BlahST
Multilingual BlahST
Mit bla s peech-to- t- Ext können Sie einen BLA (H) ST Eingabtext von Sprache unter Linux mit Tastaturverknüpfungen und flüstert.cpp haben. Starten Sie Ihr Mikrofon und führen Sie eine qualitativ hochwertige, mehrsprachige Spracherkennung offline durch. Mit lokalen LLMs wird es zu einem wirksamen Werkzeug, um sich mit Ihrem Linux -Computer zu unterhalten.
Blahst ist wahrscheinlich das schlankste flüsterbasierte Sprach-zu-Text-Eingangswerkzeug für Linux und sitzt auf flüster.cpp.
wsiml -Skript zu übersetzenUnter Verwendung von niedrigressourcen, optimierten Befehlszeilen-Tools erfolgt der gesprochene Texteingang sehr schnell. Hier ist ein Demonstrationsvideo (bitte den Audio) mit einigen lokalen LLM -Funktionen (AI -Assistent, Übersetzer, Scheduller, CLI -Handbuch in der Testphase):
Im obigen Video beginnt das Audio damit, dass das System die Screencasting angeht (meine GNOME -Erweiterung "Voluble" spricht alle GNOME -Desktop -Benachrichtigungen), gefolgt von mehreren Wendungen der Spracheingabe/Erkennung. Am Ende wird eine der up -Comming -"-Ai -Funktionen" gezeigt, die den von Blahst (flüsterlich.cpp) transkribierten Text verwendet, ihn in eine LLM -Eingabeaufforderung formatiert und sie an eine lokale mehrsprachige LLM (llama.cpp oder llamafile) sendet, die die chinesische Übersetzung zurückgibt und auch spricht. Wenn Sie dies aus der Befehlszeile mit mageren ausführbaren Funktionen orchestrieren, bleibt das System überraschend bissig (aus dem Video können Sie sehen, dass der PC kaum Schweiß bricht - die Temperaturen bleiben niedrig.)
Das obige Video (BITTE BITTE) zeigt die Verwendung von Blooper, die von WSI geändert wurde, um sie in einer Schleife zu transkribieren, bis der Benutzer die Spracheingabe mit einer längeren Pause (~ 3Sec als Voreinstellung) beendet. Mit der Verwendung von XDOTOOL (oder YDOTOOL für Wayland -Benutzer) wird der Text automatisch in jeder Pause (oder bei der Hotkey -Interupion) eingefügt. Für das obige Video wird die Sprache mit einer synthetischen Stimme erzeugt und vom Mikrofon gesammelt. Dies ermöglicht es mir, den Text gleichzeitig zu bearbeiten (Multitasker, versuchen Sie dies nicht zu Hause :). Am Ende sollte das Top-Bar-Mikrofon-Symbol verschwinden, was auf das Programmausgang hinweist. Es geschieht nicht im Video, weil das Screencast -Dienstprogramm auch einen Anspruch auf das Symbol hat.
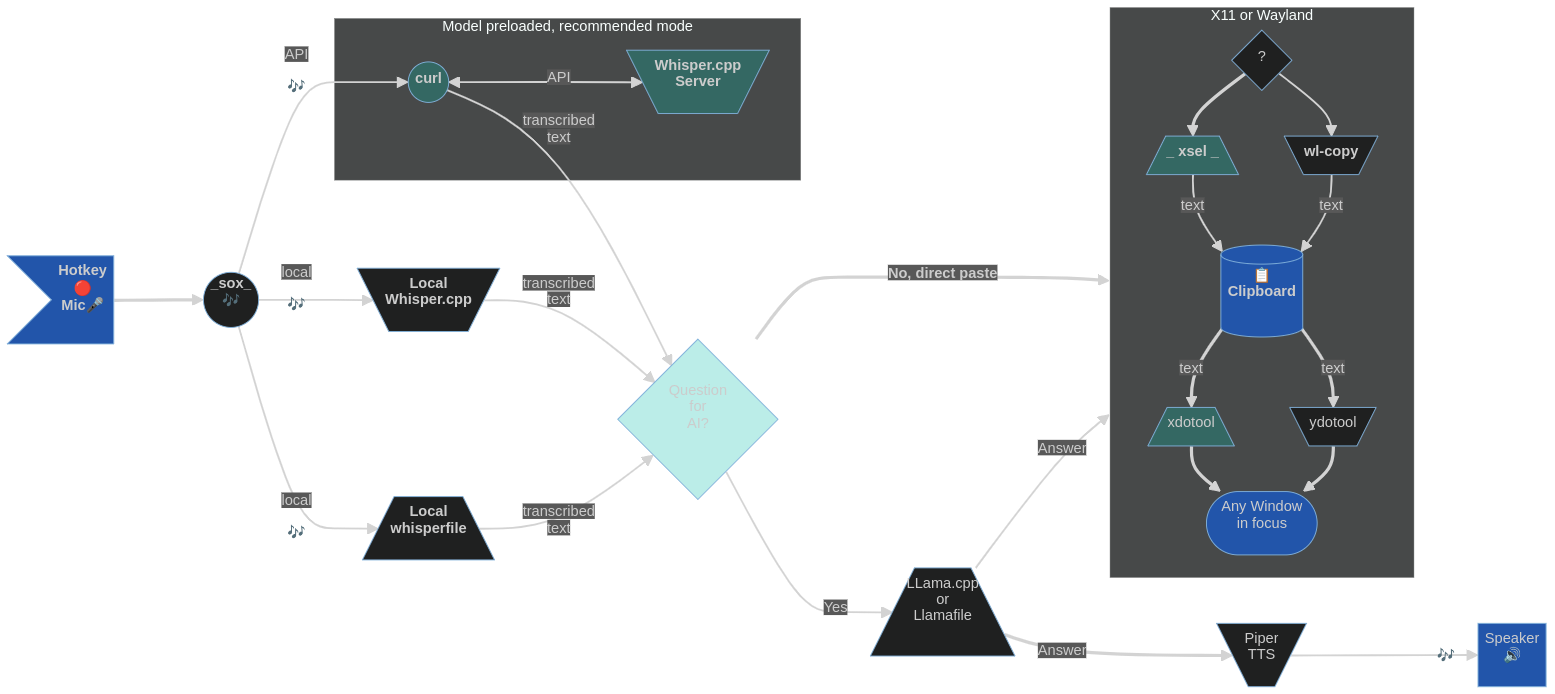
Die Idee mit Blahst ist, das ui-freie Software-Äquivalent eines Mongolen-Raids zu sein. Kurzer und kraftvoller Ausbruch der CPU/GPU -Aktion und dann ist es vollständig verschwunden, mit nur Textspuren in der Zwischenablage und relativen Desktop -Frieden. Verwenden Sie einfach ein Paar Hotkeys, um die Aufzeichnung aus dem Mikrofon aus zu starten und zu stoppen, und senden Sie die aufgezeichnete Sprache an whisper.cpp [Server], mit dem transkribierte Text in die Zwischenablage abgelegt wird (es sei denn, Sie übergeben ihn vorher mit einem lokalen LLM). Ein universeller Ansatz, der in den meisten Linux -Desktop -Umgebungen und -verteilungen funktionieren sollte.
Die Arbeit erfolgt von einem der Skripte:
Die Spracherkennung wird von wihsper.cpp durchgeführt, das auf Ihrem Linux -System vorkompiliert werden muss oder als Serverinstanz auf Ihrem LAN oder Localhost verfügbar ist. Alternativly können Sie einfach eine tatsächlich tragbare ausführbare Datei herunterladen und verwenden (mit einem eingebetteten Flüstermodell) WhisperFile, das jetzt Teil des Lamafile -Repositorys ist.
Wenn die Spracheingabe mit einem Hotkey initiiert wird, erscheint in der oberen Balken (zumindest in GNOME) ein Mikrofonindikator und wird für die Dauer der Aufnahme angezeigt (kann mit einem anderen Hotkey unterbrochen werden). Das Verschwinden des Mikrofonsymbols aus der oberen Balken zeigt die Fertigstellung an und der transkribierte Text kann aus der Zwischenablage eingefügt werden. Bei langsameren Systemen kann es eine leichte Verzögerung geben, nachdem das Mikrofonsymbol verschwunden ist und bevor der Text aufgrund einer längeren Transkriptionszeit die Zwischenablage erreicht. Auf meinem Computer ist es über die API von Whisper.CPP Server -API weniger als 150 ms (300 ms mit lokalem Whisper.cpp) für einen durchschnittlichen Absatz des gesprochenen Textes.
Für den CTRL+V wird beispielsweise die Standard -Zwischenablage unter X11 und Wayland ( wsi oder wsiml ) verwendet, während wsi -p (oder wsiml -p ) die primäre Verkäufe verwendet und der Text mit der mittleren Maustaste eingefügt wird). Bei der linken Paste kann die Sprachaufzeichnung in Hotkeys mit der rechten Hand abgestuft werden. ** Zum Beispiel habe ich die nicht verwendeten Tasten "+" (Startaufzeichnung) und "Einfügen" (Stop -Aufnahme) auf der numerischen Tastatur eingerichtet.
install-wsi verarbeitet die meisten davon).Haftungsausschluss: Der Autor übernimmt weder Kredit oder übernimmt eine Verantwortung für ein Ergebnis, das sich aus der Interaktion mit dem Inhalt dieses Dokuments ergeben kann oder nicht. Die vorgeschlagenen Aktionen und Automatisierungen (z. B. Installationsorte usw.) sind lediglich Vorschläge und basieren auf der Wahl und der Meinung des Autors. Da sie möglicherweise nicht zum Geschmack oder der besonderen Situation aller passen, passen Sie bitte nach Bedarf an.
Klonen Sie in einem Ordner Ihrer Wahl das Blahst -Repository und wählen Sie dann eine Installationsmethode von unten aus:
git clone https://github.com/QuantiusBenignus/BlahST.git
cd ./BlahST
(Angenommen, Whisper.cpp ist installiert und die mit "make" im geklonte Whisper.
cd $HOME/.local/bin; chmod +x wsi wsiAI wsiml
$HOME/.local/bin/ (Teil Ihres $ paths) mit ln -s /full/path/to/whisper.cpp/main $HOME/.local/bin/transcribe
Wenn der Transkribe nicht in Ihrem $ -Path ist, bearbeiten Sie den Anruf in WSI , um den absoluten Pfad einzuschließen, oder fügen Sie seinen Speicherort zur $ -Path -Variablen hinzu. Andernfalls fällt das Skript fehl. Wenn Sie es vorziehen, weder flisper.cpp zu kompilieren oder zusätzlich dazu die ausführbare Flagge eines geeigneten WhisperFile herunterzuladen und festzulegen, zum Beispiel:
cd $HOME/.local/bin
wget https://huggingface.co/Mozilla/whisperfile/resolve/main/whisper-tiny.en.llamafile
chmod +x whisper-tiny.en.llamafile
In der wsi , wsiAI , wsiml oder blooper -Skript gibt es zu Beginn einen klar markierten Abschnitt mit dem Namen "Benutzerkonfigurationsblock" , in dem alle vom Benutzer konfigurierbaren Variablen gesammelt wurden. Die meisten können so übrig bleiben, aber die wichtigen sind die Position der Modelldateien (Whisper, LLM, TTS), die Sie während der Transkription (oder der IP- und Portnummer für den Flüstertemerschreiber) verwenden möchten. Wenn Sie eine WhisperFile verwenden, stellen Sie bitte die WhisperFile-Variable auf den Dateinamen des zuvor heruntergeladenen ausführbaren FlisperFile ein, dh WHISPERFILE=whisper-tiny.en.llamafile (muss im $ path sein).
So sowohl für die manuelle als auch für die automatische Installation zu starten und zu stoppen und zu stoppen
/home/yourusername/.local/bin/wsi -p für die Verwendung der mittleren Maustaste oder ändern Sie sie in .../wsi für die Verwendung der Zwischenablage.wsi oben durch wsiml und fügen Sie bei Verwendung einer WhisperFile das -w -Flag hinzu, dh /home/yourusername/.local/bin/wsi -w )). Um die LLM -Funktionen zu probieren, ersetzen Sie wsi durch wsiAI .Das Orchestrator -Skript verfügt über einen Stille -Erkennungsfilter im Anruf an SOX (REC) und würde die Aufzeichnung (im besten Fall) in 2 Sekunden Stille aufhören. Außerdem, wenn man nicht warten möchte oder Probleme mit der Stille -Erkennungsschwelle hat:
Für diejenigen, die in der Lage sein möchten, die Aufnahme mit einer Schlüsselkombination im Geiste großartiger Hacks manuell zu unterbinden, werden wir die integrierten Systeme in den Systemen verwenden:
pkill --signal 2 recSo einfach. Stellen Sie nur sicher, dass die neue Schlüsselbindung noch nicht für etwas anderes eingerichtet wurde. Wenn das Skript nun die Sprache aufzeichnet, kann es mit der neuen Schlüsselkombination gestoppt werden und Transkription startet sofort.
/home/yourusername/.local/bin/wsi -p oder .../wsi ein, um die Zwischenablage zu verwenden.wsi oben durch wsiml und fügen Sie bei Verwendung einer WhisperFile das -w -Flag hinzu, dh /home/yourusername/.local/bin/wsi -w )). Um die LLM -Funktionen zu probieren, ersetzen Sie wsi durch wsiAI .pkill --signal 2 rec durchgeführt werden./home/yourusername/.local/bin/wsi oder .../wsi -pwsi oben durch wsiml und fügen Sie bei Verwendung einer WhisperFile das -w -Flag hinzu, dh /home/yourusername/.local/bin/wsi -w )). Um die LLM -Funktionen zu probieren, ersetzen Sie wsi durch wsiAI .pkill --signal 2 rec durchgeführt werden.Bitte beachten Sie, dass in den obigen Schritten je nach der in Ihrem System installierten Version geringfügige Abweichungen vorliegen. Für viele andere Umgebungen wie Mate, Cinnamon, LXQT, Deepin usw. sollten die Schritte den obigen Beispielen etwas ähnlich sein. Bitte wenden Sie sich an die Dokumentation für Ihre Systemdesktop -Umgebung.
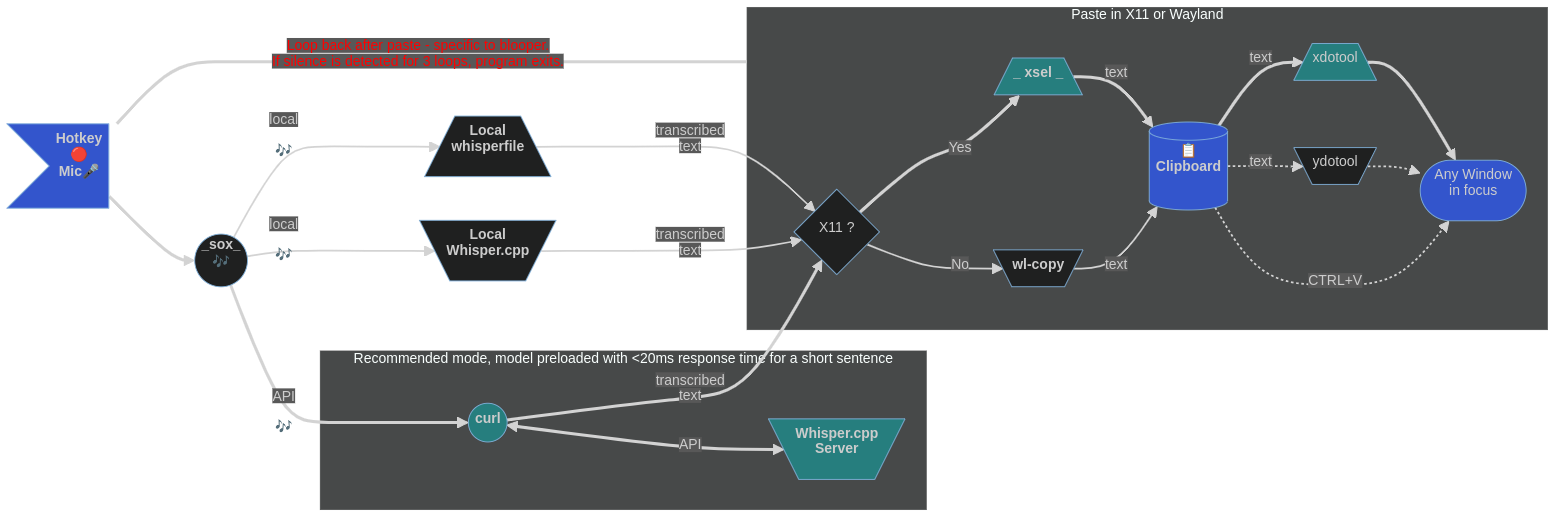
In der Presse einer Hotkey -Kombination wird das wsi -p -Skript die Sprache (mit einem Hotkey oder durch Stillekennung) aufzeichnen, eine lokale Kopie von wißsportlich.cpp verwenden und den transkribierten Text an die primäre Auswahl unter, entweder X11 oder Wayland senden. Dann muss man es nur mit der mittleren Maustaste einfügen, wo sie möchten. (Für Leute, die die Maus mit der rechten Hand halten, wäre die Sprecheraufzeichnung Hotkeys für die linke Hand Sinn.)
Wenn Sie wsi ohne Flags verwenden (die Ansätze können koexistieren, richten Sie einfach verschiedene Hotkeys ein), der transkribierte Text wird an die Zwischenablage (nicht die primäre Selektion) unter X11 oder Wayland gesendet. Anschließend erfolgt das Einfügen mit dem CTRL+V ( CTRL+SHIFT+V für GNOME -Anschluss) oder SHIFT+INSert . (Für die meisten Menschen würden die rechten Hotkeys gut funktionieren.)
Wenn das Netzwerk mit wsi -n (mit eigenem Hotkey ausgewählt) über das Netzwerk transkript wird, versucht das Skript, das aufgezeichnete Audio an einen laufenden, ordnungsgemäß ein Setzen von Whisper.cpp -Server (auf LAN oder localhost ) zu senden. Anschließend sammelt es die textliche Antwort und formatiert sie zum Einfügen mit dem CTRL+V ( CTRL+SHIFT+V für GNOME -Anschluss) oder SHIFT+INSert (zum Einfügen mit der mittleren Maustaste einfügen. Verwenden Sie stattdessen wsi -n -p ).
Wenn Sie eine WhisperFile anstelle von oder zusätzlich zu einem kompilierten flüstertem.cpp verwenden, rufen Sie mit wsi -w ... auf, und das Skript verwendet die tatsächlich tragbare voreingestellte voreingestellte Datei mit dem eingebetteten Flüstermodell der Wahl.
Für mehrsprachige Benutzer bietet wsiml zusätzlich zu den Funktionen von WSI die Möglichkeit, eine Sprache, z -l fr die Option, mit -t zu übersetzen. Der Benutzer kann im Prinzip den verschiedenen Sprachen, aus denen er transkriben oder übersetzt werden, mehrere Hotkeys zuweisen. Beispielsweise können zwei zusätzliche Hotkeys festgelegt werden, eine zum Transkriptieren und eine für die Übersetzung aus Französisch wsiml -l fr indem die Befehle wsiml -l fr -t zugewiesen werden.
Experimentell: Benutzer können den mitgelieferten Skript -Blooper für die kontinuierliche automatische Sprach-zu-Text-Eingabe verwenden (keine STRG+V Drücken oder Klicken Sie auf mittlere Maustaste). Dies wird im zweiten Video oben demonstriert. Bitte beachten Sie, dass die Zwischenablage standardmäßig verwendet wird. Der Text wird unter dem Tastatur -Carret autopastiert. Im Prinzip kann die primäre Auswahl stattdessen ein Klick mit mittlerer Maustaste simuliert und der Text an der aktuellen Position des Mauszeigers an der (etwas beliebigen) Zeit, die der Text verfügbar ist, eingefügt wird. Bitte beachten Sie, dass dies auf die Stilleerkennung abhängt, die von Ihrer physischen Umgebung abhängt. Verwenden Sie in lauten Umgebungen den heißen Schlüssel, um die Aufnahme zu stoppen.
Wir können den Schwellenwert nicht willkürlich erhöhen, denn wenn man am Ende der Sprache ihre Stimme (Fadeout) durchweg senkt, kann es abgeschnitten werden, wenn der Schwellenwert hoch ist. Senken Sie es in diesem Fall auf einige %.
Es ist am besten zu versuchen, die Sprache durch Amplitude (klar, in der Nähe des Mikrofons zu sprechen) unterscheidbar zu machen, während das externe Rauschen (geschützter Ort des Mikrofons, Hardware für Rauschunterdrückung usw.) mit einem guten Sprachsignalniveau minimiert wird, und der Schwellenwert kann dann effektiver sein, da SNR (Sprachverhältnis:-) Effektiv erhöht wird.
Nachdem die Rede erfasst wurde, wird sie zur Spracherkennung an transcribe (wiHSPER.CPP) übergeben. Dies geschieht schneller als in Echtzeit (insbesondere bei einer schnellen CPU oder wenn Ihre Installation von flüsterlich.cpp CUDA verwendet). Man kann die Anzahl der Verarbeitungs -Threads einstellen, die durch Hinzufügen von -tn zu den Befehlszeilenparametern von Transkriben verwendet werden (bitte siehe Whisper.cpp -Dokumentation). Das Skript wird dann den Text analysiert, um nicht-sprachliche Artefakte zu entfernen, ihn mithilfe von X11- oder Wayland-Tools an die primäre Auswahl (Zwischenablage) zu senden.
Im Prinzip ist Whisper (Whisper.cpp) mehrsprachig und mit der richtigen Modelldatei wird diese Anwendung in der richtigen Sprache den UTF-8-Text ausgibt. Das wsiml -Skript ist der Mehrlingsanwendung gewidmet, und damit kann der Benutzer die Sprache für die Spracheingabe auswählen (mit dem -l LC -Flag, in dem LC der Sprachcode ist) und die Sprache auch in der ausgewählten Eingabesprache mit dem -t -Flag in Englisch übersetzen kann. Der Benutzer kann den verschiedenen Sprachen mehrere Hotkeys zuweisen, aus denen er transkribieren oder übersetzt werden. Beispielsweise können zwei zusätzliche Hotkeys festgelegt werden, eine zum Transkriptieren und eine für die Übersetzung aus Französisch wsiml -l fr indem die Befehle wsiml -l fr -t zugewiesen werden.
Bitte beachten Sie, dass Sie jetzt 2 Auswahlmöglichkeiten haben, wenn Sie den Servermodus verwenden. Sie können entweder den vorkompilierten Whisper.cpp -Server oder den heruntergeladenen WhisperFile (im Servermodus) auf die vorkonfigurierte Host- und Portnummer anhören. Das Orchestrator -Skript nähert sich ihnen auf die gleiche Weise.
Sprach-zu-Text-Transkription ist Speicher- und CPU-intensiver Aufgabe, und der schnelle Speicher für Lese- und Schreibzugriff kann nur helfen. Aus diesem Grund speichert WSI temporäre und Ressourcendateien im Speicher, für Geschwindigkeit und um SSD/HDD "Schleifen" zu reduzieren: TEMPD='/dev/shm' . Dieser Mountspunkt vom Typ "TMPFs" wird in RAM erstellt (nehmen wir an, dass Sie beispielsweise mindestens 8 GB haben) und wird vom Kernel für Benutzer-Raum-Anwendungen zur Verfügung gestellt. Wenn der Computer heruntergefahren wird, wird er automatisch ausgelöscht, was in Ordnung ist, da wir die Zwischendateien nicht benötigen. In der Tat wäre es für einige Arten von Anwendungen (betrachten Sie Electron), dass es vorteilhaft ist, dass der systemweite /TMP -Mountspunkt auch im RAM aufbewahrt wird. Das Verschieben /TMP zu RAM kann das Anwendungsstart ein wenig beschleunigen. Eine willkommene Beschleunigung für jede Elektronen -App. In seiner einfachsten Form ist dieser Übergang einfach, einfach rennen:
echo "tmpfs /tmp tmpfs rw,nosuid,nodev" | sudo tee -a /etc/fstab und starten Sie dann Ihren Linux -Computer neu. Aus den oben genannten Gründen, insbesondere wenn HDD das Hauptspeichermedium ist, kann man auch die von Whisper.cpp benötigten ASR -Modelldateien am selben Ort (/dev/shm) verschieben. Dies sind große Dateien, die zu Beginn einer Terminalsitzung (oder beim Systemstart) an diesen Ort übertragen werden können. Dies kann mit Ihrer .profile -Datei erfolgen, indem so etwas wie dieses darin platziert wird:
([ -f /dev/shm/ggml-base.en.bin ] || cp /path/to/your/local/whisper.cpp/models/ggml* /dev/shm/)


