor, agora você tem 2 opções. Você pode ter o servidor Whisper.cpp pré -compilado ou o WhisperFile baixado (no modo servidor) ouça no host e número da porta prematurados. O script do orquestrador se aproxima deles da mesma maneira.
A transcrição de fala para texto é uma tarefa intensiva em memória e CPU e armazenamento rápido para acesso a leitura e gravação só pode ajudar. É por isso que o WSI armazena arquivos temporários e de recursos na memória, para velocidade e para reduzir o SSD/HDD "Retinging": TEMPD='/dev/shm' . Esse ponto de montagem do tipo "TMPFS" é criado na RAM (vamos supor que você tenha o suficiente, digamos, pelo menos 8 GB) e é disponibilizado pelo kernel para aplicativos de espaço de usuário. Quando o computador é desligado, ele é eliminado automaticamente, o que é bom, pois não precisamos dos arquivos intermediários. De fato, para alguns tipos de aplicações (olhando para você Electron), seria benéfico (IMHO) ter o ponto de montagem em todo o sistema /TMP também mantido na RAM. Mover /TMP para RAM pode acelerar um pouco a inicialização do aplicativo. Uma aceleração de boas -vindas para qualquer aplicativo Electron. Na sua forma mais simples, essa transição é fácil, basta executar:
echo "tmpfs /tmp tmpfs rw,nosuid,nodev" | sudo tee -a /etc/fstab e reinicie seu computador Linux. Pelas razões acima mencionadas, especialmente se o HDD for o principal mídia de armazenamento, também é possível mover os arquivos do modelo ASR necessários para o sussurro.cpp no mesmo local (/dev/shm). Estes são arquivos grandes, que podem ser transferidos para este local no início de uma sessão de terminal (ou na inicialização do sistema). Isso pode ser feito usando seu arquivo .profile colocando algo assim nele:
([ -f /dev/shm/ggml-base.en.bin ] || cp /path/to/your/local/whisper.cpp/models/ggml* /dev/shm/)


